Official statement
Other statements from this video 13 ▾
- □ Les mauvaises traductions peuvent-elles pénaliser l'ensemble de votre site multilingue ?
- □ Le contenu dupliqué sur les fiches produits est-il vraiment sans danger pour votre référencement ?
- □ Faut-il traduire toutes vos pages ou concentrer vos efforts sur les plus stratégiques ?
- □ Faut-il vraiment désactiver le ciblage géographique dans Search Console pour un site international ?
- □ Google indexe-t-il vraiment le texte masqué dans votre code HTML ?
- □ Faut-il déployer ses optimisations SEO en une seule fois plutôt que progressivement ?
- □ Pas de cache Google sur ma page : est-ce un signal d'alarme pour mon indexation ?
- □ Googlebot ignore-t-il vraiment toutes les permissions du navigateur lors du crawl ?
- □ Faut-il vraiment utiliser l'API Indexing de Google pour accélérer l'indexation de vos contenus ?
- □ Le score Page Experience est-il vraiment indispensable pour apparaître dans Top Stories ?
- □ Google attribue-t-il vraiment un score EAT à votre site ?
- □ Pagination SEO : faut-il privilégier les liens séquentiels ou multiples pages ?
- □ Les Core Web Vitals mesurés uniquement sur Chrome : faut-il s'inquiéter de la représentativité ?
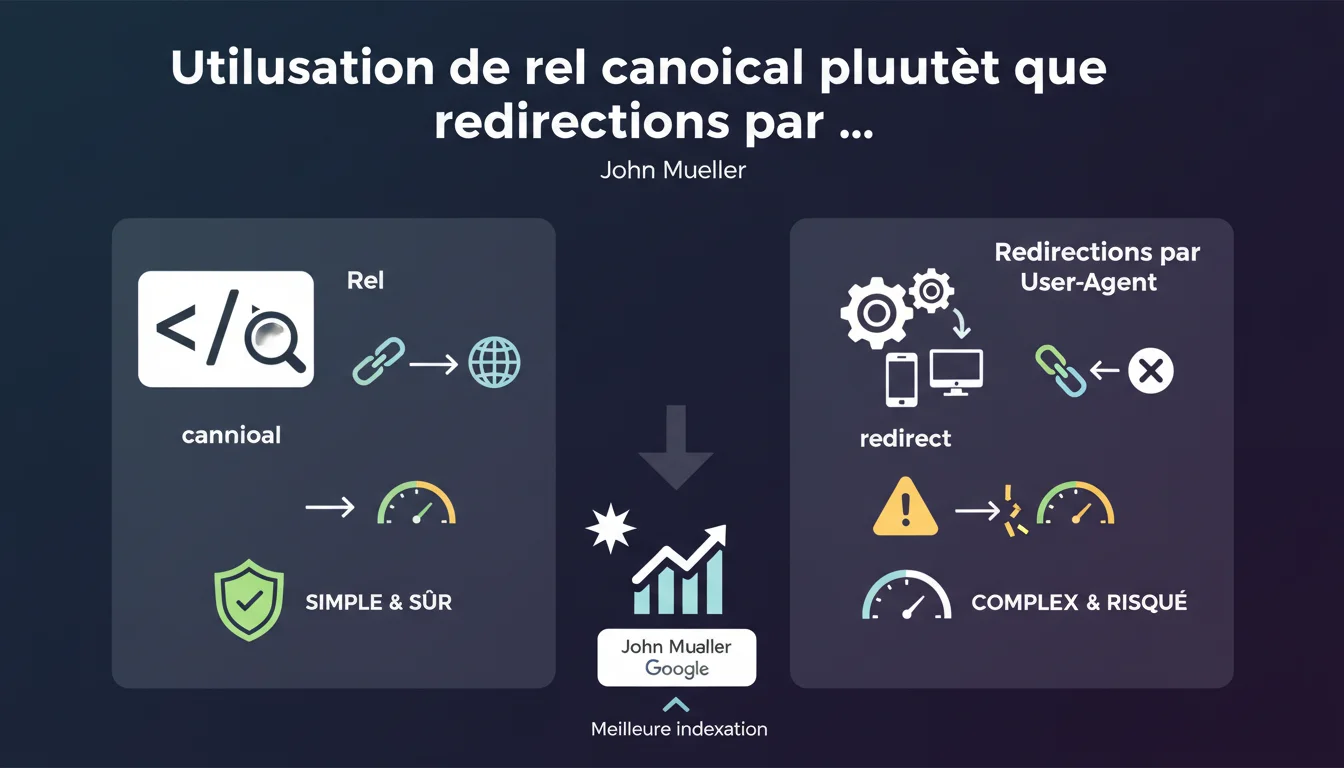
Google recommends using the rel=canonical tag instead of user-agent based 301 redirects to manage unindexed pages that receive backlinks. While user-agent redirects are technically acceptable, they are more fragile and complex to maintain. Canonicalization offers a simpler and less risky solution.
