Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ La protection par mot de passe est-elle vraiment la solution pour bloquer l'indexation d'un site de staging ?
- □ La balise no-index bloque-t-elle vraiment toute indexation sans exception ?
- □ Les pages orphelines sont-elles vraiment invisibles pour Google ?
- □ Google peut-il vraiment découvrir tous vos sous-domaines ?
- □ Faut-il vraiment soumettre manuellement ses pages importantes au lancement d'un site ?
- □ Faut-il vraiment craindre de publier 7000 articles d'un coup ?
- □ La qualité du contenu bloque-t-elle réellement l'indexation de masse ?
- □ Un nom de domaine propre améliore-t-il vraiment la mémorisation de votre marque ?
- □ Les listes blanches IP suffisent-elles vraiment à protéger vos sites de staging du crawl Google ?
- □ Faut-il vraiment faire du SEO pour un site à fonctionnalité ?
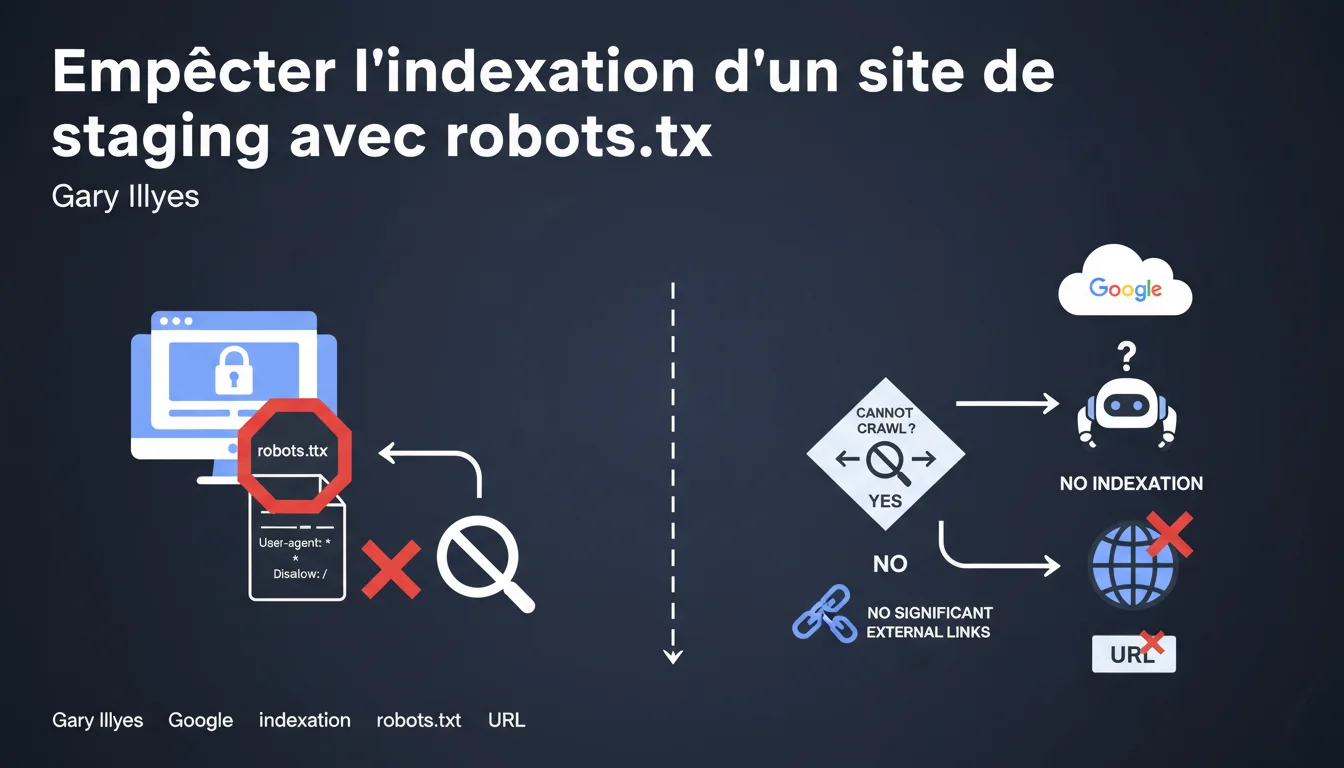
Gary Illyes confirme que robots.txt est une solution simple et efficace pour empêcher l'indexation d'un site de staging. Sans exploration possible et sans indices externes significatifs (liens avec ancres pertinentes), Google n'indexera pas ces URLs. La nuance importante : cela fonctionne dans la plupart des cas, mais pas tous.
