Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Comment Google jongle-t-il avec 40 signaux pour choisir l'URL canonique ?
- □ Clustering et canonicalisation : Google fait-il vraiment la différence entre ces deux processus ?
- □ Le rel canonical joue-t-il un double rôle dans l'algorithme de Google ?
- □ Que se passe-t-il quand vos signaux de canonicalisation se contredisent ?
- □ Comment Google choisit-il réellement entre HTTP et HTTPS dans ses résultats ?
- □ Pourquoi vos redirections multiples empêchent-elles Google de choisir la version HTTPS ?
- □ Google traite-t-il vraiment différemment les traductions de boilerplate et de contenu ?
- □ Hreflang fonctionne-t-il indépendamment du clustering de contenu dupliqué ?
- □ Google va-t-il vraiment faciliter le traitement du hreflang pour les sites fiables ?
- □ X-default est-il vraiment un signal canonique comme les autres ?
- □ Les pages d'erreur 200 créent-elles vraiment des trous noirs de clustering ?
- □ Pourquoi un message d'erreur explicite peut-il sauver votre crawl budget ?
- □ Les redirections JavaScript vers des pages d'erreur sont-elles vraiment prises en compte par Google ?
- □ Pourquoi un no-index supprime-t-il une page plus vite qu'une erreur 404 ou 410 ?
- □ Un rel canonical vide peut-il vraiment supprimer tout votre site de l'index Google ?
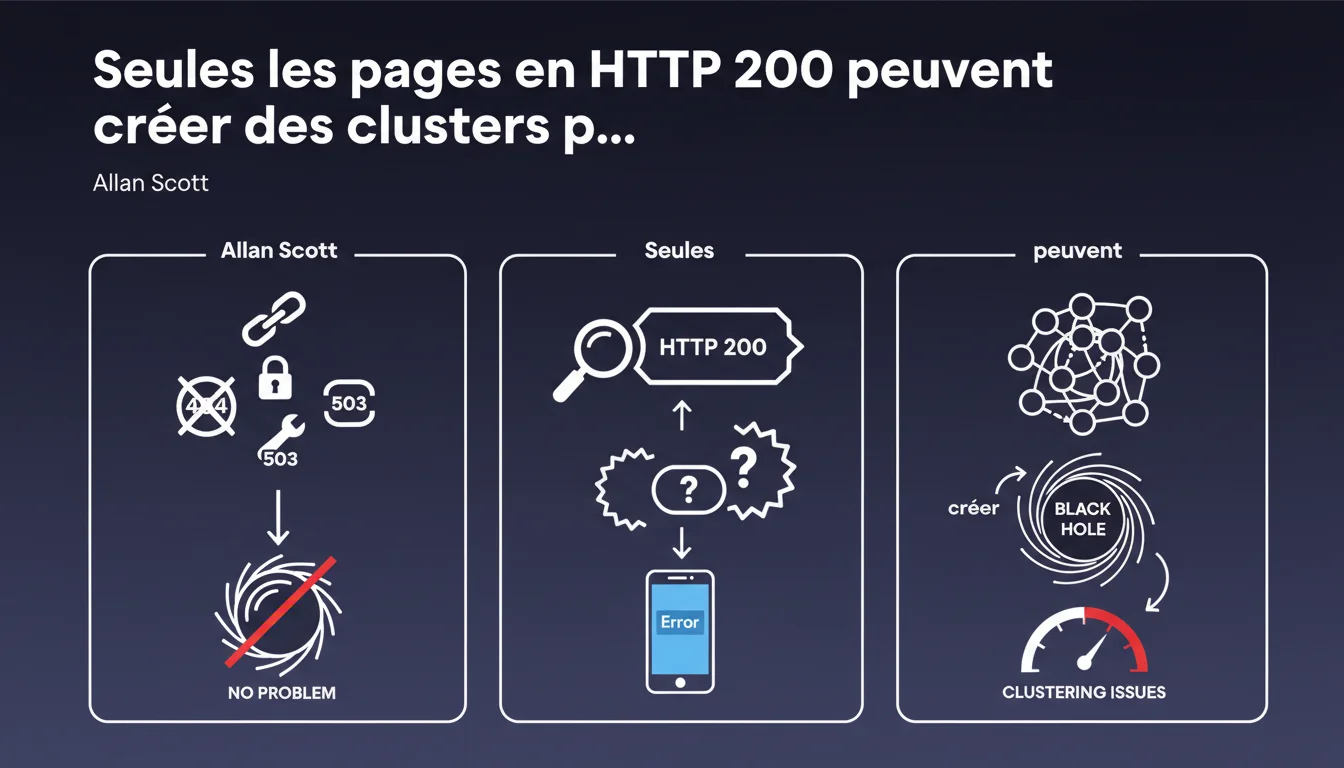
Google affirme que seules les pages renvoyant un code HTTP 200 avec du contenu d'erreur créent des « trous noirs » dans l'indexation. Les vraies erreurs servies avec les bons codes (404, 403, 503) ne posent aucun problème de clustering. Le risque se concentre donc sur les soft 404, ces pages qui affirment « tout va bien » alors qu'elles affichent une erreur.
Ce qu'il faut comprendre
Qu'est-ce qu'un « trou noir » d'indexation exactement ?
Un trou noir d'indexation, c'est un ensemble de pages qui absorbent du crawl budget sans apporter de valeur. Google les explore, les indexe parfois, mais elles diluent la pertinence du site. Le moteur perd du temps sur des URL inutiles au lieu de se concentrer sur le contenu stratégique.
