Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi robots.txt suffit-il (presque toujours) à bloquer l'indexation d'un site de staging ?
- □ La protection par mot de passe est-elle vraiment la solution pour bloquer l'indexation d'un site de staging ?
- □ La balise no-index bloque-t-elle vraiment toute indexation sans exception ?
- □ Les pages orphelines sont-elles vraiment invisibles pour Google ?
- □ Google peut-il vraiment découvrir tous vos sous-domaines ?
- □ Faut-il vraiment soumettre manuellement ses pages importantes au lancement d'un site ?
- □ Faut-il vraiment craindre de publier 7000 articles d'un coup ?
- □ Un nom de domaine propre améliore-t-il vraiment la mémorisation de votre marque ?
- □ Les listes blanches IP suffisent-elles vraiment à protéger vos sites de staging du crawl Google ?
- □ Faut-il vraiment faire du SEO pour un site à fonctionnalité ?
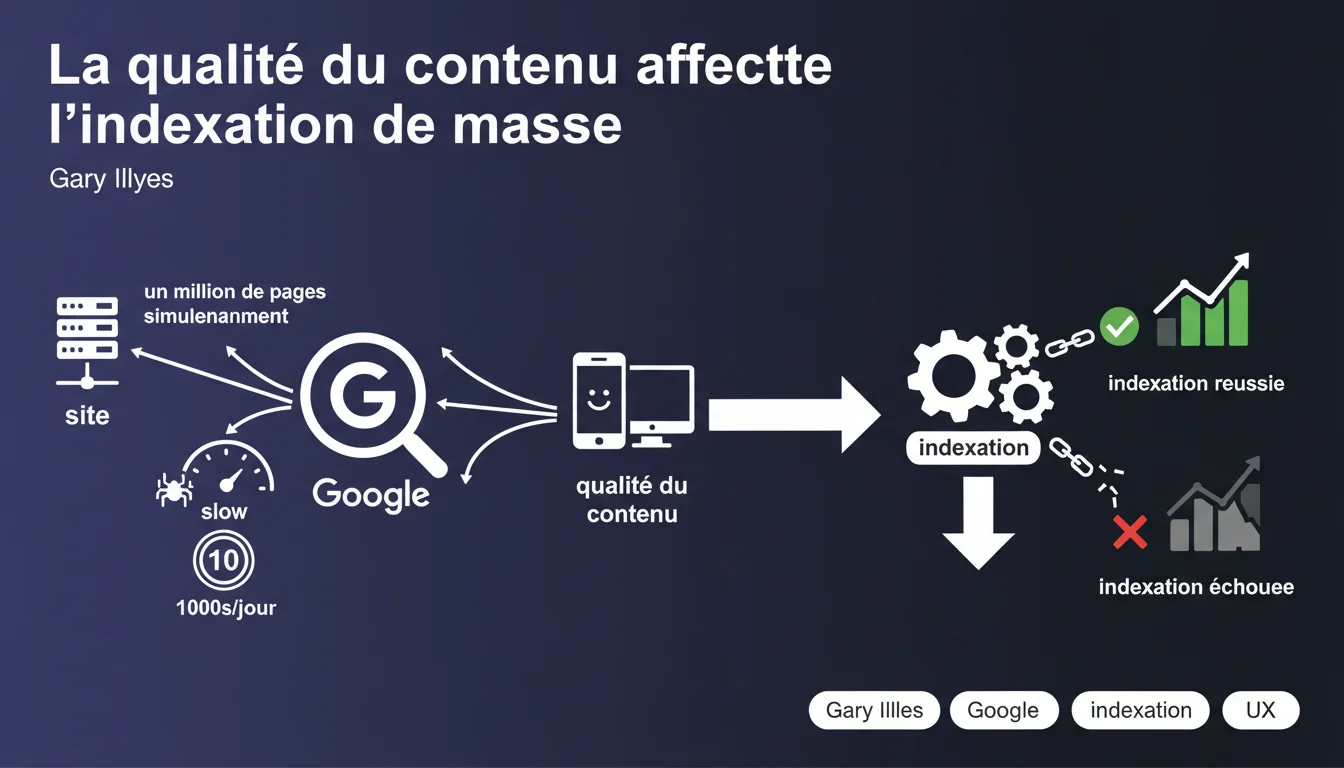
Google indexe rarement un million de pages d'un coup, même si techniquement le crawl est possible. La qualité du contenu devient un filtre déterminant pour décider quelles pages méritent d'entrer dans l'index. Le crawl budget n'est qu'une partie du problème — c'est la valeur perçue du contenu qui dicte l'indexation à grande échelle.
Ce qu'il faut comprendre
Pourquoi Google limite-t-il l'indexation de masse même si le crawl est techniquement faisable ?
Le crawl budget — ce quota quotidien de quelques milliers d'URLs que Googlebot peut visiter sans surcharger un serveur — n'est qu'un garde-fou technique. Si votre infrastructure tient la charge, Google pourrait techniquement crawler davantage. Mais ce n'est pas le vrai goulot.
La vraie limite, c'est la qualité du contenu. Quand un site tente de faire indexer un million de pages simultanément, Google active des filtres de pertinence stricts. L'indexation devient sélective : seules les pages jugées utiles et originales passeront. Le reste ? Crawlé, mais jamais ajouté à l'index.
Qu'est-ce que cela change pour un site avec des milliers de pages ?
