Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ E-A-T n'est-il vraiment pas un facteur de classement Google ?
- □ Pourquoi Google refuse-t-il de dévoiler la recette complète de son algorithme ?
- □ Faut-il adopter une démarche expérimentale pour optimiser son référencement naturel ?
- □ Faut-il avouer qu'on ne sait pas tout en SEO ?
- □ Faut-il vraiment éliminer toutes les chaînes de redirections pour préserver son crawl budget ?
- □ La matrice impact/effort est-elle vraiment la clé pour prioriser vos tâches SEO ?
- □ Faut-il imposer des solutions techniques aux développeurs ou simplement exposer les problèmes SEO ?
- □ Faut-il vraiment distinguer les redirections 301 et 302 pour le SEO ?
- □ Pourquoi développer du contenu invisible dans les moteurs de recherche revient-il à travailler pour rien ?
- □ Google déploie-t-il vraiment des mises à jour algorithme chaque minute ?
- □ Faut-il vraiment intégrer le SEO dès la phase de développement pour éviter les corrections coûteuses ?
- □ Les pages SEO sans valeur utilisateur peuvent-elles encore se classer dans Google ?
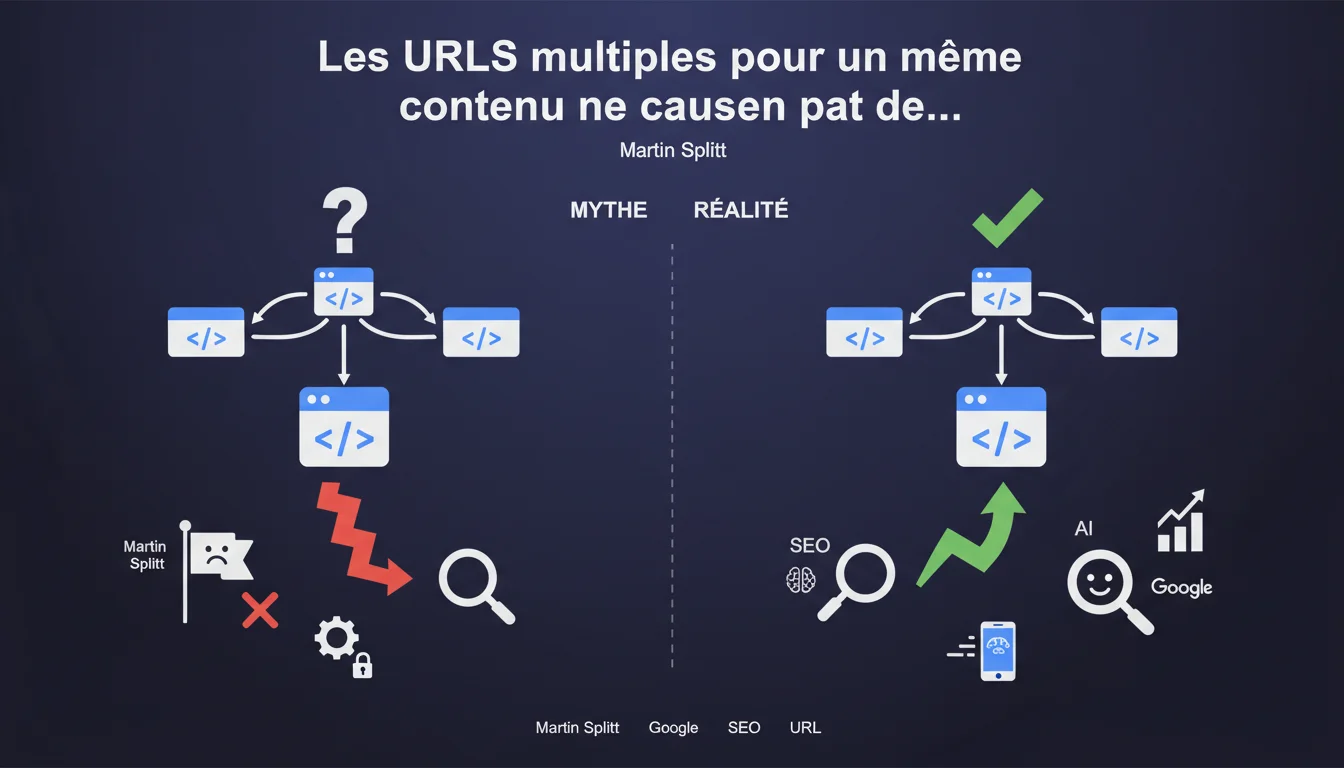
Martin Splitt balaie l'idée reçue : avoir plusieurs URLs pointant vers le même contenu ne déclenche aucune pénalité Google. C'est un mythe tenace que les SEO devraient abandonner. Google gère ces doublons via la canonicalisation, sans sanctionner le site.
