Official statement
Other statements from this video 11 ▾
- □ Pourquoi Google avait-il tant de mal à comprendre les mots de liaison comme 'not' dans les requêtes ?
- □ Comment Google évalue-t-il réellement la qualité de son moteur : mesures globales ou analyse segmentée ?
- □ Google applique-t-il vraiment un principe d'équilibre entre types de sites dans ses résultats ?
- □ Pourquoi vos stratégies de mots-clés longue traîne sont-elles dépassées depuis l'arrivée du NLU ?
- □ Google privilégie-t-il vraiment la promotion plutôt que la pénalité ?
- □ Pourquoi Google a-t-il conçu les Featured Snippets autour de la compréhension sémantique plutôt que du matching de mots-clés ?
- □ Comment Google mesure-t-il vraiment la satisfaction des utilisateurs dans ses résultats de recherche ?
- □ E-E-A-T est-il vraiment un facteur de ranking ou juste un mythe SEO ?
- □ Pourquoi Google se méfie-t-il du volume de requêtes comme indicateur de qualité ?
- □ Les Quality Rater Guidelines sont-elles vraiment un mode d'emploi pour le SEO ?
- □ Comment Google priorise-t-il les bugs de recherche et qu'est-ce que ça change pour le SEO ?
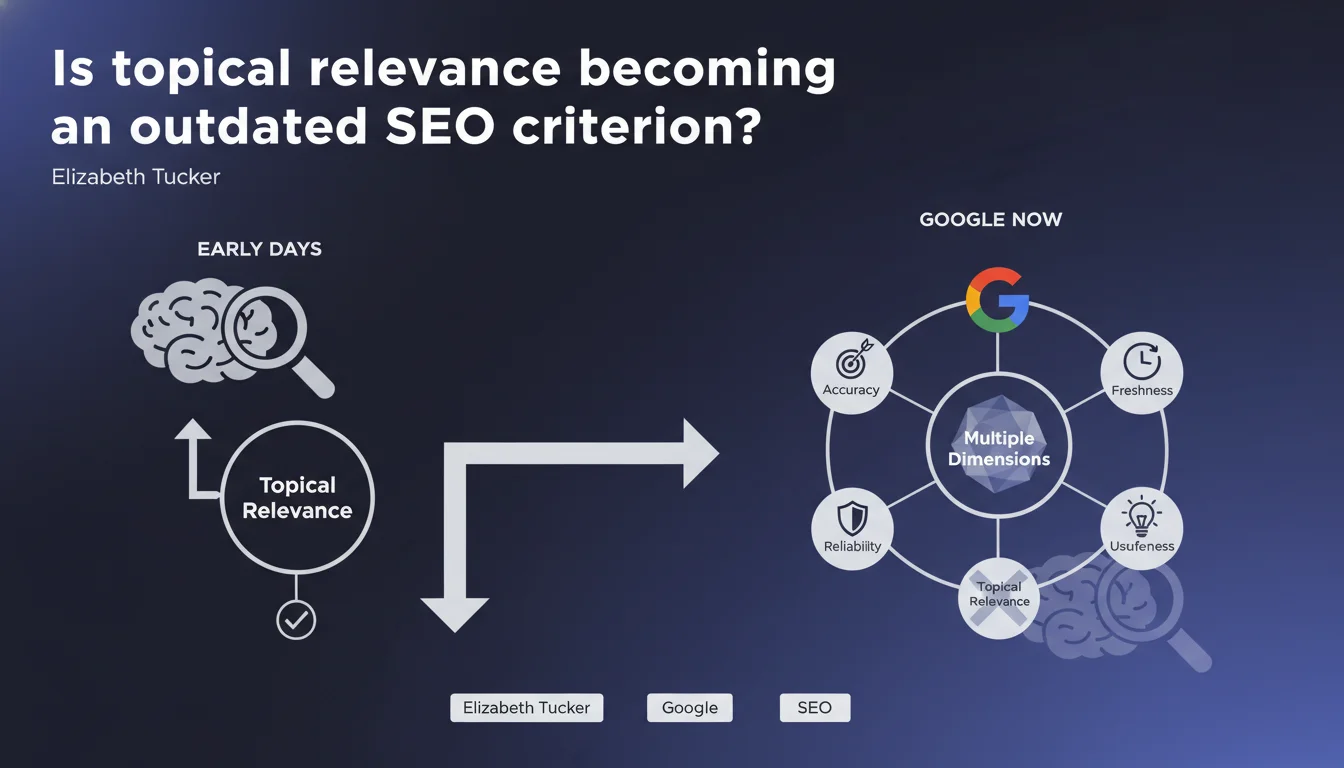
Google claims that thematic relevance alone is no longer enough to rank. The search engine now evaluates accuracy, reliability, freshness, and real-world usefulness of content. A statement that fundamentally repositions SEO priorities beyond simple semantic matching.