Ce qu'il faut comprendre
Pourquoi robots.txt fonctionne-t-il pour bloquer l'indexation ?
La logique est simple : Google ne peut pas indexer ce qu'il n'a pas exploré. Si le fichier robots.txt bloque l'accès de Googlebot à toutes les pages du site de staging, le moteur ne peut ni crawler ni analyser le contenu. Sans cette analyse, aucune décision d'indexation ne peut être prise sur le fond du contenu.
Cette approche repose sur un principe mécanique — pas de crawl, pas de contenu dans l'index. Sauf exception.
Que signifie "sans indices externes significatifs" dans ce contexte ?
Gary Illyes introduit une nuance cruciale : même bloqué par robots.txt, un site peut être indexé si des signaux externes suffisamment forts existent. Il parle spécifiquement de liens avec ancres pertinentes pointant vers ces URLs.
Concrètement ? Si votre site de staging reçoit des backlinks avec des ancres descriptives (parce qu'un développeur a partagé un lien sur un forum, ou qu'un client a publié un screenshot avec l'URL visible), Google peut indexer l'URL sans avoir jamais crawlé la page. L'indexation se fait alors uniquement sur la base de ces signaux externes.
Quels sont les cas où robots.txt ne suffit pas ?
Trois scénarios principaux où cette méthode montre ses limites. Premièrement, si des liens externes pointent vers le staging avec des ancres explicites, Google peut créer une entrée dans l'index basée uniquement sur ces signaux.
Deuxièmement, si l'URL a été indexée avant la mise en place du robots.txt, elle restera visible dans les résultats — le fichier empêche le crawl, pas la désindexation immédiate. Troisièmement, certains bots tiers ne respectent pas robots.txt, exposant potentiellement le site via d'autres canaux.
- Robots.txt bloque le crawl, ce qui empêche généralement l'indexation du contenu
- Sans exploration, Google ne peut pas analyser le contenu et prendre de décision d'indexation basée sur celui-ci
- Exception importante : des liens externes avec ancres pertinentes peuvent suffire à déclencher une indexation partielle (URL uniquement, sans contenu)
- Cette méthode fonctionne dans "la plupart des cas" selon Gary Illyes — pas tous
- La distinction crawl/indexation reste fondamentale : bloquer l'un n'empêche pas automatiquement l'autre
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les observations terrain ?
Oui, majoritairement. Des milliers de sites de staging protégés par robots.txt ne remontent jamais dans l'index Google. La méthode fonctionne effectivement dans la plupart des configurations classiques — environnement de dev sans backlinks, sans partage public, sans historique d'indexation.
Mais la nuance "dans la plupart des cas" est capitale. On observe régulièrement des URLs bloquées par robots.txt qui apparaissent dans les SERPs avec la mention "Aucune information disponible pour cette page". Preuve que l'indexation peut se produire sans crawl, uniquement via des signaux externes.
Quels sont les vrais risques que Gary Illyes ne détaille pas ?
Premier angle mort : la sécurité par l'obscurité n'est pas une sécurité. Robots.txt n'empêche pas l'accès aux URLs si quelqu'un les connaît. Un concurrent, un bot malveillant ou un simple curieux peut explorer librement votre staging s'il en a l'adresse. Le fichier robots.txt est une demande polie, pas un verrou.
Deuxième point : Gary ne mentionne pas le cas des sites de staging qui ont été indexés avant la mise en place du robots.txt. Bloquer le crawl ne provoque pas une désindexation immédiate. Les URLs restent visibles dans Google, parfois pendant des semaines, avec un snippet vide ou obsolète.
