Official statement
Other statements from this video 10 ▾
- □ La protection par mot de passe est-elle vraiment la solution pour bloquer l'indexation d'un site de staging ?
- □ La balise no-index bloque-t-elle vraiment toute indexation sans exception ?
- □ Les pages orphelines sont-elles vraiment invisibles pour Google ?
- □ Google peut-il vraiment découvrir tous vos sous-domaines ?
- □ Faut-il vraiment soumettre manuellement ses pages importantes au lancement d'un site ?
- □ Faut-il vraiment craindre de publier 7000 articles d'un coup ?
- □ La qualité du contenu bloque-t-elle réellement l'indexation de masse ?
- □ Un nom de domaine propre améliore-t-il vraiment la mémorisation de votre marque ?
- □ Les listes blanches IP suffisent-elles vraiment à protéger vos sites de staging du crawl Google ?
- □ Faut-il vraiment faire du SEO pour un site à fonctionnalité ?
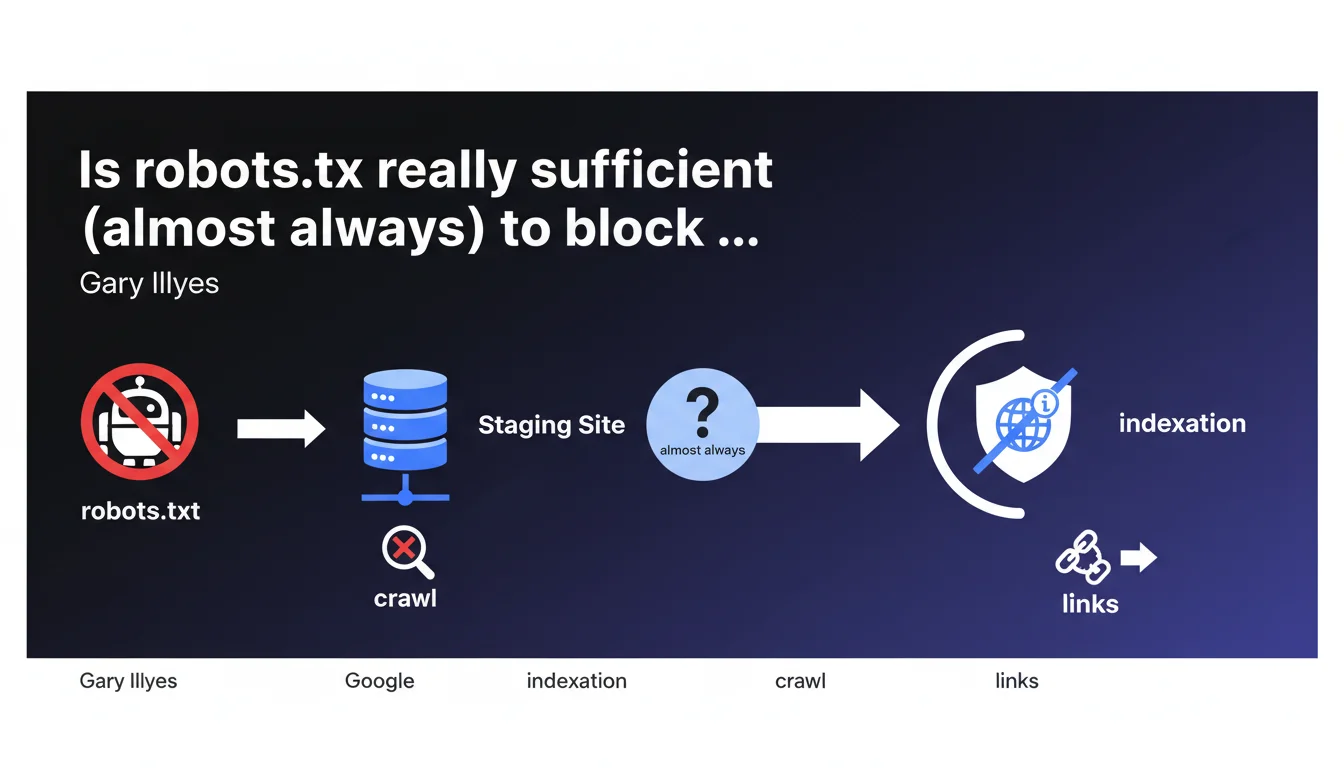
Gary Illyes confirms that robots.txt is a simple and effective solution to prevent indexation of a staging site. Without crawlable access and without significant external signals (links with relevant anchor text), Google will not index these URLs. The important nuance: this works in most cases, but not all.
What you need to understand
How does robots.txt work to block indexation?
The logic is straightforward: Google cannot index what it has not crawled. If the robots.txt file blocks Googlebot's access to all pages on the staging site, the search engine can neither crawl nor analyze the content. Without this analysis, no indexation decision can be made on the basis of the content itself.
This approach relies on a mechanical principle — no crawl, no content in the index. Except for exceptions.
What does "without significant external signals" mean in this context?
Gary Illyes introduces a crucial distinction: even when blocked by robots.txt, a site can be indexed if sufficiently strong external signals exist. He specifically mentions links with relevant anchor text pointing to these URLs.
