Official statement
Other statements from this video 9 ▾
- □ Pourquoi Google supprime-t-il 7% de son index vidéo et comment éviter d'en faire partie ?
- □ Pourquoi les incidents d'indexation paralysent-ils autant les sites d'actualités ?
- □ Pourquoi Google laisse-t-il des incidents 'ouverts' sur son tableau de bord même après résolution ?
- □ Faut-il s'inquiéter des incidents techniques mineurs chez Google ?
- □ Comment Google décide-t-il de communiquer publiquement sur un incident technique ?
- □ Pourquoi Google utilise-t-il des messages pré-approuvés lors d'incidents techniques ?
- □ Pourquoi votre contenu n'apparaît-il pas dans les SERP malgré la résolution de votre incident d'indexation ?
- □ Pourquoi les expériences de Google provoquent-elles des incidents dans les résultats de recherche ?
- □ Google va-t-il enfin communiquer sur les bonnes nouvelles de son moteur ?
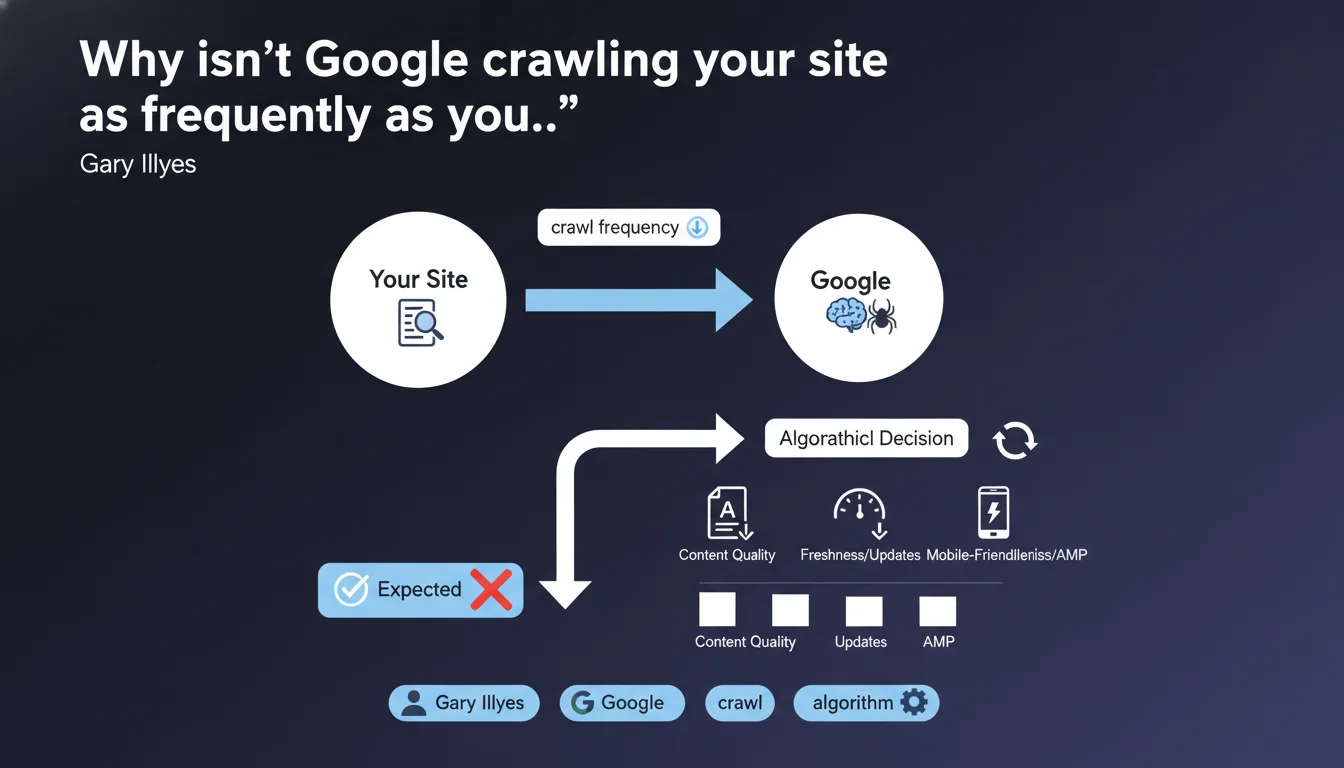
Google openly acknowledges that certain crawl behaviors deemed problematic by site owners are actually intentional algorithmic decisions. If your site isn't being crawled as frequently as you hoped, it's not a technical malfunction but an evaluation of your content's relevance and value by the algorithm. This stance underscores that Google optimizes its crawl budget according to its own criteria, not webmaster expectations.
What you need to understand
Does Google really distinguish between bugs and algorithmic choices?
Gary Illyes' statement introduces an essential nuance: what looks like a technical problem isn't always one. Many SEO professionals diagnose "bugs" when Googlebot's behavior doesn't match their expectations. Let's be honest — we've all complained about a crawl budget that seemed insufficient.
Google claims these situations often stem from deliberate algorithmic decisions. The search engine continuously evaluates content value and adjusts crawl frequency accordingly. If your site receives few bot visits, it's potentially a signal that Google considers your content less of a priority than others.
What criteria influence this algorithmic evaluation?
Google obviously doesn't reveal its entire formula. What we know: content freshness, domain authority, perceived quality, and popularity play major roles. A site that publishes rarely, with few backlinks and low traffic, will logically be crawled less frequently than a high-authority news outlet.
The problem — and this is where it gets tricky — is that Google doesn't provide precise thresholds. You never know if you're just below the radar or if your site is considered outright negligible. This opacity makes it difficult to distinguish between a real quality issue and a simple algorithmic fluctuation.