What you need to understand
Why is this question being raised in the first place? <\/h3>
The issue arises when you have unindexed pages that continue to receive external links. Typically: old URLs, campaign pages, unpublished content still referenced elsewhere.<\/p>
The temptation is strong to redirect Googlebot to an indexed page while allowing users to access the original content. Hence the idea of user-agent based conditional redirects. However, Google warns — this is not the best approach.<\/p>
What's the technical difference between these two methods? <\/h3>
A user-agent 301 redirect sends Googlebot to a different URL than the one users see. The server detects the bot and applies a specific rule. Functional, but it multiplies points of friction.<\/p>
The rel=canonical, on the other hand, simply indicates to Google which version should be authoritative. No server redirection. No conditional logic. The page remains normally accessible, and Google understands where to consolidate link signals.<\/p>
Why does Google prefer canonicalization? <\/h3>
Because it is less prone to implementation errors. User-agent redirects can block other legitimate bots, break monitoring, or create inconsistencies if the user-agent is misidentified.<\/p>
The rel=canonical is a signal — Google can choose to follow it or not, but it does not break anything. It’s a soft directive, not a technical wall.<\/p>
- rel=canonical: declarative signal, easy to implement, with no risk of blocking<\/li>
- User-agent redirects: technically acceptable but complex, risk of detection errors<\/li>
- Google always prioritizes technical simplicity to avoid shaky configurations<\/li>
- This recommendation specifically applies to unindexed pages receiving backlinks<\/li><\/ul>
SEO Expert opinion
Is this statement consistent with field observations? <\/h3>
Yes, absolutely. On paper, user-agent redirects work. But in practice, they generate false positives of cloaking in some automated audits, and complicate debugging when third-party crawlers (Ahrefs, Semrush, etc.) see one thing and Google sees another.<\/p>
Canonicals are more transparent. All crawlers see the same page, but with a clear indication for consolidation. This makes it easier to trace in logs, less ambiguous for technical teams.<\/p>
In what cases does this rule not apply? <\/h3>
If your unindexed page receives no external links, the question doesn’t even arise. You can simply block it with noindex or robots.txt without hassle.<\/p>
If you have a real need to serve fundamentally different content depending on the context (mobile vs desktop with separate URLs, for example), then yes, conditional redirects may make sense. But this is not the scenario discussed here.<\/p>
[To be verified]<\/strong> Google does not specify how it treats canonicals on pages already marked as noindex. Theoretically, noindex takes precedence — but if the page receives backlinks, it’s better to prioritize the canonical without noindex to preserve juice.<\/p> The rel=canonical is merely a consultative signal. Google may ignore it if it detects inconsistencies (content too different, looping canonicals, etc.). It is not an absolute guarantee of consolidation.<\/p> 301 redirects, on the other hand, are imperative. If you need a firm and definitive consolidation, the 301 remains the most powerful tool — but then for all users, not just for Googlebot.<\/p>What nuance should be added? <\/h3>
Practical impact and recommendations
What should you concretely do with unindexed pages that have backlinks? <\/h3>
First step: identify these pages. Cross-reference your Analytics data or logs with your link profile (Search Console, Ahrefs, Majestic). Any unindexed URL but cited elsewhere is a candidate.<\/p>
Next, add a Do not point to a page itself marked as noindex. Google will ignore the canonical. Do not create chains of canonicals (A → B → C) — always aim at the final version.<\/p> Avoid canonicals to pages that are semantically too distant. If Google considers the gap too large, it may ignore the signal and treat the pages separately.<\/p> In Search Console, go to Coverage and filter the "Excluded" pages with the reason "Duplicate, alternative URL with appropriate canonical tag". If your pages appear here, it’s a good sign.<\/p> Also, check in server logs that Googlebot does not trigger any 301/302 redirects on those URLs. If it does, you probably still have active user-agent rules that need cleaning up.<\/p><link rel="canonical" href="target-URL"><\/code> tag in the <head><\/code> of these pages. The target URL should be indexed, thematically relevant, and ideally already receiving traffic or links.<\/p>What mistakes should be avoided at all costs? <\/h3>
How to verify that everything is compliant? <\/h3>
❓ Frequently Asked Questions
Peut-on utiliser rel=canonical sur une page en noindex ?
Les redirections user-agent sont-elles considérées comme du cloaking ?
Que faire si Google ignore mon canonical ?
Faut-il supprimer les anciennes redirections 301 user-agent déjà en place ?
Le canonical transfère-t-il le PageRank comme une 301 ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 31/12/2021
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.