Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il baliser les programmes de fidélité pour améliorer ses résultats enrichis ?
- □ Pourquoi Google abandonne-t-il 7 types de données structurées et que faut-il faire maintenant ?
- □ Faut-il maintenir les données structurées si Google arrête d'en afficher certaines ?
- 4:56 Pourquoi Google refuse-t-il de s'engager sur l'avenir des AI Overviews ?
- 6:24 Pourquoi Google n'indexe-t-il pas toutes vos pages et comment l'anticiper ?
- 8:48 Peut-on empêcher Google de nous positionner sur certains mots-clés ?
- 9:56 La qualité d'une page suffit-elle pour garantir son indexation ?
- 9:56 Combien de temps Google met-il vraiment à reconnaître les changements SEO ?
- 12:00 Comment Google découvre-t-il vraiment les URLs de votre site ?
- 15:15 Faut-il vraiment soumettre son sitemap tous les jours ?
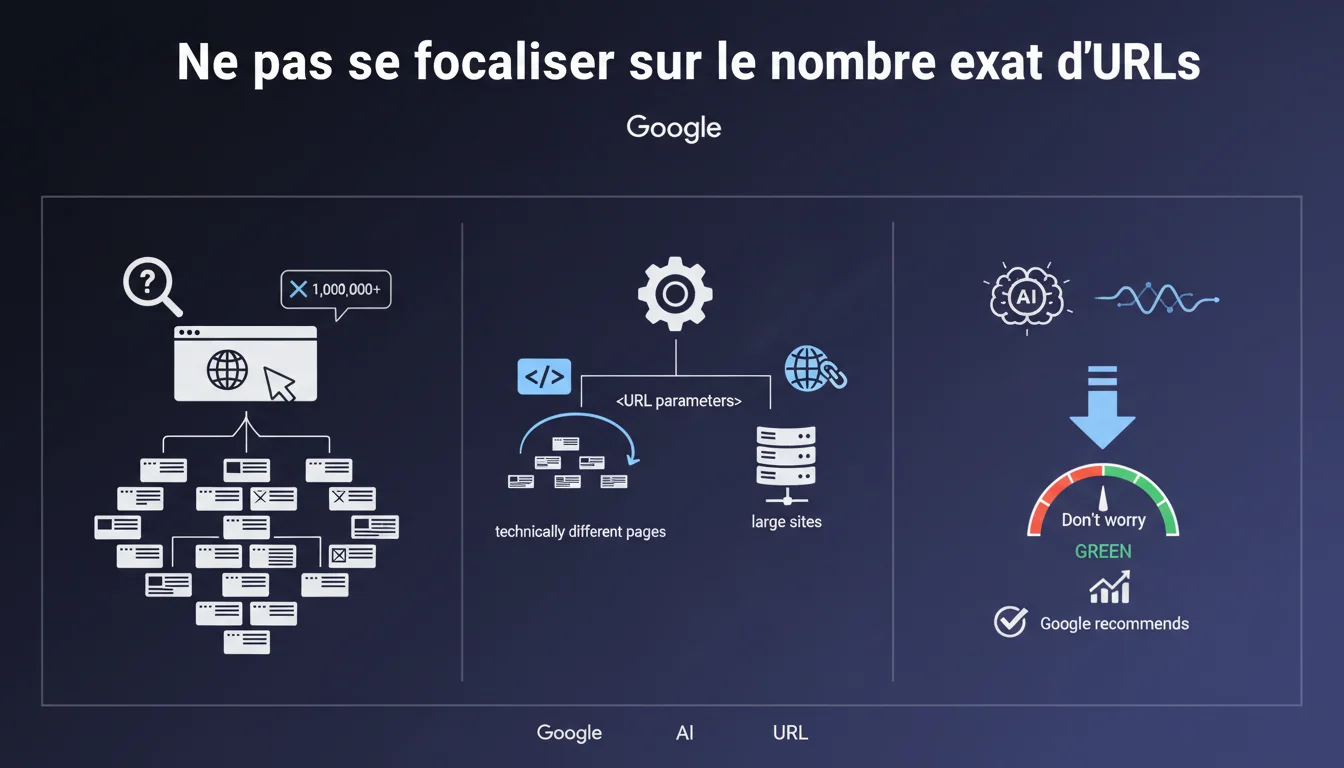
Google affirme que compter précisément les URLs d'un site de grande taille est inutile et même trompeur à cause des paramètres qui créent techniquement des pages différentes. L'essentiel n'est pas le nombre exact, mais la qualité et la structure de l'indexation. Concentrez-vous sur les pages stratégiques plutôt que sur un inventaire exhaustif.
Ce qu'il faut comprendre
Pourquoi Google déconseille-t-il de compter les URLs exactes ?
Les paramètres d'URL génèrent automatiquement des variantes techniques d'une même page : tri, filtres, sessions, UTM. Sur un site e-commerce avec 1000 produits et 5 filtres possibles, vous pouvez facilement obtenir des dizaines de milliers de combinaisons d'URLs distinctes.
Google considère que ce comptage exact est un faux problème. Ce qui importe, c'est de savoir quelles pages ont une valeur SEO réelle et lesquelles sont de simples variantes techniques sans contenu unique.