Ce qu'il faut comprendre
Pourquoi cette croyance persiste-t-elle chez les SEO ?
L'idée qu'avoir plusieurs URLs pour un même contenu attire une pénalité algorithmique est ancrée dans l'imaginaire collectif SEO depuis des années. Elle repose sur une confusion entre deux concepts : la duplication de contenu (qui existe) et la pénalité pour duplication (qui n'existe pas sous cette forme).
Google a toujours été clair — du moins dans ses communications officielles : un même contenu accessible via plusieurs URLs n'est pas un problème en soi. Le moteur choisit simplement quelle version indexer et afficher dans les résultats. Pas de sanction, pas de filtre punitif. Juste un choix algorithmique.
Comment Google traite-t-il concrètement ces URLs multiples ?
Quand Google détecte plusieurs URLs servant le même contenu, il applique un processus de canonicalisation. L'algorithme sélectionne une URL « canonique » — celle qu'il juge la plus pertinente — et consolide les signaux de ranking (backlinks, autorité, etc.) sur cette version.
Les autres URLs peuvent rester indexées ou non, mais elles ne bénéficient généralement pas du même poids dans les résultats. Ce n'est pas une pénalité : c'est une normalisation technique pour éviter de polluer l'index avec des doublons inutiles.
Quels sont les vrais risques alors ?
Si Google ne pénalise pas, ça ne veut pas dire que tout va bien pour autant. Les URLs multiples fragmentent les signaux de ranking : les backlinks se dispersent, le crawl budget se dilue, et Google peut choisir une URL canonique qui n'est pas celle que vous souhaitez mettre en avant.
Concrètement ? Vous perdez en efficacité SEO. Pas à cause d'une pénalité, mais parce que vos ressources — crawl, autorité, équité des liens — sont gaspillées sur des versions redondantes.
- Pas de pénalité algorithmique pour avoir plusieurs URLs sur le même contenu
- Google applique une canonicalisation automatique pour choisir la version à afficher
- Le vrai problème : dilution des signaux de ranking et perte de contrôle sur l'URL mise en avant
- La gestion proactive des canoniques reste indispensable pour maximiser la performance SEO
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui — et non. Martin Splitt a raison sur le fond : il n'y a pas de filtre punitif spécifiquement dédié à sanctionner la duplication d'URLs. Les tests terrain le confirment : un site avec des URLs multiples ne subit pas de chute brutale de visibilité comme on l'observerait avec une pénalité manuelle ou un filtre algorithmique type Panda.
Maintenant, soyons honnêtes : dire « pas de pénalité » ne veut pas dire « aucun impact négatif ». Les sites qui laissent traîner des doublons non gérés voient leurs performances SEO se dégrader. Google ne les punit pas — il les ignore en partie, ce qui revient au même résultat en termes de visibilité.
Quelles nuances faut-il apporter à ce discours rassurant ?
La déclaration de Splitt est techniquement correcte, mais elle occulte la complexité pratique. Google « gère » les doublons, certes — mais pas toujours comme vous le souhaiteriez. L'algorithme peut choisir une URL canonique différente de celle que vous avez spécifiée via la balise canonical, surtout si vos signaux internes sont contradictoires.
