Official statement
Other statements from this video 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Les données structurées donnent-elles vraiment du contrôle aux webmasters sur l'affichage Google ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Faut-il implémenter des données structurées même si Google ne les utilise pas encore ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
- □ Les données structurées doivent-elles systématiquement refléter le contenu visible de la page ?
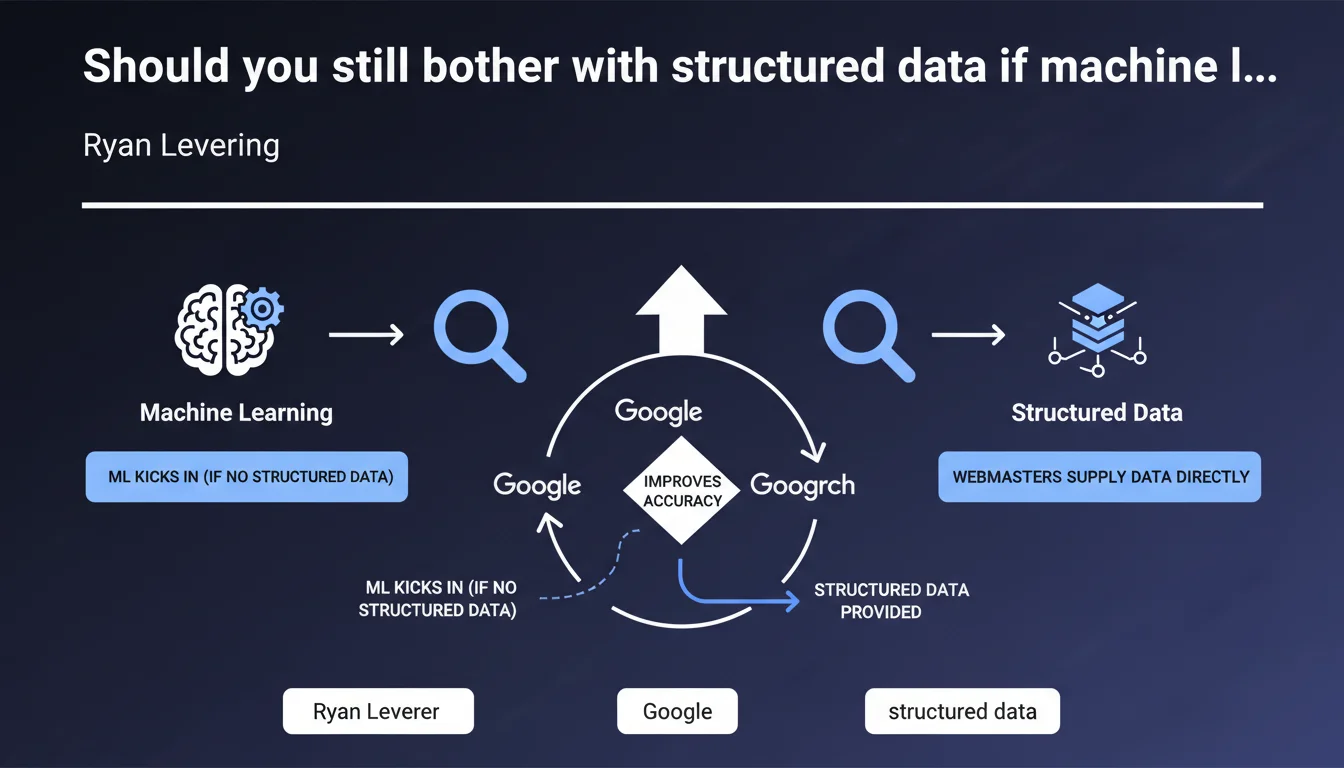
Google confirms a hybrid approach: machine learning compensates for missing structured data, but providing that data directly improves accuracy. Webmasters retain control over what Google understands about their content — as long as they structure it properly.
What you need to understand
Does Google really trust machine learning alone?
No, and that's the heart of this statement. Google uses ML as a safety net, not as the primary solution. When structured data is missing, algorithms attempt to extract information — but Ryan Levering clarifies that this automatic extraction is less reliable than explicitly provided data.
In practical terms? ML guesses, it interprets. Structured data, on the other hand, asserts. This distinction changes everything for visibility in rich snippets, Knowledge Graph, or advanced SERP features.
Why does this multi-level approach exist?
Because the web ecosystem is fundamentally heterogeneous. Millions of websites don't use any markup — Google still needs to index and understand that content. ML makes it possible to process this volume.
