Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Les mauvaises traductions peuvent-elles pénaliser l'ensemble de votre site multilingue ?
- □ Le contenu dupliqué sur les fiches produits est-il vraiment sans danger pour votre référencement ?
- □ Faut-il traduire toutes vos pages ou concentrer vos efforts sur les plus stratégiques ?
- □ Faut-il vraiment désactiver le ciblage géographique dans Search Console pour un site international ?
- □ Google indexe-t-il vraiment le texte masqué dans votre code HTML ?
- □ Faut-il déployer ses optimisations SEO en une seule fois plutôt que progressivement ?
- □ Pas de cache Google sur ma page : est-ce un signal d'alarme pour mon indexation ?
- □ Googlebot ignore-t-il vraiment toutes les permissions du navigateur lors du crawl ?
- □ Faut-il vraiment utiliser l'API Indexing de Google pour accélérer l'indexation de vos contenus ?
- □ Le score Page Experience est-il vraiment indispensable pour apparaître dans Top Stories ?
- □ Google attribue-t-il vraiment un score EAT à votre site ?
- □ Pagination SEO : faut-il privilégier les liens séquentiels ou multiples pages ?
- □ Les Core Web Vitals mesurés uniquement sur Chrome : faut-il s'inquiéter de la représentativité ?
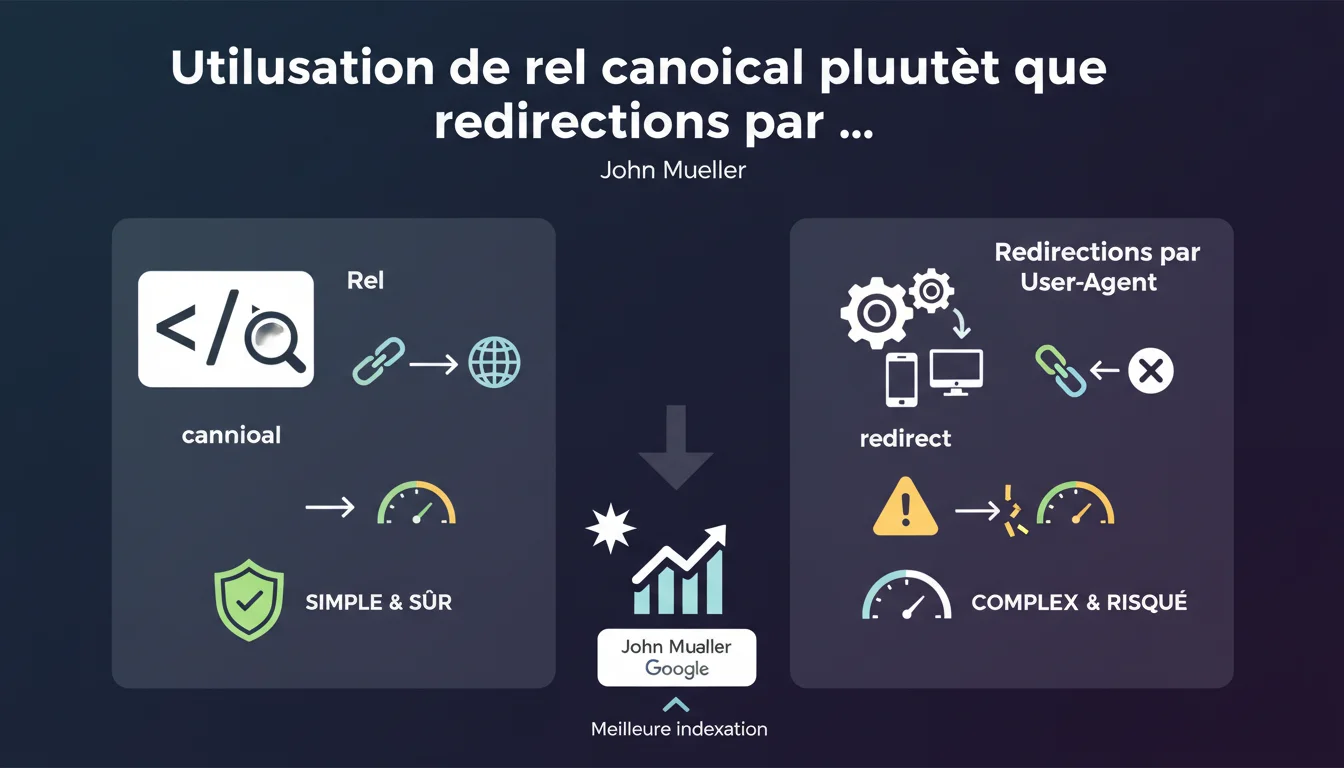
Google recommande d'utiliser la balise rel=canonical plutôt que des redirections 301 basées sur le user-agent pour gérer les pages non indexées qui reçoivent des backlinks. Les redirections par user-agent sont techniquement acceptables mais plus fragiles et complexes à maintenir. La canonicalisation offre une solution plus simple et moins risquée.
Ce qu'il faut comprendre
Pourquoi cette question se pose-t-elle en premier lieu ?
Le problème surgit quand vous avez des pages non indexées qui continuent de recevoir des liens externes. Typiquement : anciennes URLs, pages de campagne, contenus dépubliés mais encore référencés ailleurs.