Qu'est-ce que cela révèle sur la vision de Google ?
Cette déclaration traduit une approche qualitative plutôt que quantitative. Google veut que les SEO se concentrent sur l'organisation logique du contenu, la hiérarchie des informations, et la priorisation du crawl.
Le moteur de recherche sait que les sites modernes génèrent des milliers d'URLs techniques. Il ne s'attend pas à ce que vous les maîtrisiez toutes une par une — il veut que vous contrôliez ce qui compte vraiment.
Quelles sont les implications pour le crawl budget ?
Si même Google recommande de ne pas s'obséder par le nombre exact, c'est que le crawl budget ne se gère pas en comptant les URLs mais en orientant Googlebot vers les bonnes ressources.
- Utilisez le fichier robots.txt pour bloquer les URLs paramétrées sans valeur SEO
- Définissez les URLs canoniques pour consolider les variantes techniques
- Configurez les paramètres d'URL dans Search Console pour indiquer ceux qui créent du contenu dupliqué
- Surveillez les rapports de couverture plutôt que de compter manuellement les pages
- Focalisez-vous sur l'arborescence stratégique : catégories, pages produits principales, contenus éditoriaux
Avis d'un expert SEO
Cette déclaration est-elle alignée avec les observations terrain ?
Totalement. Sur les sites de plusieurs milliers de pages, compter précisément les URLs relève de l'impossible — et surtout, c'est contre-productif. Les outils comme Screaming Frog ou OnCrawl remontent facilement 50 000 URLs sur un site qui n'en compte « officiellement » que 5 000.
Le problème, c'est que beaucoup de SEO juniors s'alarment en voyant Search Console afficher 80 000 URLs découvertes alors qu'ils pensaient en avoir 10 000. Google dit clairement : arrêtez de paniquer pour ça.
Quelles nuances faut-il apporter à ce conseil ?
Google a raison pour les sites dynamiques avec filtres, facettes, sessions. Mais attention : ne pas compter ne signifie pas ne pas cartographier. Vous devez savoir quels types d'URLs existent sur votre site, même si vous ne pouvez pas en dresser la liste exhaustive.
Autre nuance : sur un site de 200 pages statiques bien délimitées, compter les URLs reste pertinent. [A vérifier] La recommandation de Google vise clairement les sites de « grande taille », mais elle ne précise pas le seuil. À partir de combien de pages cette logique s'applique-t-elle ? 1 000 ? 10 000 ? Google reste volontairement flou.
Dans quels cas ce conseil peut-il être mal interprété ?
Certains pourraient comprendre « ne vous souciez pas du nombre d'URLs » comme un feu vert pour laisser exploser les URLs inutiles. C'est l'inverse : Google dit de ne pas compter parce qu'il veut que vous maîtrisiez la génération d'URLs à la source.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer les URLs sans les compter ?
Adoptez une logique de gouvernance des URLs plutôt qu'un inventaire exhaustif. Identifiez les typologies d'URLs générées par votre site : pages produits, filtres, tris, sessions, UTM, pages de résultats de recherche interne.
Pour chaque typologie, décidez : est-ce indexable ? Doit-on canonicaliser ? Bloquer dans robots.txt ? Exclure du sitemap XML ? Cette approche par règles vaut mieux que le comptage manuel.
Quelles erreurs éviter dans la gestion des URLs multiples ?
Ne laissez pas les paramètres de tracking (UTM, fbclid, gclid) créer des URLs indexables. Utilisez les canoniques ou configurez Search Console pour que Google ignore ces paramètres.
Évitez de bloquer massivement dans robots.txt sans réflexion : vous pourriez empêcher Google de voir les canoniques et de comprendre la structure. Mieux vaut laisser crawler et canonicaliser que de bloquer aveuglément.
Comment vérifier que la structure d'URLs est sous contrôle ?
Consultez régulièrement le rapport de couverture dans Search Console. Si vous voyez des milliers de pages « Exclues » avec la raison « Page alternative avec balise canonique appropriée », c'est bon signe : Google comprend votre structure.
Analysez les logs serveur pour repérer les URLs que Googlebot crawle le plus. Si ce sont des pages paramétrées sans valeur, c'est un signal d'alarme. Utilisez un outil comme OnCrawl ou Botify pour croiser crawl et indexation.
- Cartographiez les typologies d'URLs générées par votre CMS ou plateforme
- Définissez des règles de canonicalisation claires pour chaque typologie
- Configurez les paramètres d'URL dans Search Console si nécessaire
- Bloquez dans robots.txt uniquement les URLs sans aucune valeur SEO (admin, checkout, recherche interne non pertinente)
- Surveillez les rapports de couverture plutôt que de compter manuellement
- Analysez les logs serveur pour identifier les patterns de crawl inefficaces
- Priorisez le maillage interne vers les pages stratégiques pour orienter le crawl
❓ Questions frequentes
À partir de combien de pages doit-on arrêter de compter les URLs exactes ?
Comment savoir si mes URLs paramétrées posent problème pour le crawl ?
Dois-je bloquer toutes les URLs avec paramètres dans robots.txt ?
Les paramètres UTM créent-ils des problèmes de duplicate content ?
Le nombre d'URLs dans le sitemap XML doit-il correspondre au nombre réel de pages ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/06/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.