Official statement
Other statements from this video 10 ▾
- □ Pourquoi robots.txt suffit-il (presque toujours) à bloquer l'indexation d'un site de staging ?
- □ La protection par mot de passe est-elle vraiment la solution pour bloquer l'indexation d'un site de staging ?
- □ La balise no-index bloque-t-elle vraiment toute indexation sans exception ?
- □ Les pages orphelines sont-elles vraiment invisibles pour Google ?
- □ Google peut-il vraiment découvrir tous vos sous-domaines ?
- □ Faut-il vraiment soumettre manuellement ses pages importantes au lancement d'un site ?
- □ Faut-il vraiment craindre de publier 7000 articles d'un coup ?
- □ Un nom de domaine propre améliore-t-il vraiment la mémorisation de votre marque ?
- □ Les listes blanches IP suffisent-elles vraiment à protéger vos sites de staging du crawl Google ?
- □ Faut-il vraiment faire du SEO pour un site à fonctionnalité ?
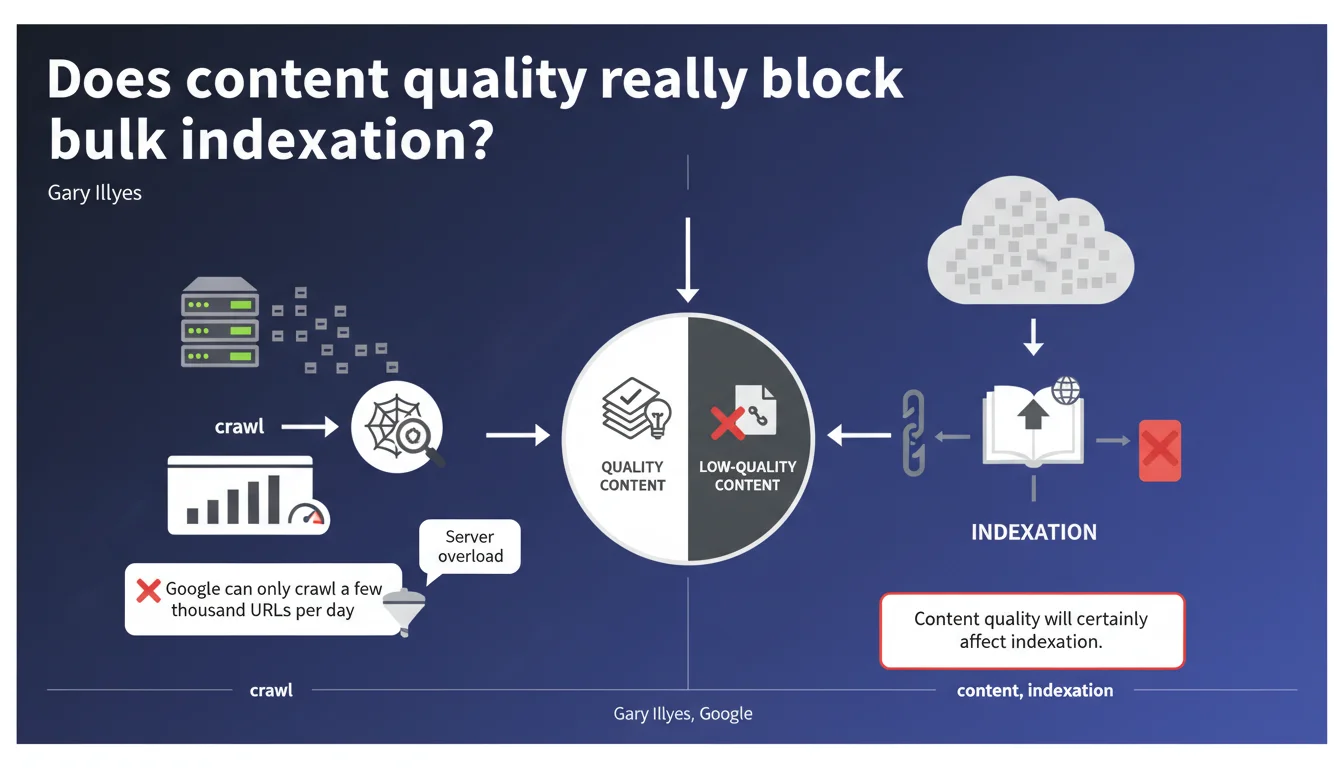
Google rarely indexes a million pages at once, even if crawling is technically possible. Content quality becomes a determining filter to decide which pages deserve to enter the index. Crawl budget is only part of the problem — it's the perceived value of the content that dictates large-scale indexation.
What you need to understand
Why does Google limit bulk indexation even if crawling is technically feasible?