What you need to understand
Why is Google questioning topical relevance?
Thematic relevance has long been the dominant criterion for understanding and ranking pages. For years, the main challenge was determining whether a document answered a user's search intent from a semantic perspective.
Google now recognizes that this paradigm is insufficient. Content can be perfectly optimized from a topical standpoint while being riddled with inaccuracies, outdated, or simply useless to the user. The statement marks a shift toward multidimensional quality criteria.
What are these new criteria that complement topical relevance?
Elizabeth Tucker lists four dimensions: accuracy (are the facts correct?), reliability (is the source trustworthy?), freshness (is the content up-to-date?), and usefulness (does it provide real added value?)
These criteria aren't new in themselves — they echo E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) and Helpful Content concepts. What changes is the hierarchy: topical relevance becomes a necessary but insufficient condition.
How does Google measure these dimensions in practice?
The statement remains deliberately vague about technical mechanisms. We know Google uses indirect signals — user behavior, external citations, scientific consensus, update history — but no specific algorithm is mentioned.
Language models (LLMs) likely play an increasingly important role in evaluating factual consistency and perceived usefulness, but Google doesn't detail their implementation in ranking. [To verify]
- Topical relevance remains a prerequisite, not a guarantee of visibility
- Google now evaluates four quality dimensions: accuracy, reliability, freshness, usefulness
- These criteria align with E-E-A-T principles and Helpful Content
- Measurement mechanisms remain opaque and rely on indirect signals
SEO Expert opinion
Does this statement truly reflect real-world observations?
Yes, but with important nuances. We've observed through several Core Updates that content perfectly optimized semantically loses rankings to pages that are less keyword-dense but better sourced or more recent.
The problem? Google doesn't define a measurement scale. What makes content "accurate" or "useful"? These notions remain subjective and contextual. A medical article requires academic sources, a DIY tutorial values personal experience. The statement glosses over these industry variations.
Which sectors are most impacted by this paradigm shift?
YMYL verticals (health, finance, legal) are the first to be affected. Accuracy and reliability become quasi-binary filters: inaccurate content is penalized regardless of semantic quality.
Conversely, in generic informational queries or opinion content, topical relevance retains major weight. A lifestyle blog can rank without academic sourcing if perceived usefulness is strong. [To verify]: Does Google truly apply differentiated weighting by query type, or does it stick to a uniform model?
Is this statement hiding a Google technical difficulty?
Probably. Evaluating accuracy or usefulness at web scale is infinitely more complex than calculating TF-IDF. Google relies on imperfect signals: clicks, session duration, external links.
The risk? That the engine confuses popularity with accuracy. Factually incorrect but viral content can generate positive behavioral signals short-term. Google doesn't specify how it arbitrates these contradictions — and that's a major blind spot.
Practical impact and recommendations
What concrete changes should you make to your content strategy?
Stop believing that an exhaustive semantic field is enough. A 3,000-word article stuffed with keywords but lacking sources or recent updates becomes a vulnerable target. Prioritize density of verifiable information over volume.
Systematically add visible publication and revision dates. If your content covers an evolving topic (technology, regulation, health), plan semi-annual updates. Google explicitly values freshness — don't make it guess.
How do you strengthen perceived accuracy and reliability for Google?
Cite primary sources: studies, official reports, databases. External links to authoritative sites don't dilute your PageRank — they strengthen your contextual credibility.
Clearly identify authors and their qualifications. A medical article signed by a doctor with a link to their professional profile sends strong E-E-A-T signals. Anonymous content, however excellent, starts at a disadvantage.
What mistakes should you avoid with these new criteria?
Don't sacrifice topical relevance under the guise of prioritizing accuracy. Both are cumulative, not alternative. Off-topic but "reliable" content won't rank either.
Avoid contradictory signals: a three-year-old article claiming "recently updated" with no visible content changes. Google detects these inconsistencies through archives and crawl variations.
- Audit existing content: identify pieces lacking sources, dates, or identified authors
- Prioritize updates on YMYL pages and those that have lost traffic recently
- Add credible external references to every article (minimum 2-3 links to authoritative sources)
- Implement an automatic revision calendar for outdated content
- Structure author pages with detailed bio and professional links (LinkedIn, publications, certifications)
- Monitor behavioral metrics (session duration, bounce rate) to detect perceived usefulness signals
❓ Frequently Asked Questions
La pertinence topique ne compte-t-elle vraiment plus pour le ranking ?
Comment Google mesure-t-il l'exactitude d'un contenu ?
Les backlinks restent-ils importants dans ce nouveau paradigme ?
Faut-il privilégier du contenu court et précis ou long et exhaustif ?
Cette déclaration annonce-t-elle un algorithme spécifique à venir ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 27/06/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.