In concrete terms? If your staging site receives backlinks with descriptive anchors (because a developer shared a link on a forum, or a client published a screenshot with the URL visible), Google can index the URL without ever having crawled the page. Indexation then happens based solely on these external signals.
What are the cases where robots.txt is not enough?
Three main scenarios where this method shows its limitations. First, if external links point to staging with explicit anchor text, Google can create an index entry based solely on these signals.
Second, if the URL was indexed before robots.txt was implemented, it will remain visible in search results — the file prevents crawling, not immediate deindexation. Third, some third-party bots do not respect robots.txt, potentially exposing the site through other channels.
- robots.txt blocks crawling, which generally prevents content indexation
- Without crawling, Google cannot analyze the content and make an indexation decision based on it
- Important exception: external links with relevant anchor text can be enough to trigger partial indexation (URL only, without content)
- This method works in "most cases" according to Gary Illyes — not all
- The distinction between crawling and indexation remains fundamental: blocking one does not automatically prevent the other
SEO Expert opinion
Is this recommendation consistent with real-world observations?
Yes, mostly. Thousands of staging sites protected by robots.txt never appear in the Google index. The method effectively works in most standard configurations — development environment without backlinks, without public sharing, without indexation history.
But the nuance "in most cases" is critical. We regularly observe URLs blocked by robots.txt that appear in SERPs with the notice "No information available for this page". Proof that indexation can occur without crawling, solely through external signals.
What are the real risks that Gary Illyes does not detail?
First blind spot: security through obscurity is not true security. robots.txt does not prevent access to URLs if someone knows them. A competitor, a malicious bot, or a simple curious person can freely explore your staging if they have the address. The robots.txt file is a polite request, not a lock.
Second point: Gary does not mention the case of staging sites that were indexed before robots.txt was implemented. Blocking crawling does not cause immediate deindexation. URLs remain visible in Google, sometimes for weeks, with an empty or outdated snippet.
Third limitation: if your team shares staging URLs (Slack, emails, public documentation, GitHub tickets), these links can be crawled by other services and generate signals that Google captures indirectly. [To verify]: the real extent of this phenomenon remains poorly documented, but anecdotal observations are accumulating.
Practical impact and recommendations
What needs to be implemented concretely to protect a staging site?
First step: create a robots.txt file at the root of your staging domain with a Disallow: / rule globally for all user-agents. Verify that the file is properly accessible and correctly formatted via Search Console or a simple curl command.
Second layer of protection: add HTTP authentication (Basic Auth minimum). This blocks access even if someone knows the URL. This is particularly crucial if your staging contains client data, unfinished features, or strategic content.
Third measure: implement a meta robots noindex tag on all pages. This is redundant with robots.txt, but provides double protection — if robots.txt is misconfigured or ignored, noindex remains active. Some third-party crawlers respect meta tags better than the robots.txt file.
How can you verify that no unintentional indexation has occurred?
Run a Google search using the site:yourstagingdomain.com operator. If results appear, even with "No information available", partial indexation has occurred. Identify the source of external signals (backlinks via Search Console or Ahrefs/Majestic).
Also monitor crawl requests in Search Console. If Googlebot attempts to crawl your staging despite robots.txt, this may signal a configuration error or URLs discovered through public XML sitemaps (yes, it happens).
For sensitive sites, set up automated alerts (Google Alerts on the domain name, regular SEO monitoring) to be notified immediately if pages appear in the index.
What mistakes should you absolutely avoid with this method?
Do not block crawling with robots.txt if pages are already indexed and you want to remove them quickly. In this case, let Google crawl the pages with a noindex tag, then block crawling once deindexation is confirmed. Blocking immediately freezes the situation.
Also avoid relying solely on robots.txt for confidential content. A developer sharing a staging link on Twitter, a screenshot with the URL visible, a poorly secured XML sitemap — so many exposure vectors that robots.txt does not control.
Last point: do not overlook subdomains and multiple environments. Staging.example.com, dev.example.com, preprod.example.com must each have their own robots.txt and their own protections. An oversight on a single environment can expose the entire project.
- Create a robots.txt with Disallow: / for all user-agents
- Add HTTP authentication (Basic Auth minimum) to the entire staging environment
- Implement a meta robots noindex tag on all pages as double security
- Regularly verify with site:yourdomain.com that no unintentional indexation has occurred
- Avoid publicly sharing staging URLs (public Slack, forums, open documentation)
- Monitor backlinks to staging via Search Console or third-party tools
- Never rely on robots.txt alone to protect sensitive or strategic content
- Use dedicated domains or subdomains that are not indexable rather than /staging/ directories
❓ Frequently Asked Questions
Robots.txt empêche-t-il complètement l'indexation d'un site de staging ?
Que faire si mon site de staging apparaît déjà dans l'index Google ?
Robots.txt protège-t-il mon site de staging contre l'accès direct ?
Faut-il aussi utiliser une balise noindex si j'ai déjà un robots.txt ?
Comment des liens externes peuvent-ils déclencher l'indexation sans crawl ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 05/04/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.