Official statement
Other statements from this video 7 ▾
- □ Pourquoi votre site peut-il être invisible pour Googlebot alors qu'il s'affiche parfaitement dans votre navigateur ?
- □ Comment vérifier si Googlebot crawle vraiment votre contenu JavaScript ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment s'inquiéter de chaque erreur de crawl remontée dans la Search Console ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment analyser vos logs serveur pour optimiser le crawl de Google ?
- □ Pourquoi vos pages n'entrent-elles pas dans Google Search malgré tous vos efforts SEO ?
Martin Splitt reminds us that many bots impersonate Googlebot in logs. These third-party scrapers can generate unusual requests and skew your analytics. The only reliable solution: systematically verify authenticity via reverse DNS or Search Console.
What you need to understand
Why do so many fake Googlebots circulate on the web?
The Googlebot user-agent is trivially easy to spoof. Any script can declare "I am Googlebot" in its HTTP headers. Malicious scrapers exploit this loophole for two main reasons: to bypass anti-bot protections (many sites allow Googlebot by default) and to hide their true identity while scraping at scale.
The problem becomes critical when these fake bots generate thousands of requests. Your technical team panics seeing a "Googlebot" crawling 50,000 pages per day, when the real Google has never behaved that way on your site.
What concrete risks does this pose to your SEO analysis?
If you base your decisions on polluted logs, you'll draw wrong conclusions. A massive crawl wrongly attributed to Googlebot might make you believe Google is finally exploring your deep pages — when it's actually a competitor scraping your catalog.
Another common case: you detect 404 or 500 errors in the "Googlebot" logs. You fix it urgently... except those requests came from a scraper testing fake URLs. Result: wasted time and squandered resources.
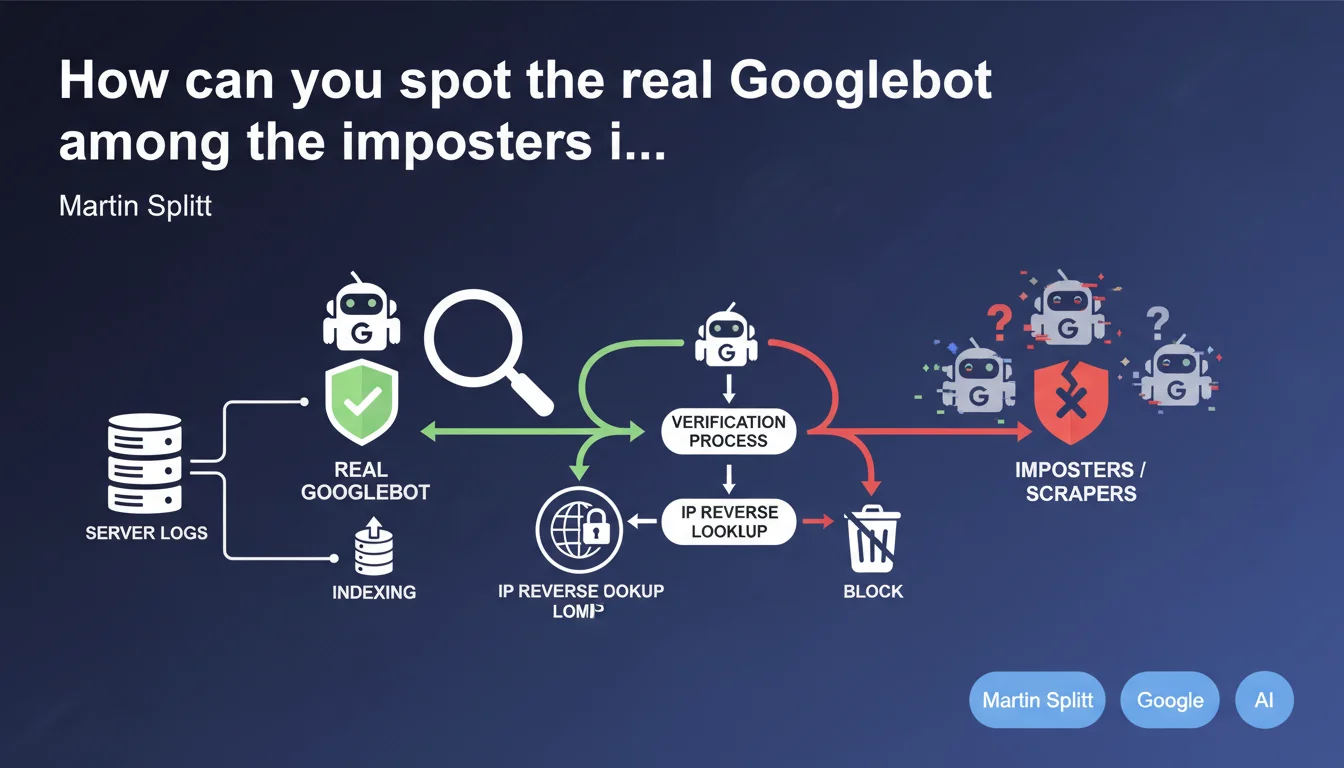
How do you verify the authenticity of a Googlebot in your logs?