La tentation est forte de rediriger Googlebot vers une page indexée tout en laissant les utilisateurs accéder au contenu original. D'où l'idée des redirections conditionnelles basées sur le user-agent. Sauf que Google prévient — ce n'est pas la meilleure approche.
Quelle est la différence technique entre ces deux méthodes ?
Une redirection 301 par user-agent renvoie Googlebot vers une URL différente de celle que voit l'utilisateur. Le serveur détecte le bot et applique une règle spécifique. Fonctionnel, mais ça multiplie les points de friction.
Le rel=canonical, lui, indique simplement à Google quelle version faire autorité. Pas de redirection serveur. Pas de logique conditionnelle. La page reste accessible normalement, et Google comprend où consolider les signaux de liens.
Pourquoi Google préfère-t-il la canonicalisation ?
Parce que c'est moins sujet aux erreurs d'implémentation. Les redirections user-agent peuvent bloquer d'autres bots légitimes, casser le monitoring, ou créer des incohérences si le user-agent est mal détecté.
Le rel=canonical est un signal — Google peut choisir de le suivre ou non, mais il ne casse rien. C'est une directive souple, pas un mur technique.
- rel=canonical : signal déclaratif, facile à implémenter, sans risque de blocage
- Redirections user-agent : techniquement acceptables mais complexes, risque d'erreurs de détection
- Google privilégie toujours la simplicité technique pour éviter les configurations bancales
- Cette recommandation s'applique spécifiquement aux pages non indexées recevant des backlinks
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. Sur le papier, les redirections user-agent fonctionnent. Mais en pratique, elles génèrent des faux positifs de cloaking dans certains audits automatisés, et compliquent le debugging quand les crawlers tiers (Ahrefs, Semrush, etc.) voient une chose et Google une autre.
Les canonicals sont plus transparents. Tous les crawlers voient la même page, mais avec une indication claire de consolidation. C'est plus facile à tracer dans les logs, moins ambigu pour les équipes techniques.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre page non indexée ne reçoit aucun lien externe, la question ne se pose même pas. Vous pouvez simplement la bloquer en noindex ou robots.txt sans vous embêter.
Si vous avez un vrai besoin de servir du contenu fondamentalement différent selon le contexte (mobile vs desktop avec des URLs séparées, par exemple), alors oui, les redirections conditionnelles peuvent avoir du sens. Mais ce n'est pas le scénario évoqué ici.
[À vérifier] Google ne précise pas comment il traite les canonicals sur des pages déjà marquées noindex. Théoriquement, le noindex l'emporte — mais si la page reçoit des backlinks, mieux vaut privilégier le canonical sans noindex pour conserver le jus.
Quelle nuance faut-il apporter ?
Le rel=canonical n'est qu'un signal consultatif. Google peut l'ignorer s'il détecte une incohérence (contenu trop différent, canonical en boucle, etc.). Ce n'est pas une garantie absolue de consolidation.
Les redirections 301, elles, sont impératives. Si vous avez besoin d'une consolidation ferme et définitive, la 301 reste l'outil le plus puissant — mais alors pour tous les utilisateurs, pas juste pour Googlebot.
Impact pratique et recommandations
Que faut-il faire concrètement sur les pages non indexées avec backlinks ?
Première étape : identifier ces pages. Croisez vos données Analytics ou logs avec votre profil de liens (Search Console, Ahrefs, Majestic). Toute URL non indexée mais citée ailleurs est candidate.
Ensuite, ajoutez une balise <link rel="canonical" href="URL-cible"> dans le <head> de ces pages. L'URL cible doit être indexée, pertinente thématiquement, et idéalement recevoir déjà du trafic ou des liens.
Quelles erreurs éviter absolument ?
Ne pointez pas vers une page elle-même en noindex. Google ignorera le canonical. Ne créez pas de chaînes de canonicals (A → B → C) — visez toujours la version finale.
Évitez les canonicals vers des pages sémantiquement trop éloignées. Si Google juge l'écart trop grand, il risque d'ignorer le signal et de traiter les pages séparément.
- Identifier les pages non indexées avec backlinks via Search Console ou outils tiers
- Ajouter un rel=canonical pointant vers une page indexée et pertinente
- Vérifier que la page cible n'est pas en noindex ou bloquée en robots.txt
- Éviter les chaînes de canonicals — pointer directement vers la version définitive
- Monitorer dans Search Console que Google respecte bien le canonical (rapport Couverture)
- Ne pas utiliser de redirections user-agent sauf cas très spécifiques et documentés
Comment vérifier que tout est conforme ?
Dans Search Console, allez sur Couverture et filtrez les pages "Exclues" avec la raison "Dupliquée, URL alternative avec balise canonical appropriée". Si vos pages apparaissent ici, c'est bon signe.
Vérifiez également dans les logs serveur que Googlebot ne déclenche aucune redirection 301/302 sur ces URLs. Si c'est le cas, vous avez probablement encore des règles user-agent actives qu'il faut nettoyer.
❓ Questions frequentes
Peut-on utiliser rel=canonical sur une page en noindex ?
Les redirections user-agent sont-elles considérées comme du cloaking ?
Que faire si Google ignore mon canonical ?
Faut-il supprimer les anciennes redirections 301 user-agent déjà en place ?
Le canonical transfère-t-il le PageRank comme une 301 ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 31/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.