Ces trous noirs se forment surtout quand un site génère des pages vides, des facettes de filtres sans contenu unique, ou des pages d'erreur mal configurées. Le crawler détecte du contenu, l'indexe, mais l'utilisateur tombe sur une impasse.
Pourquoi les vraies erreurs HTTP ne posent-elles pas problème ?
Parce qu'elles envoient un signal clair à Googlebot : cette page n'existe pas ou n'est pas accessible. Un 404 dit « rien à voir ici », un 403 dit « interdit », un 503 dit « temporairement hors service ». Le crawler comprend, enregistre l'info, et passe à autre chose.
Ces codes HTTP permettent à Google de nettoyer son index efficacement. Une page en 404 disparaît progressivement de l'index. Une page en 503 reste en file d'attente pour un recrawl ultérieur. Aucun cluster fantôme ne se forme.
En quoi les soft 404 sont-ils plus toxiques ?
Un soft 404, c'est une page qui renvoie un code 200 OK alors qu'elle devrait signaler une erreur. Google voit un statut positif, indexe la page, mais découvre un contenu vide ou générique : « Aucun résultat », « Page non trouvée », « Oups, erreur ».
Le problème ? Le moteur ne sait pas immédiatement qu'il s'agit d'une erreur. Il traite ces pages comme du contenu légitime, ce qui crée des clusters de pages inutiles. Résultat : crawl budget gaspillé, dilution du PageRank interne, signaux de qualité dégradés.
- Les codes HTTP corrects (404, 403, 503) ne créent pas de problèmes de clustering
- Les soft 404 (code 200 avec contenu d'erreur) génèrent des trous noirs d'indexation
- Le crawler perd du temps sur des pages qui semblent valides mais ne le sont pas
- La clé : renvoyer le bon code HTTP au bon moment
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. Depuis des années, on observe que les sites avec des soft 404 massifs souffrent de problèmes d'indexation chroniques. Des milliers de pages « fantômes » apparaissent dans la Search Console, sans trafic, sans positionnement, mais elles restent dans l'index.
Les audits techniques révèlent souvent des facettes de filtres, des pages de recherche interne vides, ou des variantes d'URL générées dynamiquement — toutes en 200 OK. Google les crawle en boucle, les indexe, et le site perd en efficacité. Corriger ces soft 404 avec les bons codes HTTP fait souvent remonter les métriques de crawl et d'indexation en quelques semaines.