Google recommends two official methods. First: reverse DNS lookup — you verify that the IP resolves to *.googlebot.com or *.google.com, then perform a DNS forward lookup to confirm that this domain points back to the same IP. This is the most reliable method on the server side.
Second: check the Search Console under "Crawl Statistics". If your firewall blocks an IP claiming to be Googlebot, cross-reference it with the timestamps and URLs actually crawled by Google. A glaring discrepancy? It's an imposter.
- Fake Googlebots exploit how easy it is to spoof HTTP user-agents
- They distort your crawl metrics and can mask scraping activities
- Only DNS verification or Search Console guarantee authenticity
- Never rely solely on user-agents in HTTP headers
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, and it's actually an understatement. Every technical audit I conduct reveals massive log pollution. Some e-commerce sites see 40 to 60% of their "Googlebot traffic" actually coming from scrapers (Chinese, Russian, or aggregation services in disguise).
Real Googlebot has recognizable patterns: it respects crawl budget, avoids infinite loops, focuses on strategic sections. A fake bot will often crawl absurd URLs, ignore robots.txt, or hammer a category for hours. Let's be honest — if your Googlebot crawls 500 pages per second, it's an imposter.
What nuances should be added to this recommendation?
Martin Splitt says "don't worry about unusual requests". That's true... up to a point. If these fake bots saturate your server, you must act. An aggressive scraper can degrade response times for the real Googlebot, which indirectly impacts your crawl budget.
Another limitation: DNS verification takes time and can't be done in real-time on every request. On a high-traffic site, you'll need to script this verification and maintain a whitelist of validated IPs. [To verify] — Does Google publish an official list of Googlebot IP ranges? Officially no, but various lists circulate.
Finally, be careful with log analysis tools like Oncrawl or Botify: most filter by user-agent by default. If you don't correct this bias, your reports are skewed from the start.
In what cases doesn't this rule apply?
If you're using a CDN like Cloudflare with bot management enabled, some filtering is already done upstream. Cloudflare maintains its own list of validated Googlebot IPs and filters imposters automatically — but not 100%.
Very large sites (millions of pages) with dedicated DevOps teams can afford advanced detection systems based on behavior (machine learning, crawl pattern analysis). For others? The reverse DNS method remains the most accessible.
Practical impact and recommendations
What should you do concretely to clean your logs?
First step: audit your server logs over a representative period (at least 30 days). Extract all requests with the Googlebot user-agent, then isolate the IPs. Run a reverse/forward DNS verification script on each unique IP. You'll quickly spot the imposters.
Next, ban these IPs via your .htaccess, nginx.conf, or your WAF. Warning — don't block by user-agent, that's pointless since that's what's being spoofed. Block by IP address confirmed as fake.
What mistakes should you avoid when implementing verification?
Classic mistake: believing that a complex or recent user-agent is automatically legitimate. Modern scrapers copy the latest Googlebot user-agents for mobile or desktop to the letter. It proves nothing.
Another trap: trusting your hosting provider's stats. Many server-side analytics tools aggregate by user-agent without DNS validation. You see "Googlebot crawled 10,000 pages", but it's a mix of legitimate and fake IPs.
And that's where it gets tricky — some colleagues block entire IP ranges out of fear, and end up excluding a newly-added legitimate Google IP. Result: the real Googlebot can't crawl, and you lose visibility without understanding why.
How do you automate this verification at scale?
For a high-volume site, scripting DNS verification is essential. Python with socket or dnspython libraries does the job. You create a dynamic whitelist of validated Googlebot IPs, updated weekly.
Integrate this whitelist into your WAF or reverse proxy. Requests from non-validated IPs with a Googlebot user-agent are either blocked, served with a delay (rate limiting), or redirected to a honeypot page to identify the scraper.
- Audit your logs over at least 30 days to identify suspicious patterns
- Use a DNS reverse/forward verification script on all "Googlebot" IPs
- Ban by IP (not by user-agent) confirmed imposters
- Cross-reference your logs with Search Console data to validate consistency
- Automate your Googlebot whitelist updates via weekly script
- Configure rate limiting differentiated for non-validated IPs
- Document legitimate Google IPs in a file shared with the DevOps team
❓ Frequently Asked Questions
Peut-on se fier uniquement au user-agent pour identifier Googlebot ?
Quels sont les patterns typiques d'un faux Googlebot dans les logs ?
Comment croiser les données de logs avec la Search Console ?
Est-il risqué de bannir des IPs sans vérification approfondie ?
Les CDN comme Cloudflare filtrent-ils automatiquement les faux Googlebots ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 13/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.