Troisième limite : si votre équipe partage des URLs de staging (Slack, emails, documentation publique, tickets GitHub), ces liens peuvent être crawlés par d'autres services et générer des signaux que Google capte indirectement. [À vérifier] : l'ampleur réelle de ce phénomène reste mal documentée, mais les observations anecdotiques s'accumulent.
Impact pratique et recommandations
Que faut-il mettre en place concrètement pour protéger un site de staging ?
Première étape : créez un fichier robots.txt à la racine de votre domaine de staging avec un Disallow: / global pour tous les user-agents. Vérifiez que le fichier est bien accessible et correctement formaté via la Search Console ou un simple curl.
Deuxième couche de protection : ajoutez une authentification HTTP (Basic Auth minimum). Cela bloque l'accès même si quelqu'un connaît l'URL. C'est particulièrement crucial si votre staging contient des données clients, des fonctionnalités non finalisées ou du contenu stratégique.
Troisième mesure : utilisez une meta robots noindex sur toutes les pages. C'est redondant avec robots.txt, mais cela offre une double protection — si jamais le robots.txt est mal configuré ou ignoré, le noindex reste actif. Certains crawlers tiers respectent mieux les meta tags que le fichier robots.txt.
Comment vérifier qu'aucune indexation involontaire n'a eu lieu ?
Lancez une recherche Google avec l'opérateur site:votredomainestaging.com. Si des résultats apparaissent, même avec "Aucune information disponible", c'est qu'une indexation partielle s'est produite. Identifiez la source des signaux externes (backlinks via Search Console ou Ahrefs/Majestic).
Surveillez également les requêtes d'exploration dans la Search Console. Si Googlebot tente de crawler votre staging malgré le robots.txt, cela peut signaler une erreur de configuration ou des URLs découvertes via des sitemaps XML publics (oui, ça arrive).
Pour les sites sensibles, configurez des alertes automatisées (Google Alerts sur le nom de domaine, monitoring SEO régulier) pour être notifié immédiatement si des pages apparaissent dans l'index.
Quelles erreurs éviter absolument avec cette méthode ?
Ne bloquez pas le crawl avec robots.txt si des pages sont déjà indexées et que vous voulez les supprimer rapidement. Dans ce cas, laissez Google crawler les pages avec une balise noindex, puis bloquez le crawl une fois la désindexation confirmée. Bloquer immédiatement fige la situation.
Évitez aussi de vous reposer uniquement sur robots.txt pour du contenu confidentiel. Un développeur qui partage un lien de staging sur Twitter, un screenshot avec l'URL visible, un sitemap XML mal sécurisé — autant de vecteurs d'exposition que robots.txt ne contrôle pas.
Dernier point : ne négligez pas les sous-domaines et environnements multiples. Staging.example.com, dev.example.com, preprod.example.com doivent chacun avoir leur propre robots.txt et leurs propres protections. Un oubli sur un seul environnement peut exposer l'ensemble du projet.
- Créer un robots.txt avec Disallow: / pour tous les user-agents
- Ajouter une authentification HTTP (Basic Auth minimum) sur tout l'environnement de staging
- Implémenter une meta robots noindex sur toutes les pages comme double sécurité
- Vérifier régulièrement avec site:votredomain.com qu'aucune indexation involontaire n'a eu lieu
- Éviter de partager publiquement des URLs de staging (Slack public, forums, documentation ouverte)
- Surveiller les backlinks vers le staging via Search Console ou outils tiers
- Ne jamais compter sur robots.txt seul pour protéger du contenu sensible ou stratégique
- Utiliser des domaines ou sous-domaines dédiés non indexables plutôt que des répertoires /staging/
❓ Questions frequentes
Robots.txt empêche-t-il complètement l'indexation d'un site de staging ?
Que faire si mon site de staging apparaît déjà dans l'index Google ?
Robots.txt protège-t-il mon site de staging contre l'accès direct ?
Faut-il aussi utiliser une balise noindex si j'ai déjà un robots.txt ?
Comment des liens externes peuvent-ils déclencher l'indexation sans crawl ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/04/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.