Official statement
Other statements from this video 15 ▾
- □ Does Google really juggle 40 different signals to pick the right canonical URL?
- □ Does Google really treat clustering and canonicalization as two separate processes, or is it all just one mechanism?
- □ Does rel canonical really play a dual role in Google's algorithm?
- □ What happens when your canonicalization signals contradict each other?
- □ Does Google actually prioritize HTTPS in search results, or does it depend on other factors?
- □ Is your redirect chain preventing Google from choosing the HTTPS version as canonical?
- □ Does hreflang really work independently from duplicate content clustering?
- □ Is Google really about to give trusted sites an hreflang fast-track to indexing?
- □ Is x-default really functioning as a canonical signal like the others?
- □ Do 200 Error Pages Really Create Clustering Black Holes?
- □ Are soft 404 pages really the only ones creating problematic clusters in your index?
- □ Can a clear error message really save your crawl budget from clustering disasters?
- □ Does Google really handle JavaScript redirects to error pages correctly through clustering?
- □ Does Google really remove pages faster with a no-index than with a 404 or 410 error code?
- □ Can an empty rel canonical really wipe your entire site from Google's index?
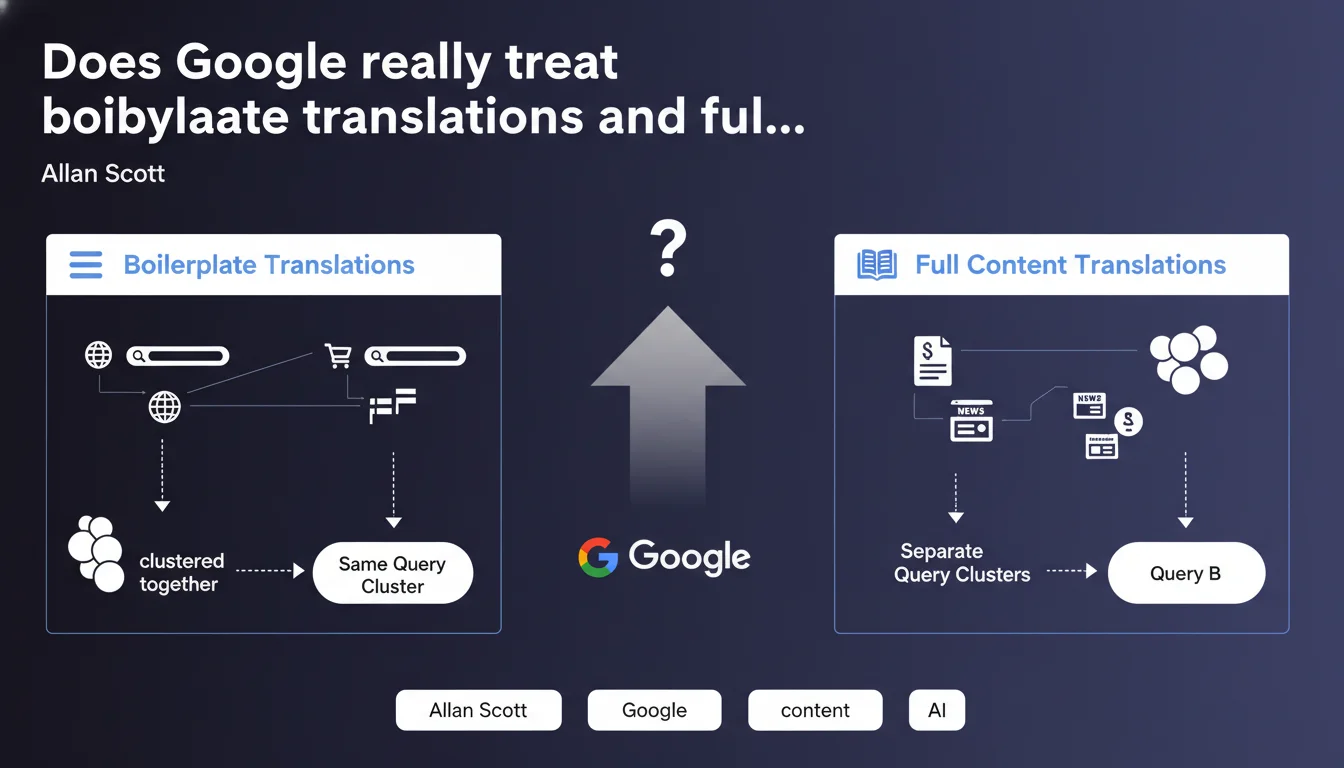
Google distinguishes between translations of interface elements (menus, navigation) and translations of editorial content. Translated boilerplates are grouped together in the same deduplication cluster, while translated content remains separate because it targets distinct linguistic queries. This differentiation directly impacts indexing and ranking for multilingual websites.
