Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Comment Google jongle-t-il avec 40 signaux pour choisir l'URL canonique ?
- □ Clustering et canonicalisation : Google fait-il vraiment la différence entre ces deux processus ?
- □ Le rel canonical joue-t-il un double rôle dans l'algorithme de Google ?
- □ Que se passe-t-il quand vos signaux de canonicalisation se contredisent ?
- □ Comment Google choisit-il réellement entre HTTP et HTTPS dans ses résultats ?
- □ Pourquoi vos redirections multiples empêchent-elles Google de choisir la version HTTPS ?
- □ Hreflang fonctionne-t-il indépendamment du clustering de contenu dupliqué ?
- □ Google va-t-il vraiment faciliter le traitement du hreflang pour les sites fiables ?
- □ X-default est-il vraiment un signal canonique comme les autres ?
- □ Les pages d'erreur 200 créent-elles vraiment des trous noirs de clustering ?
- □ Les pages en soft 404 sont-elles vraiment les seules à créer des clusters problématiques ?
- □ Pourquoi un message d'erreur explicite peut-il sauver votre crawl budget ?
- □ Les redirections JavaScript vers des pages d'erreur sont-elles vraiment prises en compte par Google ?
- □ Pourquoi un no-index supprime-t-il une page plus vite qu'une erreur 404 ou 410 ?
- □ Un rel canonical vide peut-il vraiment supprimer tout votre site de l'index Google ?
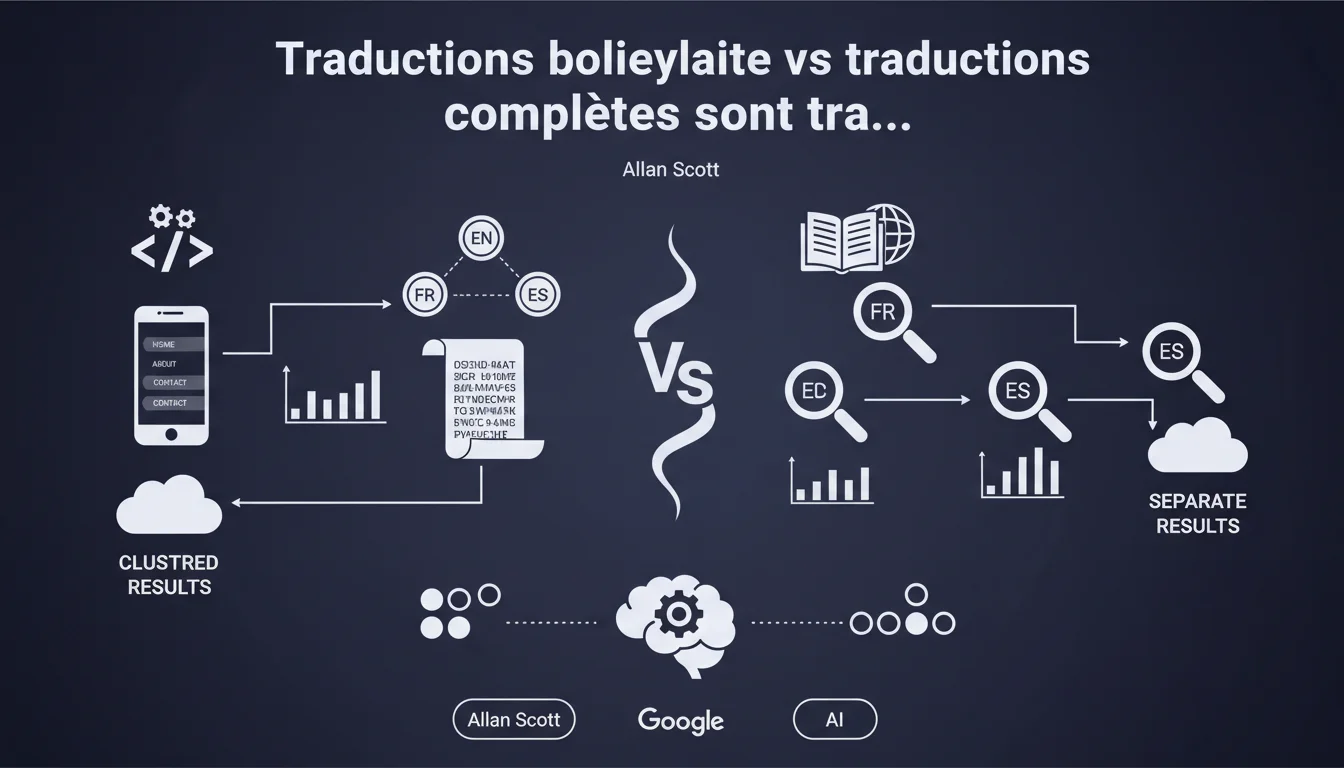
Google distingue les traductions d'éléments d'interface (menus, navigation) des traductions de contenu éditorial. Les boilerplates traduits sont regroupés dans un même cluster de déduplication, tandis que les contenus traduits restent séparés car ils ciblent des requêtes linguistiques distinctes. Cette différenciation impacte directement l'indexation et le positionnement des sites multilingues.
Ce qu'il faut comprendre
Qu'entend Google par traduction de boilerplate ?
Le boilerplate désigne tous les éléments structurels et navigationnels d'un site : menus de navigation, footer, barres latérales, labels de formulaires, boutons d'action. Ces éléments se répètent à l'identique sur des dizaines ou centaines de pages.
Lorsque vous traduisez simplement ces éléments d'une langue à l'autre sans modifier le contenu principal, Google considère que les pages sont quasi-identiques. Le moteur les regroupe alors dans un même cluster de déduplication — une seule version sera privilégiée dans les résultats de recherche.
