Official statement
Other statements from this video 12 ▾
- □ E-A-T n'est-il vraiment pas un facteur de classement Google ?
- □ Pourquoi Google refuse-t-il de dévoiler la recette complète de son algorithme ?
- □ Faut-il adopter une démarche expérimentale pour optimiser son référencement naturel ?
- □ Faut-il avouer qu'on ne sait pas tout en SEO ?
- □ Faut-il vraiment éliminer toutes les chaînes de redirections pour préserver son crawl budget ?
- □ La matrice impact/effort est-elle vraiment la clé pour prioriser vos tâches SEO ?
- □ Faut-il imposer des solutions techniques aux développeurs ou simplement exposer les problèmes SEO ?
- □ Faut-il vraiment distinguer les redirections 301 et 302 pour le SEO ?
- □ Pourquoi développer du contenu invisible dans les moteurs de recherche revient-il à travailler pour rien ?
- □ Google déploie-t-il vraiment des mises à jour algorithme chaque minute ?
- □ Faut-il vraiment intégrer le SEO dès la phase de développement pour éviter les corrections coûteuses ?
- □ Les pages SEO sans valeur utilisateur peuvent-elles encore se classer dans Google ?
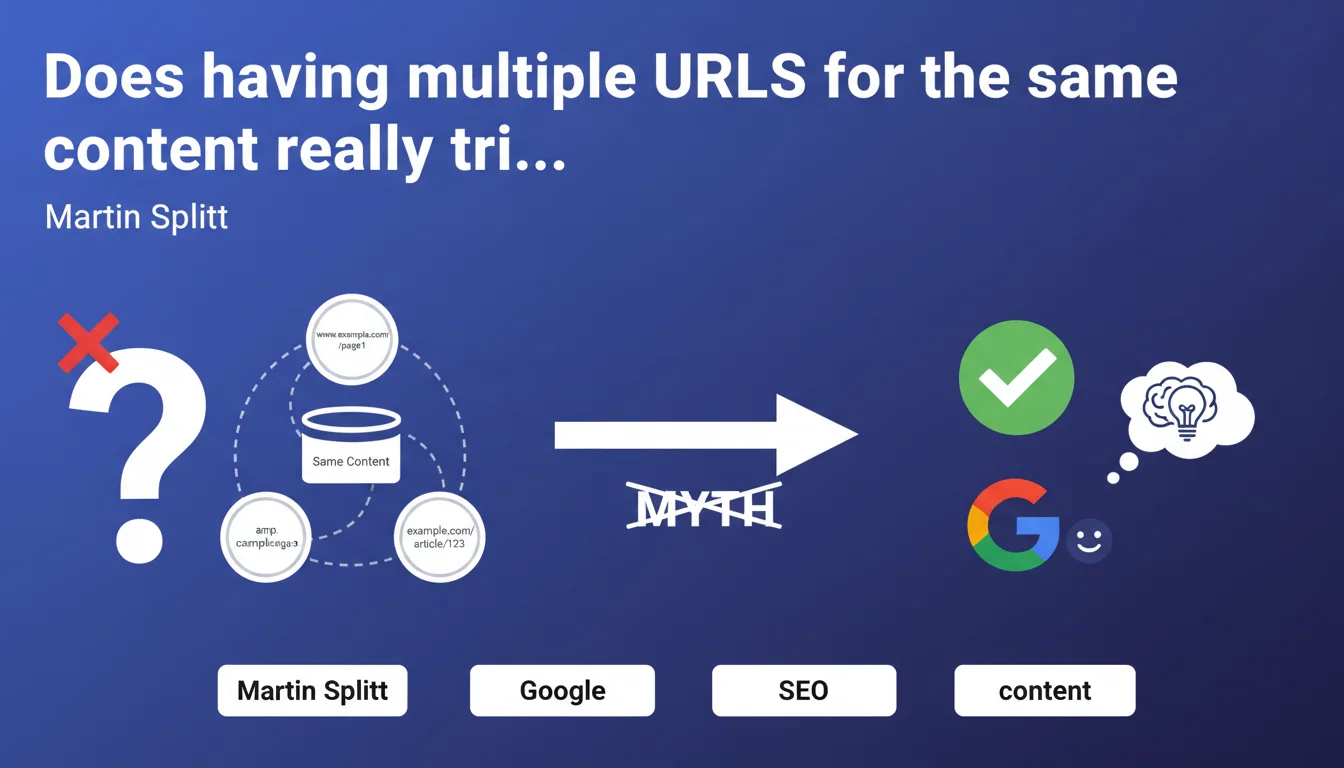
Martin Splitt debunks the misconception: having multiple URLs pointing to the same content triggers no Google penalty. It's a persistent myth that SEO professionals should abandon. Google handles these duplicates through canonicalization, without penalizing the site.
What you need to understand
Why does this belief persist among SEO professionals?
The idea that having multiple URLs for the same content attracts an algorithmic penalty is deeply rooted in collective SEO imagination for years. It's based on a confusion between two concepts: content duplication (which exists) and penalty for duplication (which doesn't exist in this form).
Google has always been clear—at least in its official communications: the same content accessible through multiple URLs is not a problem in itself. The search engine simply chooses which version to index and display in search results. No sanction, no punitive filter. Just an algorithmic choice.
