Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Comment Google jongle-t-il avec 40 signaux pour choisir l'URL canonique ?
- □ Clustering et canonicalisation : Google fait-il vraiment la différence entre ces deux processus ?
- □ Le rel canonical joue-t-il un double rôle dans l'algorithme de Google ?
- □ Que se passe-t-il quand vos signaux de canonicalisation se contredisent ?
- □ Comment Google choisit-il réellement entre HTTP et HTTPS dans ses résultats ?
- □ Pourquoi vos redirections multiples empêchent-elles Google de choisir la version HTTPS ?
- □ Google traite-t-il vraiment différemment les traductions de boilerplate et de contenu ?
- □ Hreflang fonctionne-t-il indépendamment du clustering de contenu dupliqué ?
- □ Google va-t-il vraiment faciliter le traitement du hreflang pour les sites fiables ?
- □ X-default est-il vraiment un signal canonique comme les autres ?
- □ Les pages en soft 404 sont-elles vraiment les seules à créer des clusters problématiques ?
- □ Pourquoi un message d'erreur explicite peut-il sauver votre crawl budget ?
- □ Les redirections JavaScript vers des pages d'erreur sont-elles vraiment prises en compte par Google ?
- □ Pourquoi un no-index supprime-t-il une page plus vite qu'une erreur 404 ou 410 ?
- □ Un rel canonical vide peut-il vraiment supprimer tout votre site de l'index Google ?
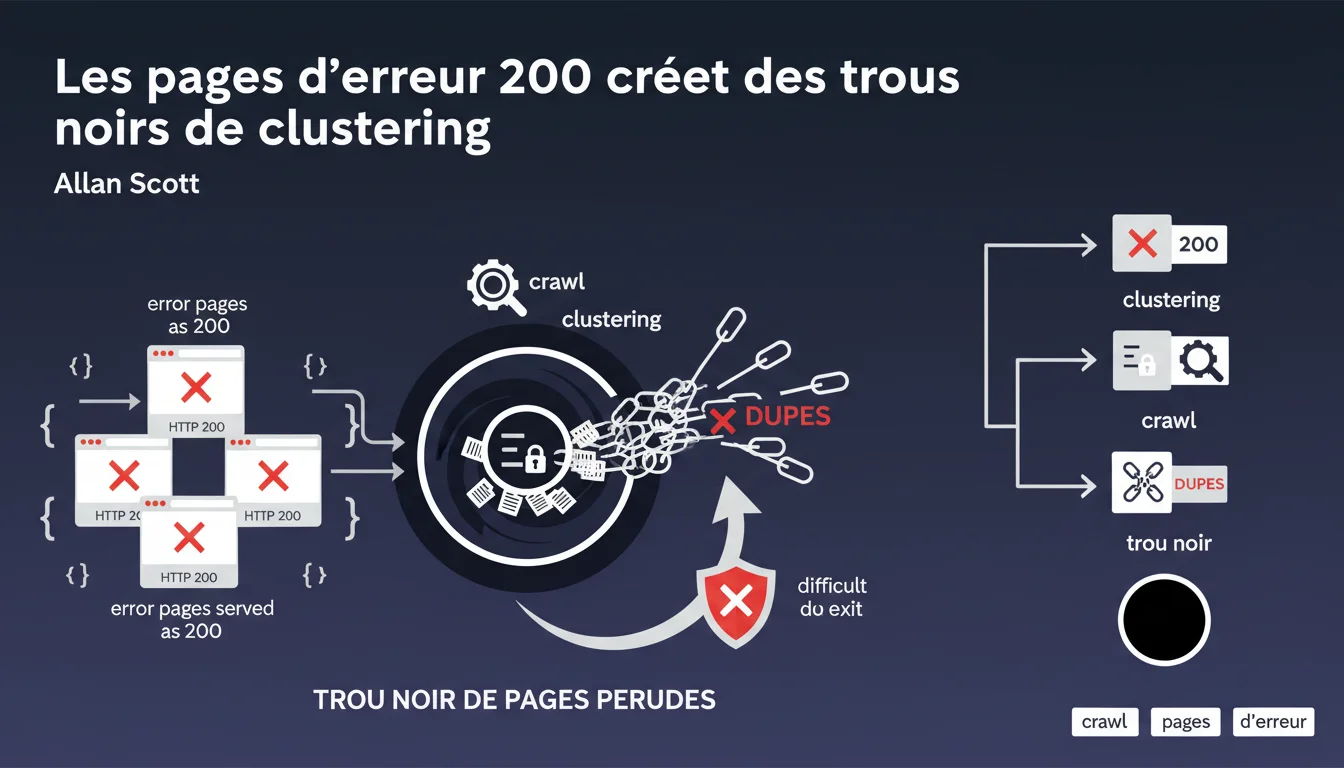
Les pages d'erreur servies en HTTP 200 se regroupent entre elles via un système de checksum, créant des clusters de duplication. Une fois piégées dans ces clusters, les pages deviennent quasi invisibles pour le crawl qui évite les contenus dupliqués, formant un 'trou noir' dont elles sortent difficilement.
Ce qu'il faut comprendre
Qu'est-ce qu'une page d'erreur 200 exactement ?
Une page d'erreur 200 est une aberration technique : une page qui affiche un message d'erreur (404, 500, etc.) mais renvoie un code HTTP 200 (succès). Techniquement, vous dites à Google 'tout va bien' alors que la page est cassée.
Ce scénario se produit fréquemment sur des sites e-commerce mal configurés, des CMS avec des redirections foireuses, ou des templates qui affichent 'Produit introuvable' sans changer le code de statut. Pour le moteur, c'est du contenu valide à indexer.