Pourquoi les traductions complètes échappent-elles à ce regroupement ?
Une traduction complète inclut non seulement le boilerplate, mais surtout le contenu éditorial principal : articles, descriptions produits, guides. Ce contenu répond à des requêtes linguistiquement différentes, même si l'intention de recherche reste similaire.
Un utilisateur francophone cherchant "meilleur smartphone 2023" et un anglophone tapant "best smartphone 2023" ont la même intention, mais Google comprend que chaque version linguistique cible un public distinct. Les pages restent donc dans des clusters séparés et peuvent toutes se positionner dans leurs marchés respectifs.
Quelles sont les implications pour l'indexation multilingue ?
Cette distinction impacte directement la stratégie de déploiement international. Si vous vous contentez de traduire menus et navigation en gardant le contenu principal identique ou quasi-identique, Google va probablement cannibaliser vos versions linguistiques entre elles.
- Les pages avec boilerplate traduit uniquement sont clustérisées ensemble — une seule version s'affiche
- Les pages avec contenu éditorial traduit restent dans des clusters distincts — chaque version peut ranker
- Les balises hreflang ne suffisent pas à forcer Google à indexer toutes les versions si le contenu est jugé redondant
- La qualité de la traduction compte : une traduction automatique médiocre peut être rejetée même si complète
Avis d'un expert SEO
Cette distinction est-elle vraiment nouvelle pour les praticiens ?
Soyons honnêtes : cette déclaration officialise ce que beaucoup d'entre nous observent depuis des années sur le terrain. Google a toujours privilégié la valeur ajoutée du contenu plutôt que les variations cosmétiques. Ce qui change, c'est la confirmation explicite du mécanisme de clustering appliqué différemment selon le type de traduction.
Dans la pratique, j'ai vu des sites e-commerce multilingues avec des fiches produits quasi-identiques (seul le boilerplate changeait) subir une cannibalisation sévère entre versions linguistiques. Google choisissait arbitrairement une version — souvent .com plutôt que .fr ou .de — même avec des hreflang parfaitement configurées.
Quelles zones d'ombre persistent malgré cette clarification ?
Google reste délibérément vague sur plusieurs points critiques. Quel pourcentage du contenu doit être traduit pour échapper au clustering ? 50% ? 80% ? [À vérifier] — aucune métrique précise n'est fournie.
Autre flou : comment Google évalue-t-il la qualité sémantique d'une traduction ? Une traduction automatique post-éditée est-elle suffisante, ou faut-il une traduction humaine native ? La déclaration ne le précise pas. Sur des sites clients, j'ai observé que des traductions DeepL de qualité performaient correctement, mais ce n'est pas une règle absolue.
Dans quels cas cette logique de clustering échoue-t-elle ?
La géolocalisation de l'utilisateur peut court-circuiter cette logique. Google force parfois l'affichage d'une version locale même si elle est clustérisée, créant des incohérences dans les SERPs selon l'IP de connexion.
Les sites avec contenus géo-spécifiques (prix en devises locales, disponibilité régionale, réglementations) échappent naturellement au clustering, même si le contenu éditorial reste proche. Google détecte ces différences structurelles comme des signaux de pertinence locale.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site multilingue existant ?
Commencez par un ratio contenu traduit vs boilerplate sur vos templates principaux. Prenez 5-10 pages types (homepage, catégorie, fiche produit, article) et calculez le pourcentage de texte unique traduit par rapport aux éléments structurels répétés.
Vérifiez ensuite dans Search Console si toutes vos versions linguistiques sont effectivement indexées et génèrent des impressions. Un déséquilibre massif (ex: .com avec 80% des impressions, .fr et .de à 10% chacun) signale probablement un clustering non désiré.
Contrôlez également les patterns de cannibalisation : si pour une même requête traduite, Google alterne entre vos versions linguistiques au fil des jours, c'est un signal qu'il ne les différencie pas suffisamment.
Quelles actions correctives mettre en œuvre concrètement ?
Pour les sites e-commerce avec fiches produits standardisées, enrichissez les descriptions dans chaque langue plutôt que de traduire mot-à-mot. Ajoutez des cas d'usage locaux, des références culturelles adaptées, des témoignages clients dans la langue cible.
Sur les sites éditoriaux, ne vous contentez jamais de traduire un article — localisez-le. Adaptez les exemples, citez des sources locales, modifiez l'angle si nécessaire. Un article sur "les meilleures pratiques fiscales" ne peut pas être une simple traduction entre France et Belgique.
Utilisez structured data multilingue pour renforcer les signaux de différenciation : avis clients dans la langue locale, événements géolocalisés, FAQ adaptées aux questions régionales.
- Calculer le ratio contenu unique / boilerplate sur vos templates principaux
- Auditer l'indexation et les impressions par version linguistique dans Search Console
- Identifier les patterns de cannibalisation entre versions via rank tracking multilingue
- Enrichir les contenus traduits avec des éléments culturellement spécifiques
- Implémenter des structured data localisées (avis, FAQ, événements)
- Tester la qualité des traductions automatiques vs humaines sur des pages stratégiques
- Monitorer l'évolution de l'indexation après modifications pendant 4-6 semaines minimum
❓ Questions frequentes
Les balises hreflang suffisent-elles à éviter le clustering de pages traduites ?
Faut-il traduire 100% du contenu ou un pourcentage suffit-il ?
Une traduction automatique (DeepL, Google Translate) est-elle pénalisante ?
Comment détecter si mes versions linguistiques sont clustérisées ?
Le duplicate content entre versions linguistiques est-il pénalisant ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.