Et puis il y a le crawl budget. Sur un gros site e-commerce ou média, des milliers d'URLs redondantes pompent des ressources que Googlebot pourrait utiliser pour découvrir du contenu stratégique. Pas de pénalité, d'accord — mais un gaspillage pur et simple. [À vérifier] : l'impact réel du crawl budget reste difficile à quantifier précisément pour la majorité des sites.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Il y a une zone grise : le spam pur et dur. Si vous générez massivement des URLs quasi-identiques dans une logique de manipulation (doorway pages, cloaking, etc.), là oui, vous risquez une action manuelle. Mais ce n'est plus une question de « plusieurs URLs pour un même contenu » — c'est une question d'intention frauduleuse.
Autre cas limite : les sites qui servent du contenu dynamiquement différent selon les paramètres d'URL tout en prétendant que c'est le même contenu. Google peut interpréter ça comme du cloaking ou de la tromperie, surtout si le comportement diffère entre Googlebot et les utilisateurs.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer ces URLs multiples ?
Première étape : auditer votre site pour identifier toutes les URLs servant le même contenu. Outils classiques : Screaming Frog, Sitebulb, ou directement Search Console pour repérer les doublons indexés. Regardez aussi les paramètres d'URL (filtres, sessions, tracking) qui créent des versions inutiles.
Une fois l'audit fait, trois leviers principaux : les balises canonical, les redirections 301, et la gestion des paramètres via Search Console ou le fichier robots.txt. Chaque levier a son usage : canonical pour les variantes légitimes (versions imprimables, AMP, etc.), 301 pour supprimer définitivement des URLs obsolètes.
- Auditer les URLs dupliquées via un crawler SEO et Search Console
- Définir quelle URL doit être la version canonique officielle pour chaque contenu
- Implémenter les balises
rel="canonical"de manière cohérente sur toutes les variantes - Rediriger en 301 les URLs obsolètes ou inutiles vers la version canonique
- Utiliser les paramètres d'URL dans Search Console pour signaler les paramètres non significatifs
- Vérifier que le maillage interne pointe systématiquement vers les URLs canoniques
- Monitorer régulièrement les rapports de couverture dans Search Console pour détecter de nouveaux doublons
Quelles erreurs éviter absolument ?
Erreur classique : balise canonical pointant vers une URL qui redirige. Google peut interpréter ça comme un signal contradictoire et ignorer votre canonical. Autre piège : spécifier une canonical sur la page A vers la page B, mais faire l'inverse sur la page B. Cohérence ou rien.
Évitez aussi de bloquer les URLs dupliquées via robots.txt tout en les laissant accessibles et indexables. Google ne peut pas lire la balise canonical si vous bloquez le crawl — résultat : confusion totale. Si vous voulez désindexer, utilisez la balise noindex, pas le blocage robots.
Comment vérifier que votre gestion des canoniques fonctionne ?
Search Console est votre ami : le rapport de couverture montre les URLs exclues avec la mention « Dupliquée, URL canonique choisie par l'utilisateur différente ». Si Google respecte vos canoniques, vous devriez voir cette mention sur les variantes. Si ce n'est pas le cas, creusez : signaux internes contradictoires, backlinks massifs sur la mauvaise version, etc.
Testez aussi avec l'outil d'inspection d'URL : saisissez une URL dupliquée et vérifiez quelle version Google considère comme canonique. Si ça ne correspond pas à votre intention, c'est que vos signaux ne sont pas assez clairs.
Gérer proprement les URLs multiples demande une vision technique et stratégique : audit rigoureux, implémentation cohérente des canoniques, redirections maîtrisées, et monitoring continu. Ces optimisations peuvent vite devenir complexes sur des sites de taille moyenne ou grande, surtout avec des CMS peu flexibles ou des historiques techniques lourds.
Si vous manquez de ressources internes ou que la situation devient ingérable, faire appel à une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des erreurs coûteuses. Un accompagnement personnalisé permet de structurer un plan d'action adapté à votre architecture et à vos priorités business.
❓ Questions frequentes
Faut-il systématiquement rediriger en 301 toutes les URLs dupliquées ?
Google peut-il ignorer ma balise canonical et choisir une autre URL ?
Les paramètres d'URL type ?utm_source créent-ils des doublons problématiques ?
Combien de temps faut-il pour que Google prenne en compte une nouvelle balise canonical ?
Est-ce grave si plusieurs URLs dupliquées sont indexées temporairement ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.