But for sites that play by semantic web rules, Google rewards the effort. Structured data reduces ambiguity, accelerates processing, and most importantly: it gives the webmaster control over the representation of their content.
What does "generally improves accuracy" really mean?
That "generally" deserves attention. It implies that well-implemented structured data outperforms ML, but poor implementation can introduce noise. Google doesn't guarantee that every piece of structured data will be used — it must be consistent, relevant, and aligned with visible content.
The algorithm cross-references signals: structured data + ML analysis + other indicators. If structured data contradicts what Google detects through ML, there's a conflict — and Google resolves it based on its own interpretation.
- ML compensates for the absence of structured data, but with a higher margin for error
- Webmasters retain the initiative: providing structured data = controlling the narrative
- Accuracy increases when structured data is clean and coherent with the content
- Google uses cross-validation: structured data + ML to prevent manipulation
SEO Expert opinion
Is this statement consistent with real-world observations?
Largely, yes. We've observed for years that sites with structured data perform better on rich snippets, FAQs, recipes, events, and products. A/B tests show clear CTR gains when data is properly marked up.
But — and here's where things get tricky — Google never guarantees display. Even with perfect Schema.org markup, validated by every tool available, rich snippet display remains discretionary. Google reserves the right to display nothing if "user experience" (a vague concept) doesn't warrant it. [To verify] in each vertical: some sectors see their structured data ignored without clear explanation.
Can ML really compete with explicit data?
No, and it's a technical no-brainer. Machine learning, however advanced, remains probabilistic. It makes educated guesses with a certain confidence level, but it doesn't assert anything. Structured data, on the other hand, is declarative: "This product costs X€, is in stock, has Y reviews".
The problem emerges when content is ambiguous. A poorly structured product page with multiple prices displayed (original price, promo, subscription), and ML has to choose. It sometimes gets it wrong — which is why explicitly marking the correct price via Schema.org Offer matters.
When do structured data provide no real value?
When the content is too generic or Google lacks a dedicated SERP feature for it. Example: marking a blog article with Article Schema is good — but if Google never displays an Articles carousel in your niche, the visible impact will be zero.
Another limitation: redundant structured data. If your content is already crystal clear (title, price, availability perfectly structured in semantic HTML), ML captures it all. The marginal benefit of Schema becomes minimal — but it's still a positive signal for Google, so you might as well do it.
Practical impact and recommendations
What should you actually do on your sites?
Implement priority structured data for your sector. E-commerce? Product, Offer, AggregateRating. Media? Article, NewsArticle, VideoObject. Local services? LocalBusiness, Service, Review. No need to mark everything up — target the types that unlock rich snippets in your vertical.
Use JSON-LD as your primary format — it's Google's recommended format and easier to maintain than microdata. Test with Search Console and the Rich Results Test, but don't blindly trust validators: they check syntax, not semantic relevance.
What mistakes should you absolutely avoid?
Never mark up content that's invisible to users. Google cross-references structured data with HTML content: if your Schema.org declares a price that nobody sees on the page, you risk manual action.
Avoid generic or false data. A fake AggregateRating (5 stars with 1000 invented reviews) is easily detected — and Google blacklists this type of manipulation. Better no structured data than deceptive structured data.
Don't unnecessarily duplicate. A single element marked up three times with conflicting values creates confusion. ML will detect the inconsistency and Google will ignore everything.
How do you verify your implementation is working?
Use Search Console to track structured data errors. Look in the "Enhancements" section — it lists detected types and any issues (missing fields, invalid values).
But be warned: Search Console validation doesn't guarantee SERP display. Monitor your rankings and CTR after implementation. If structured data is active but showing no impact, either Google is ignoring it or there's no rich format for your query.
- Identify structured data types relevant to your sector
- Implement in JSON-LD to facilitate maintenance
- Validate via Search Console and Rich Results Test
- Verify consistency between structured data and visible content
- Monitor impact on CTR and SERP display with tracking tools
- Quickly correct errors flagged in Search Console
- Never mark up invisible or misleading content
❓ Frequently Asked Questions
Google affiche-t-il toujours les structured data correctement balisées ?
Le machine learning peut-il extraire des données aussi précises que les structured data ?
Faut-il baliser tous les types Schema.org disponibles ?
Peut-on être pénalisé pour des structured data erronées ?
Les microdatas valent-elles encore le coup versus JSON-LD ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 07/04/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.