What you need to understand
What does Google mean by boilerplate translation?
The boilerplate refers to all structural and navigational elements of a website: navigation menus, footers, sidebars, form labels, action buttons. These elements repeat identically across dozens or hundreds of pages.
When you simply translate these elements from one language to another without modifying the main content, Google considers the pages to be nearly identical. The engine then groups them into the same deduplication cluster — only one version will be prioritized in search results.
Why do complete translations escape this grouping?
A complete translation includes not only the boilerplate, but especially the main editorial content: articles, product descriptions, guides. This content responds to linguistically different queries, even if the search intent remains similar.
A French speaker searching for "meilleur smartphone 2023" and an English speaker typing "best smartphone 2023" have the same intent, but Google understands that each linguistic version targets a distinct audience. Pages therefore remain in separate clusters and can all rank in their respective markets.
What are the implications for multilingual indexing?
This distinction directly impacts your international deployment strategy. If you only translate menus and navigation while keeping the main content identical or nearly identical, Google will likely cannibalize your linguistic versions against each other.
- Pages with boilerplate-only translation are clustered together — only one version displays
- Pages with translated editorial content remain in distinct clusters — each version can rank
- Hreflang tags alone are not enough to force Google to index all versions if content is deemed redundant
- The quality of translation matters: poor machine translation can be rejected even if complete
SEO Expert opinion
Is this distinction really new for practitioners?
Let's be honest: this official statement formalizes what many of us have been observing in the field for years. Google has always prioritized added content value over cosmetic variations. What's changing is the explicit confirmation of the clustering mechanism applied differently based on translation type.
In practice, I've seen multilingual e-commerce sites with nearly identical product sheets (only the boilerplate changed) suffer severe cannibalization between linguistic versions. Google arbitrarily chose one version — often .com rather than .fr or .de — even with perfectly configured hreflang tags.
What gray areas persist despite this clarification?
Google remains deliberately vague on several critical points. What percentage of content must be translated to escape clustering? 50%? 80%? [To be verified] — no precise metric is provided.
Another gray area: how does Google evaluate the semantic quality of a translation? Is post-edited machine translation sufficient, or must it be native human translation? The statement doesn't clarify this. On client sites, I've observed that high-quality DeepL translations performed well, but this isn't an absolute rule.
In which cases does this clustering logic fail?
User geolocation can override this logic. Google sometimes forces display of a local version even if it's clustered, creating inconsistencies in SERPs depending on connection IP.
Sites with geo-specific content (prices in local currencies, regional availability, regulations) naturally escape clustering, even if editorial content remains close. Google detects these structural differences as local relevance signals.
Practical impact and recommendations
What should be audited first on an existing multilingual site?
Start with a translated content vs boilerplate ratio on your main templates. Take 5-10 typical pages (homepage, category, product sheet, article) and calculate the percentage of unique translated text relative to repeated structural elements.
Then check in Search Console whether all your linguistic versions are actually indexed and generating impressions. A massive imbalance (e.g., .com with 80% of impressions, .fr and .de at 10% each) likely signals unwanted clustering.
Also monitor cannibalization patterns: if for the same translated query, Google alternates between your linguistic versions day by day, it's a signal that it doesn't differentiate them sufficiently.
What concrete corrective actions should be implemented?
For e-commerce sites with standardized product sheets, enrich descriptions in each language rather than translating word-for-word. Add local use cases, adapt cultural references, modify the angle if necessary.
On editorial sites, never settle for simply translating an article — localize it. Adapt examples, cite local sources, modify the perspective if needed. An article on "best tax practices" can't be a simple translation between France and Belgium.
Use multilingual structured data to reinforce differentiation signals: customer reviews in the local language, geolocated events, FAQs adapted to regional questions.
- Calculate the ratio of unique content / boilerplate on your main templates
- Audit indexing and impressions by linguistic version in Search Console
- Identify cannibalization patterns between versions via multilingual rank tracking
- Enrich translated content with culturally specific elements
- Implement localized structured data (reviews, FAQ, events)
- Test the quality of automatic vs human translations on strategic pages
- Monitor indexing evolution after modifications for at least 4-6 weeks
❓ Frequently Asked Questions
Les balises hreflang suffisent-elles à éviter le clustering de pages traduites ?
Faut-il traduire 100% du contenu ou un pourcentage suffit-il ?
Une traduction automatique (DeepL, Google Translate) est-elle pénalisante ?
Comment détecter si mes versions linguistiques sont clustérisées ?
Le duplicate content entre versions linguistiques est-il pénalisant ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 05/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.