Does this logic apply to all types of sites?
No, and this is a crucial point. E-commerce sites with thousands of product pages, content aggregators, and news sites experience this reality differently. For a 20-page corporate site, crawl frequency matters little. For a media outlet publishing 50 articles daily, every hour of indexing delay can represent lost revenue.
Sites whose content changes frequently — prices, inventory, news — are particularly exposed. Google adjusts crawl based on perceived velocity of change, but this perception isn't always synchronized with on-the-ground reality.
- Crawl frequency is a consequence, not a direct lever you control
- Google optimizes its own crawl budget, not yours according to your business objectives
- What appears to be a bug may be an intentional algorithmic deprioritization
- The opacity of criteria makes diagnosis difficult — impossible to know if it's a quality issue or a priority issue
- Sites with high volumes of fresh content are most impacted by this logic
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes and no. In principle, it's undeniable: Google has no obligation to crawl your site according to your wishes. The search engine manages billions of pages and must prioritize. The algorithmic approach is rational from Google's perspective, but it completely ignores the operational reality of sites.
Concretely? I've seen perfectly optimized sites with fresh daily content waiting several days before a strategic page gets indexed. In those cases, it's hard not to call it a malfunction — even if Google considers everything functioning "as intended." [To verify]: the boundary between "algorithmic decision" and "bug" remains fuzzy, and Google provides no way to differentiate the two.
What nuances should be added to this claim?
Gary Illyes oversimplifies. There are genuine proven crawl bugs — server errors, redirect loops, JavaScript rendering issues poorly handled. These situations aren't about "content evaluation" but real technical failures that Google needs to fix.
Lumping both together under "it's not a bug, it's a feature" is convenient for Google, less so for us. It allows them to dismiss legitimate complaints by invoking algorithmic opacity. Let's be clear: if your site loses 80% of its crawl overnight without technical changes, that's not just a "reevaluation".
Furthermore, this position says nothing about observed inconsistencies. Why does a competitor site with objectively weaker content get twice the crawl? Google will say "algorithm," but that doesn't make the situation any less frustrating or comprehensible.
In what cases does this rule not apply?
When you have technical proof of a malfunction: repeated 5xx errors on Google's end, pages rendered empty when they display correctly, crawl blocked by a robots.txt you never configured. In these situations, invoking "algorithmic evaluation" is dodging the issue.
Similarly, if you notice a sudden change with no modification on your end — unannounced algorithm update, Google bug — it's legitimate to call it a problem, not a "feature." Gary Illyes' statement shouldn't serve as a universal excuse to passively accept real warning signals.
Practical impact and recommendations
What should you do concretely to maximize your crawl budget?
First step: audit your server logs to identify real crawl patterns. Is Googlebot visiting unnecessary pages? Duplicate URLs, e-commerce filter facets, infinite pagination pages? Each page crawled unnecessarily consumes budget that could go toward your strategic content.
Next, optimize your architecture. Reduce the depth of important pages, improve internal linking, eliminate redirect chains. The faster your critical pages are accessible, the more frequently Google will visit them. And this is where it gets complicated — because modifying a 10,000-page site's architecture without breaking something requires solid expertise.
Finally, publish regularly with quality content. Google adjusts crawl based on perceived update velocity. A site publishing daily will be crawled more often than a static site. But be careful — publishing for publishing's sake helps nothing. Content must add value, or you risk the opposite effect: deprioritization.
What mistakes should you avoid to not worsen the situation?
Never block essential resources in robots.txt thinking you'll "save" crawl budget. Google needs to access CSS and JavaScript to properly evaluate your pages. Blocking these resources can cause incomplete rendering and, paradoxically, reduce your crawl even further.
Also avoid over-optimizing at the expense of user experience. I've seen sites remove useful pages to "concentrate" crawl budget, when those pages were generating traffic. Crawl budget isn't an end in itself — it serves to index pages that add value, not to maximize a KPI disconnected from business reality.
Finally, don't fall into the over-indexation trap. Frantically submitting URLs via Search Console or sitemaps won't make Google crawl faster if the algorithm has decided your site isn't a priority. You might even be perceived as spam.
How can you verify your site is being correctly evaluated by Google?
Compare your observed crawl frequency in logs with your publishing frequency. If you publish daily but Google only visits weekly, there's a problem — either technical or quality-related. Cross-reference this data with Search Console stats in the "Exploration Statistics" section.
Also analyze the pages actually crawled versus strategic pages. If Googlebot spends 70% of its time on valueless SEO pages (archives, tags, facets) and 30% on your pillar content, you have an architecture problem to fix. Log analysis tools like Screaming Frog Log Analyzer or OnCrawl are invaluable here.
Finally, monitor evolution over time. A gradual crawl decline may indicate algorithmic deprioritization — often linked to perceived quality loss or declining popularity. A sudden drop suggests a technical issue or penalty instead.
- Audit your server logs to identify unnecessarily crawled pages
- Optimize architecture to reduce strategic page depth
- Improve internal linking to guide Googlebot toward priority content
- Publish regularly with quality content to increase perceived velocity
- Never block essential CSS/JS from rendering in robots.txt
- Compare actual crawl frequency to publishing frequency to spot gaps
- Analyze which pages consume your crawl budget — eliminate waste
- Monitor long-term trends in Search Console
❓ Frequently Asked Questions
Comment savoir si la faible fréquence de crawl de mon site est un bug ou une décision algorithmique ?
Peut-on forcer Google à crawler son site plus souvent ?
Pourquoi un site concurrent est-il crawlé plus souvent que le mien avec un contenu similaire ?
Un crawl budget faible impacte-t-il nécessairement mon SEO ?
Google peut-il se tromper dans son évaluation algorithmique du contenu ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 06/06/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.