Does the 15 MB Googlebot crawl limit really kill your indexation, and how can you fix it?
Martin Splitt
🎥 YouTube
Mar 2026
★★★
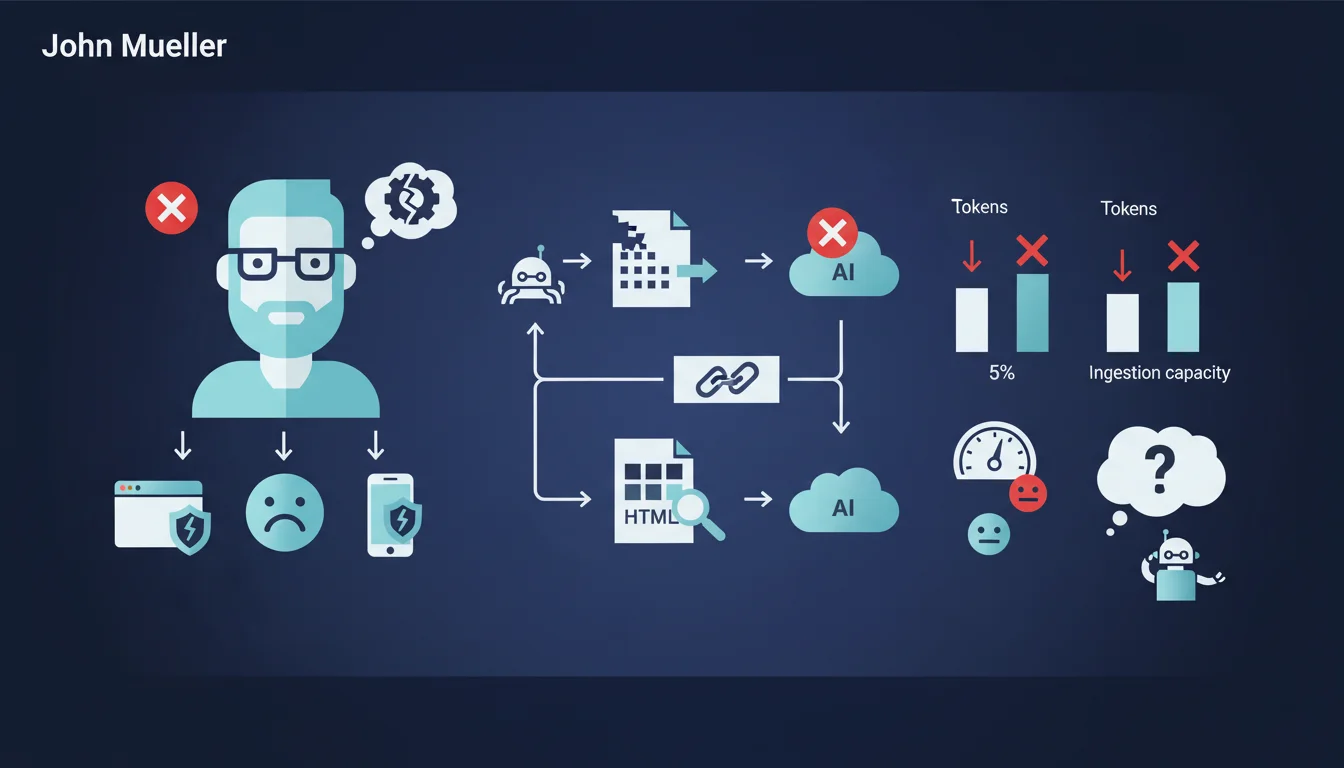
Googlebot récupère par défaut 15 mégaoctets de contenu brut (raw bytes) par URL, puis s'arrête. Cette limite de 15 Mo s'applique à chaque UR...