Crawl budget — that daily quota of a few thousand URLs that Googlebot can visit without overloading a server — is just a technical safeguard. If your infrastructure can handle the load, Google could technically crawl more. But that's not the real bottleneck.
The real limit is content quality. When a site tries to get a million pages indexed simultaneously, Google activates strict relevance filters. Indexation becomes selective: only pages deemed useful and original will pass. The rest? Crawled, but never added to the index.
What does this change for a site with thousands of pages?
Concretely, if you launch an e-commerce site with 500,000 auto-generated product pages, Google won't index everything. It will sample, evaluate duplication, added value, thematic relevance. If 80% of pages are similar or provide nothing, they'll stay out of the index.
This statement confirms what many observe in practice: indexation is no longer a right, it's a privilege earned through quality. Sites that dilute their content with weak pages pay a steep price.
What are the key takeaways from this statement?
- Crawl budget still exists, but it's only a secondary technical constraint compared to content quality.
- Google can crawl a few thousand URLs per day without overloading a server — but this in no way guarantees their indexation.
- Bulk indexation requires high-value content, original and non-redundant.
- Sites that try to artificially inflate their page volume with weak or duplicated content will be filtered severely.
- Strategy should prioritize qualitative density rather than raw volume of indexable pages.
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes — and it confirms what we've seen since the Helpful Content updates and massive deindexation waves. Google has tightened its indexation criteria. Sites with hundreds of thousands of pages now see 40 to 60% of their content excluded from the index, even though these pages are technically crawled.
But let's be honest: Google remains vague about what precisely defines "quality" in this context. Is it freshness? Textual originality? Semantic depth? UX relevance? [To verify] — no quantified metrics are given.
What nuances should be added to this assertion?
Crawl budget isn't uniform. An established authority site with strong internal PageRank and solid trust signals can see Google crawl far more than "a few thousand URLs per day". Conversely, a new site without backlinks or history will be throttled, even if its content is excellent.
And that's where it gets tricky: quality alone isn't enough if Google doesn't allocate enough crawl to discover that content. There's a threshold effect — below a certain visibility level, even the best pages remain invisible for lack of being explored.
In what cases doesn't this rule fully apply?
News sites and structured data aggregators sometimes benefit from rapid and massive indexation, even with millions of pages. Why? Because Google has specific pipelines for high-velocity temporal content (news, events, real-time prices).
Similarly, sites with flawless technical architecture — segmented XML sitemap, instant rendering, excellent Core Web Vitals signals — can partly compensate for moderately differentiated content. But it's marginal. Quality remains the dominant filter.
Practical impact and recommendations
What should you do concretely to maximize bulk indexation?
First priority: ruthlessly audit the quality of each content segment. Identify pages that add no unique value — empty product sheets, redundant categories, auto-generated content without enrichment. Delete them or merge them.
Next, focus your crawl budget on your strategic pages. Use your robots.txt file to block unnecessary URLs (filters, sorts, sessions), optimize your internal linking to push priority pages, and segment your XML sitemaps by actual priority level.
What mistakes should you absolutely avoid with large page volumes?
Never attempt to index a million pages at once without validating their semantic differentiation. Google will sample, and if your first 100 crawled pages are mediocre, it will extrapolate and ignore the rest.
Also avoid relying solely on technical optimization — an ultra-fast site with weak content will be crawled efficiently, then ignored at indexation. Speed doesn't compensate for editorial emptiness.
How do you verify your indexation strategy is working?
- Check your actual indexation rate in Google Search Console (Indexed pages / Submitted pages) — a ratio below 60% signals a quality issue.
- Analyze the exclusion reasons in GSC: "Discovered, currently not indexed" or "Crawled, currently not indexed" indicate Google judges your content insufficient.
- Segment your pages by type and compare their indexation rates — identify segments systematically rejected.
- Monitor the evolution of daily crawl budget in your crawl stats reports — a sudden drop often signals a trust decline.
- Test manual indexation via the URL inspection tool on a representative sample — if Google refuses to index manually, quality is the issue.
- Compare your internal PageRank (via Screaming Frog or OnCrawl) with actually indexed pages — pages with low internal PR are often ignored.
❓ Frequently Asked Questions
Le crawl budget est-il le principal obstacle à l'indexation de masse ?
Comment Google évalue-t-il la qualité du contenu pour l'indexation de masse ?
Un site peut-il forcer l'indexation de toutes ses pages avec un meilleur crawl budget ?
Faut-il supprimer les pages non indexées pour améliorer le taux global ?
Les sitemaps XML aident-ils à indexer des millions de pages plus rapidement ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 05/04/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.