Comment fonctionne le clustering par checksum ?
Google utilise des checksums (empreintes numériques) pour identifier les contenus similaires ou identiques. Les pages d'erreur 200 partagent souvent le même template — donc la même structure, le même texte générique.
Résultat ? Elles se retrouvent clustérisées ensemble. Le moteur détecte la duplication massive et applique son filtre anti-spam : une seule URL représente le cluster, les autres sont désindexées de facto.
Pourquoi parle-t-on de 'trou noir' ?
Le terme est brutal mais juste. Une fois qu'une page tombe dans un cluster de duplication, le crawl budget s'effondre pour ce groupe. Google évite activement de recrawler ces URLs détectées comme dupes.
Même si vous corrigez le problème plus tard, la page reste marquée. Le robot ne repasse pas — ou très rarement. Vous devez forcer la réindexation manuellement, et encore, sans garantie si le checksum reste suspect.
- Pages d'erreur 200 : erreurs techniques servies avec un code HTTP succès
- Clustering par checksum : regroupement automatique des contenus identiques ou très similaires
- Trou noir de crawl : les URLs piégées dans ces clusters ne sont plus crawlées régulièrement
- Impact indexation : désindexation progressive des pages affectées, même si elles sont corrigées
- Détection difficile : ces problèmes passent souvent inaperçus car le code 200 masque l'erreur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. On observe ce phénomène depuis des années sur les sites e-commerce mal fichus. Des centaines de pages produits 'indisponibles' qui renvoient 200, et six mois plus tard, l'indexation s'effondre sans raison apparente.
Ce qui est nouveau, c'est la confirmation officielle du mécanisme : le clustering par checksum. Avant, on supposait un filtre qualité générique. Maintenant on sait que c'est un processus automatisé basé sur les empreintes de contenu.
Quelles nuances faut-il apporter ?
La déclaration manque de détails sur les seuils de déclenchement. Combien de pages d'erreur 200 faut-il pour créer un cluster toxique ? 10 ? 100 ? 1000 ? [À vérifier] — Google reste flou sur ce point crucial.
Autre zone grise : quelle proportion de contenu dupliqué déclenche le checksum ? Si deux pages d'erreur ont 80% de texte commun mais 20% différent (produit A vs produit B dans le titre), sont-elles clustérisées quand même ? Probablement, mais là encore, aucune métrique précise.
Dans quels cas ce problème affecte-t-il réellement le ranking ?
Soyons clairs : si vous avez 5 pages d'erreur 200 sur un site de 500 URLs, l'impact sera négligeable. Le clustering ne se déclenche pas sur quelques unités isolées.
Le danger réel concerne les sites avec des centaines ou milliers de pages d'erreur mal gérées — marketplace, e-commerce saisonnier, sites d'annonces. Là, vous créez un cluster massif qui pollue votre profil de crawl et dilue votre budget. Les pages saines à côté trinquent par ricochet.
Impact pratique et recommandations
Comment détecter les pages d'erreur 200 sur mon site ?
Première étape : audit technique complet. Utilisez Screaming Frog ou Sitebulb en mode 'Full Spider' avec analyse des codes de statut. Filtrez les URLs qui renvoient 200 mais contiennent des expressions comme 'not found', 'indisponible', 'erreur', '404'.
Deuxième check : Search Console, rapport Couverture. Regardez les URLs indexées mais avec trafic zéro depuis 6+ mois. Souvent, ce sont des pages d'erreur 200 clustérisées que Google a abandonnées.
Que faire si j'ai déjà des pages piégées dans ces clusters ?
Corriger le code de statut ne suffit pas. Vous devez modifier le contenu pour casser le checksum. Changez le template, ajoutez du texte unique, restructurez le HTML — bref, rendez la page méconnaissable par rapport à l'ancienne version.
Ensuite, forcez la réindexation via Search Console (fonction 'Demander une indexation'). Mais attention : avec des centaines d'URLs, vous dépassez vite la limite quotidienne. Priorisez les pages à fort potentiel et laissez le recrawl naturel gérer le reste — en espérant.
Quelles erreurs éviter absolument ?
- Ne jamais servir de contenu d'erreur avec un code 200 — configurez correctement vos 404, 410, 503
- Ne pas utiliser le même template générique pour toutes vos pages d'erreur — variez le contenu si possible
- Éviter les redirections 301 massives vers une page d'erreur 200 — c'est pire que tout
- Ne pas ignorer les soft-404 signalées dans Search Console — Google a déjà détecté le problème
- Ne jamais laisser des pages d'erreur indexées — robots.txt, noindex, ou suppression pure et simple
Les pages d'erreur 200 sont un poison lent pour votre crawl budget. Elles créent des clusters de duplication dont vous sortez difficilement. La prévention est simple : configurez correctement vos codes HTTP. La correction est pénible : modification de contenu + réindexation forcée.
Si vous gérez un site de taille importante avec des milliers d'URLs, l'audit et la correction de ces erreurs peuvent rapidement devenir un chantier technique complexe. Dans ce contexte, l'accompagnement d'une agence SEO spécialisée peut s'avérer précieux pour identifier l'étendue du problème, prioriser les corrections et mettre en place une stratégie de réindexation efficace sans griller votre crawl budget.
❓ Questions frequentes
Un code 404 personnalisé avec design soigné est-il concerné par ce problème ?
Les soft-404 détectés par Search Console sont-ils la même chose que les pages d'erreur 200 ?
Combien de temps faut-il pour qu'une page corrigée sorte du cluster ?
Les pages d'erreur 200 peuvent-elles affecter le ranking des pages saines ?
Faut-il supprimer les URLs des pages d'erreur 200 du sitemap XML ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.