Official statement
Other statements from this video 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
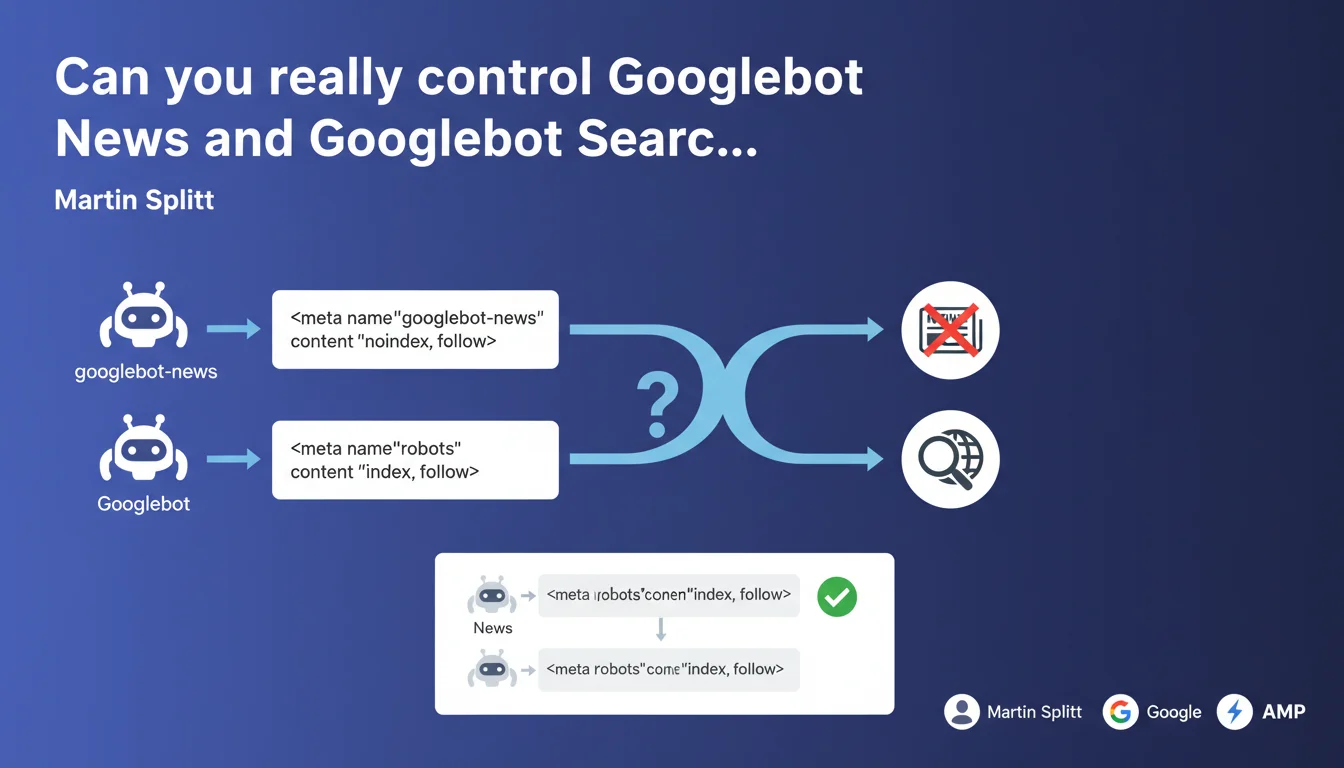
Google confirms that you can target specific robots via the 'name' attribute of the meta robots tag. By using 'googlebot-news' instead of 'robots', you give instructions only to Googlebot News without impacting classic Googlebot Search. This granularity enables differentiated crawl control according to Google verticals.
What you need to understand
Why is this distinction between Googlebot robots possible?
The standard meta robots tag with name="robots" applies to all crawlers indiscriminately. But Google operates multiple versions of Googlebot depending on the vertical: Googlebot Search, Googlebot News, Googlebot Images, and so on.
Each bot can receive specific directives via the name attribute. Concretely, googlebot-news addresses only the News crawler, while Googlebot Search ignores this instruction and follows only those directives that target it explicitly or the generic 'robots' directive.
What's the priority logic between these directives?
The rule is simple: specific targeting overrides generic targeting. If you define both name="robots" and name="googlebot-news", the latter takes precedence for the News bot.
Example: meta name="robots" content="index, follow" + meta name="googlebot-news" content="noindex" → the page will be indexed in Search but not in Google News. This hierarchy allows granular control without conflict between directives.
What are the bot identifiers recognized by Google?
Google documents several identifiers: googlebot (generic for all Googlebot), googlebot-news, googlebot-images, googlebot-video, googlebot-shopping. Each responds to its own specific directive.
The pitfall: using a made-up or misspelled identifier won't cause any error, but the directive will simply be ignored. Always verify exact spelling and case — googlebot-news, not googlebotNews or googlebot_news.