Concrètement, si vous lancez un site e-commerce avec 500 000 fiches produits générées automatiquement, Google ne va pas tout indexer. Il va échantillonner, évaluer la duplication, la valeur ajoutée, la pertinence thématique. Si 80 % des pages se ressemblent ou n'apportent rien, elles resteront hors index.
Cette déclaration confirme ce que beaucoup observent sur le terrain : l'indexation n'est plus un droit, c'est un privilège gagné par la qualité. Les sites qui diluent leur contenu avec des pages faibles paient le prix fort.
Quels sont les points essentiels à retenir de cette déclaration ?
- Le crawl budget existe toujours, mais il n'est qu'une contrainte technique secondaire comparée à la qualité du contenu.
- Google peut crawler quelques milliers d'URLs par jour sans surcharger un serveur — mais cela ne garantit aucunement leur indexation.
- L'indexation de masse nécessite du contenu à haute valeur ajoutée, original et non redondant.
- Les sites qui tentent de gonfler artificiellement leur volume de pages avec du contenu faible ou dupliqué seront filtrés sévèrement.
- La stratégie doit privilégier la densité qualitative plutôt que la quantité brute de pages indexables.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et elle confirme ce qu'on voit depuis les mises à jour Helpful Content et les vagues de désindexation massives. Google a durci ses critères d'indexation. Des sites avec des centaines de milliers de pages voient désormais 40 à 60 % de leur contenu exclu de l'index, même si ces pages sont techniquement crawlées.
Mais soyons honnêtes : Google reste vague sur ce qui définit précisément la "qualité" dans ce contexte. Est-ce la fraîcheur ? L'originalité textuelle ? La profondeur sémantique ? La pertinence UX ? [A vérifier] — aucune métrique chiffrée n'est donnée.
Quelles nuances faut-il apporter à cette affirmation ?
Le crawl budget n'est pas uniforme. Un site d'autorité établi avec un bon PageRank interne et des signaux de confiance forts peut voir Google crawler bien plus que "quelques milliers d'URLs par jour". À l'inverse, un nouveau site sans backlinks ni historique sera bridé, même si son contenu est excellent.
Et c'est là que ça coince : la qualité seule ne suffit pas si Google ne vous alloue pas assez de crawl pour découvrir ce contenu. Il y a un effet de seuil — en dessous d'une certaine visibilité, même les meilleures pages restent invisibles faute d'avoir été explorées.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Les sites d'actualité et les agrégateurs de données structurées bénéficient parfois d'une indexation rapide et massive, même avec des millions de pages. Pourquoi ? Parce que Google a des pipelines spécifiques pour les contenus à forte vélocité temporelle (news, événements, prix en temps réel).
De même, les sites avec une architecture technique irréprochable — sitemap XML segmenté, rendering instantané, signaux Core Web Vitals excellents — peuvent compenser en partie un contenu moyennement différencié. Mais c'est marginal. La qualité reste le filtre dominant.
Impact pratique et recommandations
Que faut-il faire concrètement pour maximiser l'indexation de masse ?
Première priorité : auditer impitoyablement la qualité de chaque segment de contenu. Identifiez les pages qui n'apportent aucune valeur unique — fiches produits vides, catégories redondantes, contenus générés automatiquement sans enrichissement. Supprimez-les ou fusionnez-les.
Ensuite, concentrez le crawl budget sur vos pages stratégiques. Utilisez le fichier robots.txt pour bloquer les URLs inutiles (filtres, tris, sessions), optimisez votre maillage interne pour pousser les pages prioritaires, et segmentez vos sitemaps XML par niveau de priorité réelle.
Quelles erreurs éviter absolument avec un grand volume de pages ?
Ne tentez jamais de faire indexer un million de pages d'un coup sans avoir validé leur différenciation sémantique. Google va échantillonner, et si vos 100 premières pages crawlées sont médiocres, il va extrapoler et ignorer le reste.
Évitez aussi de miser uniquement sur la technique — un site ultra-rapide avec un contenu faible sera crawlé efficacement, puis ignoré à l'indexation. La vitesse ne compense pas la vacuité éditoriale.
Comment vérifier que votre stratégie d'indexation fonctionne ?
- Vérifiez le taux d'indexation réel dans Google Search Console (Pages indexées / Pages soumises) — un ratio inférieur à 60 % signale un problème de qualité.
- Analysez les raisons d'exclusion dans GSC : "Détectée, actuellement non indexée" ou "Explorée, actuellement non indexée" indiquent que Google juge votre contenu insuffisant.
- Segmentez vos pages par typologie et comparez leurs taux d'indexation — identifiez les segments systématiquement rejetés.
- Surveillez l'évolution du crawl budget quotidien dans les rapports de statistiques d'exploration — une baisse brutale signale souvent une dégradation de confiance.
- Testez l'indexation manuelle via l'outil d'inspection d'URL sur un échantillon représentatif — si Google refuse d'indexer manuellement, la qualité est en cause.
- Comparez votre PageRank interne (via Screaming Frog ou OnCrawl) avec les pages effectivement indexées — les pages à faible PR interne sont souvent ignorées.
❓ Questions frequentes
Le crawl budget est-il le principal obstacle à l'indexation de masse ?
Comment Google évalue-t-il la qualité du contenu pour l'indexation de masse ?
Un site peut-il forcer l'indexation de toutes ses pages avec un meilleur crawl budget ?
Faut-il supprimer les pages non indexées pour améliorer le taux global ?
Les sitemaps XML aident-ils à indexer des millions de pages plus rapidement ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/04/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.