Pourquoi Google insiste-t-il autant sur ce point maintenant ?
Parce que les sites modernes génèrent de plus en plus de pages dynamiques. Les SPA (Single Page Applications), les sites e-commerce avec filtres complexes, les plateformes de contenu généré par les utilisateurs… tous créent des URL en cascade dont beaucoup sont vides ou dupliquées.
Google veut éviter de crawler et d'indexer des millions de pages inutiles. C'est une question de coût de crawl pour lui, et de qualité d'indexation pour nous. En clarifiant ce point, Google pousse les développeurs à mieux gérer les codes HTTP dès la conception.
Y a-t-il des cas limites où cette règle se complique ?
Oui — et c'est là que ça coince. Prenons les pages de résultats de recherche interne : si aucun résultat n'est trouvé, faut-il renvoyer un 404 ou un 200 avec « Aucun résultat » ? Techniquement, la page existe, mais elle n'a pas de valeur pour l'index.
[À vérifier] Google ne donne pas de directive précise sur ces cas ambigus. La meilleure pratique semble être de renvoyer un 200 avec un noindex en meta robots, ce qui évite l'indexation sans casser l'expérience utilisateur. Mais ça reste une zone grise.
Impact pratique et recommandations
Comment identifier les soft 404 sur mon site ?
Première étape : la Search Console. Ouvre la section « Couverture » ou « Pages » et filtre par « Exclues ». Google signale souvent les soft 404 détectés automatiquement. Mais il en rate beaucoup.
Deuxième étape : un crawl complet avec Screaming Frog, Oncrawl ou Botify. Filtre les pages en 200 OK avec peu de contenu (moins de 200 mots, peu de liens internes, balise title générique). Croise ces données avec les analytics : si elles n'ont aucun trafic, c'est mauvais signe.
Troisième étape : vérifie les logs serveur. Repère les URL crawlées massivement par Googlebot mais jamais visitées par des utilisateurs réels. Ce sont souvent des pages fantômes que le moteur explore en boucle.
Quelles erreurs éviter absolument ?
Ne renvoie jamais un 200 OK sur une page d'erreur. Si un produit n'existe plus, c'est un 410 (Gone) ou un 301 vers une alternative. Si une catégorie est vide temporairement, c'est un 503 (Service Unavailable) ou un 200 avec noindex.
Ne crée pas de pages « Aucun résultat » ou « Erreur 404 personnalisée » en 200 OK. Même si c'est joli pour l'utilisateur, c'est toxique pour le SEO. Le serveur doit renvoyer le bon code HTTP en même temps que le contenu personnalisé.
Ne laisse pas traîner des milliers de facettes de filtres en 200 OK. Utilise les canonical, noindex, ou robots.txt pour empêcher leur indexation. Si elles sont utiles pour les utilisateurs, garde-les accessibles, mais bloque-les côté crawl.
Quelle stratégie mettre en place pour assainir l'indexation ?
- Audite ton site avec un crawler : identifie toutes les pages en 200 OK avec peu de contenu
- Corrige les codes HTTP : 404 pour les pages supprimées, 410 pour les produits définitivement retirés, 503 pour les indisponibilités temporaires
- Ajoute des noindex en meta robots sur les pages utiles mais non indexables (recherche interne, filtres, variations d'URL)
- Redirige en 301 les anciennes URL vers des alternatives pertinentes quand c'est possible
- Surveille la Search Console : vérifie que les soft 404 signalés disparaissent progressivement
- Mets en place un monitoring mensuel pour détecter de nouveaux soft 404 avant qu'ils ne se multiplient
❓ Questions frequentes
Un soft 404 peut-il pénaliser le référencement global du site ?
Faut-il supprimer les pages en soft 404 de la Search Console ?
Une page en 200 avec noindex crée-t-elle un cluster problématique ?
Les pages en 503 restent-elles longtemps dans l'index ?
Comment savoir si mes corrections de soft 404 fonctionnent ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.