- Specific directives take priority over generic directives (googlebot-news > robots)
- Each Googlebot vertical has its own identifier to use in the 'name' attribute
- A page can accumulate multiple meta robots tags with different targets without conflict
- The order of meta tags in the HTML has no importance, only specificity matters
- An incorrect or invented identifier will be silently ignored without generating an error
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, and it's been documented for years in Google's technical documentation. Except that few practitioners actually exploit it — most settle for the generic robots tag.
We mainly see this approach on media sites that want to exclude certain sections from Google News (for example sponsored content or author pages) while keeping them indexed in Search. Concretely, it works: a page with noindex for googlebot-news disappears from News but remains in classic search results.
What nuances should be added to this statement?
Martin Splitt oversimplifies slightly. Generic robots directives also apply to Googlebot if no specific googlebot directive is defined. So robots + googlebot-news isn't always enough: it may be wise to add googlebot or googlebot-images depending on your needs.
Another point: this granularity works for meta tags, but robots.txt doesn't allow this fine-grained level of targeting. The User-agent in robots.txt certainly distinguishes Googlebot-News from Googlebot, but we remain in a logic of blocking paths, not page-by-page indexation directives. [To verify]: some observe that Googlebot sometimes ignores ultra-specific directives if they contradict strong signals in robots.txt or Search Console.
In what cases does this rule not apply as expected?
Be careful with X-Robots-Tag in HTTP headers: they can conflict with meta robots if they don't target the same bots. If your server sends X-Robots-Tag: noindex for all bots and you put a meta googlebot-news: index, follow, the header often takes precedence based on observations.
Another problematic case: pages rendered client-side (JavaScript). If the meta tag is only injected after rendering, some bots may not see it — and then the generic directive or absence of directive takes over. Always test with the URL inspection tool to verify what Googlebot actually sees.
Practical impact and recommendations
What should you concretely do to exploit this granularity?
First identify the sections of your site that require differentiated treatment across Google verticals. Typically: editorial content for News, product sheets for Shopping, galleries for Images.
Next, implement meta tags with the correct identifiers. Example for excluding a page from News only: <meta name="googlebot-news" content="noindex"> + <meta name="robots" content="index, follow">. If you manage thousands of pages, centralize this logic in your templates or CMS to avoid manual errors.
What errors should you avoid when implementing?
Classic mistake: multiplying tags without coherence. Three meta robots tags with directives that contradict each other is a gateway to bugs. Define a clear strategy: which vertical for which section, and document it.
Another trap: forgetting that robots.txt blocks crawling before even reading the meta tags. If you block /news/ in robots.txt for Googlebot-News, the meta tag will never be read. The blocking logic must be consistent between robots.txt (access) and meta robots (indexation).
- Map the sections of your site and their relevance by Google vertical (News, Images, Shopping, etc.)
- Use the exact identifiers documented by Google (googlebot-news, googlebot-images, etc.) — verify the case
- Test each implementation with the URL inspection tool in Search Console to validate what Googlebot sees
- Document your targeting strategy in a dashboard or internal wiki to prevent future inconsistencies
- Monitor actual indexation through Search Console coverage reports, filtered by content type if possible
- Avoid conflicts between robots.txt, meta robots and X-Robots-Tag — favor a single source of truth per directive
How do you verify that the targeting is working correctly?
The most reliable way: Search Console, Coverage tab. If a page is excluded from News but indexed in Search, you'll see the difference in the reports. For News specifically, also check the "Performance on Google News" report if your site is eligible.
Another method: site:yoursite.com on classic Google Search vs. direct search in Google News. If a URL appears in one and not the other, your targeting is working. But be careful, this isn't instantaneous — allow a few days for Googlebot to recrawl after modification.
Specific bot targeting via the meta robots tag offers surgical control of indexation by vertical. It's particularly powerful for media sites, e-commerce or mixed operations that play across multiple Google tables.
Implementation requires rigor and consistency — a documented strategy, systematic testing, and continuous monitoring through Search Console. These technical optimizations can quickly become complex at scale, especially if your architecture mixes server-side rendering, JavaScript and multiple templates. In this case, support from a specialized SEO agency may prove valuable to avoid missteps and maximize the impact of this granularity.
❓ Frequently Asked Questions
Peut-on cumuler plusieurs balises meta robots avec des cibles différentes sur une même page ?
Si je bloque Googlebot-News dans robots.txt, la balise meta googlebot-news sera-t-elle quand même lue ?
Les directives spécifiques fonctionnent-elles aussi avec X-Robots-Tag en HTTP headers ?
Que se passe-t-il si j'utilise un identifiant de bot qui n'existe pas, comme 'googlebot-toto' ?
Est-ce que cette approche fonctionne avec Bing ou d'autres moteurs de recherche ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 04/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.