How does Google concretely handle these multiple URLs?
When Google detects multiple URLs serving the same content, it applies a canonicalization process. The algorithm selects a "canonical" URL—the one it deems most relevant—and consolidates ranking signals (backlinks, authority, etc.) on this version.
The other URLs may remain indexed or not, but they generally don't benefit from the same weight in results. This isn't a penalty: it's a technical normalization to avoid polluting the index with unnecessary duplicates.
What are the real risks then?
If Google doesn't penalize, that doesn't mean everything is fine. Multiple URLs fragment ranking signals: backlinks scatter, crawl budget dilutes, and Google may choose a canonical URL that isn't the one you want to promote.
Concretely? You lose SEO efficiency. Not because of a penalty, but because your resources—crawl, authority, link equity—are wasted on redundant versions.
- No algorithmic penalty for having multiple URLs on the same content
- Google applies automatic canonicalization to choose the version to display
- The real problem: dilution of ranking signals and loss of control over the promoted URL
- Proactive management of canonicals remains essential to maximize SEO performance
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes—and no. Martin Splitt is right on substance: there is no punitive filter specifically designed to penalize URL duplication. Field tests confirm it: a site with multiple URLs doesn't suffer the sudden visibility drop we'd observe with a manual penalty or an algorithmic filter like Panda.
Now, let's be honest: saying "no penalty" doesn't mean "no negative impact." Sites that leave unmanaged duplicates lying around see their SEO performance degrade. Google doesn't punish them—it partially ignores them, which amounts to the same result in terms of visibility.
What nuances must we add to this reassuring message?
Splitt's statement is technically correct, but it obscures practical complexity. Google "manages" duplicates, certainly—but not always as you'd wish. The algorithm may choose a canonical URL different from the one you specified via the canonical tag, especially if your internal signals are contradictory.
And then there's crawl budget. On a large e-commerce or media site, thousands of redundant URLs drain resources that Googlebot could use to discover strategic content. No penalty, agreed—but pure waste nonetheless. [To verify]: the real impact of crawl budget remains difficult to quantify precisely for the majority of sites.
In which cases does this rule not apply?
There's a gray area: outright spam. If you massively generate quasi-identical URLs for manipulation purposes (doorway pages, cloaking, etc.), then yes, you risk manual action. But that's no longer a question of "multiple URLs for the same content"—it's a question of fraudulent intent.
Another borderline case: sites that serve dynamically different content depending on URL parameters while claiming it's the same content. Google can interpret this as cloaking or deception, especially if behavior differs between Googlebot and users.
Practical impact and recommendations
What should you concretely do to manage these multiple URLs?
First step: audit your site to identify all URLs serving the same content. Classic tools: Screaming Frog, Sitebulb, or directly Search Console to spot indexed duplicates. Also look at URL parameters (filters, sessions, tracking) that create unnecessary versions.
Once you've done the audit, three main levers: canonical tags, 301 redirects, and URL parameter management via Search Console or robots.txt. Each lever has its purpose: canonical for legitimate variants (printable versions, AMP, etc.), 301 to permanently remove obsolete URLs.
- Audit duplicate URLs using an SEO crawler and Search Console
- Define which URL should be the official canonical version for each piece of content
- Implement
rel="canonical"tags consistently across all variants - 301 redirect obsolete or unnecessary URLs to the canonical version
- Use URL parameters in Search Console to flag non-significant parameters
- Ensure internal linking systematically points to canonical URLs
- Regularly monitor coverage reports in Search Console to detect new duplicates
What mistakes must you absolutely avoid?
Classic mistake: canonical tag pointing to a URL that redirects. Google may interpret this as a contradictory signal and ignore your canonical. Another trap: specifying a canonical on page A to page B, but doing the reverse on page B. Consistency or nothing.
Also avoid blocking duplicate URLs via robots.txt while keeping them accessible and indexable. Google can't read the canonical tag if you block crawling—result: total confusion. If you want to deindex, use the noindex tag, not robots blocking.
How do you verify that your canonical management works?
Search Console is your friend: the coverage report shows excluded URLs with the note "Duplicate, user-specified canonical URL is different." If Google respects your canonicals, you should see this note on variants. If not, dig deeper: contradictory internal signals, massive backlinks on the wrong version, etc.
Also test with the URL inspection tool: enter a duplicate URL and verify which version Google considers canonical. If it doesn't match your intention, it means your signals aren't clear enough.
Properly managing multiple URLs requires technical and strategic vision: rigorous auditing, coherent canonical implementation, controlled redirects, and continuous monitoring. These optimizations can quickly become complex on medium or large sites, especially with inflexible CMS platforms or heavy technical legacies.
If you lack internal resources or the situation becomes unmanageable, engaging a specialized SEO agency can save you valuable time and prevent costly mistakes. Personalized support allows you to structure an action plan tailored to your architecture and business priorities.
❓ Frequently Asked Questions
Faut-il systématiquement rediriger en 301 toutes les URLs dupliquées ?
Google peut-il ignorer ma balise canonical et choisir une autre URL ?
Les paramètres d'URL type ?utm_source créent-ils des doublons problématiques ?
Combien de temps faut-il pour que Google prenne en compte une nouvelle balise canonical ?
Est-ce grave si plusieurs URLs dupliquées sont indexées temporairement ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 26/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.