Official statement
Other statements from this video 5 ▾
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Pourquoi Google a-t-il développé une version Java de son parser robots.txt ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google considère-t-il votre fichier robots.txt comme une menace potentielle ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
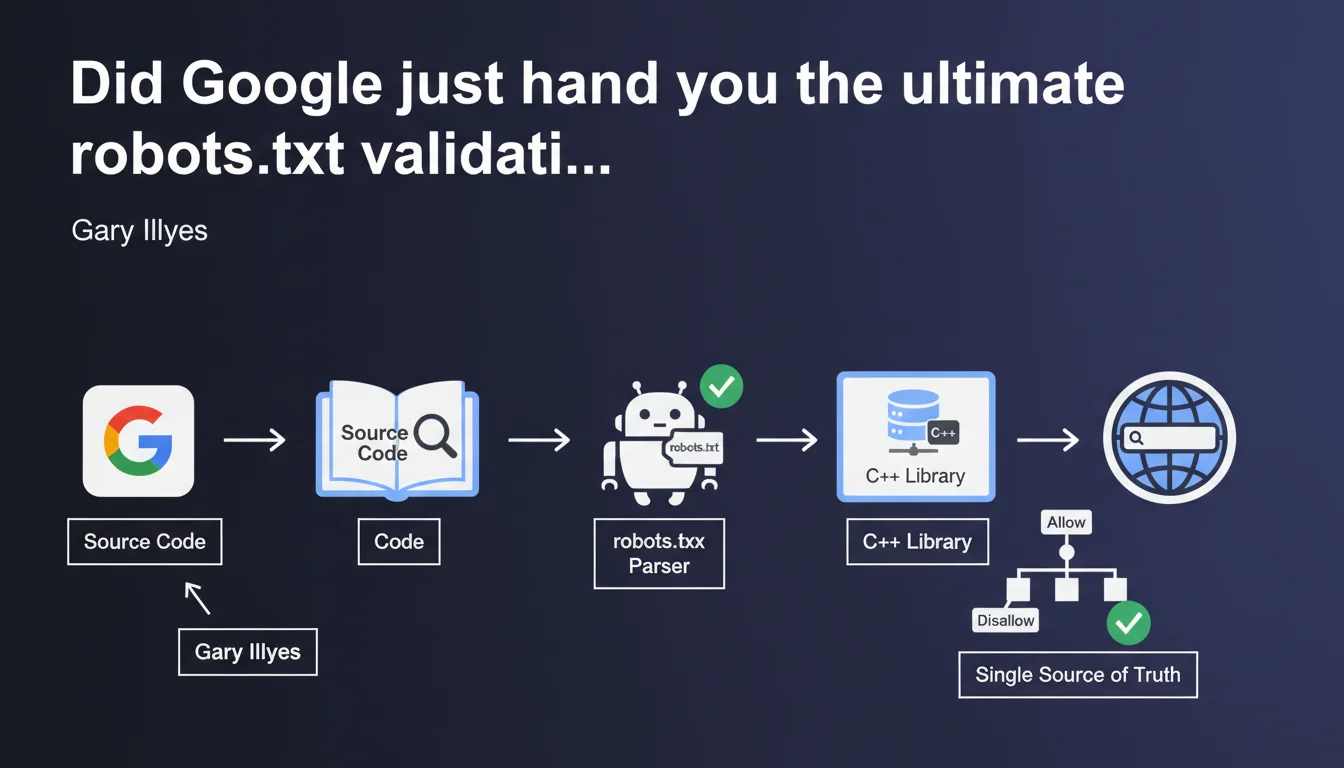
Google released its official C++ robots.txt parser on GitHub—the exact same version Google Search uses internally to interpret your robots.txt files. This is now the single source of truth for understanding how Google actually reads your directives. No more guesswork. You can test locally with the same code Googlebot runs.
What you need to understand
What exactly is a robots.txt parser?
A parser is a syntax analyzer that reads and interprets the directives in a robots.txt file. It determines which URLs a bot can or cannot crawl.
Until now, SEO professionals relied on approximate validators or trusted Google's recommendations without knowing precisely how the search engine handled ambiguous cases. Now the C++ source code is public—you can compile and test exactly as Googlebot does.
Why is Google releasing this code now?
Google wants to standardize how the robots.txt protocol is interpreted across the web. By open sourcing its parser, the company is encouraging other search engines and tools to adopt the same interpretation rules.
It's also a way to eliminate gray areas: if you're unsure about a complex directive, you can literally read or run the code. No more excuses for implementation errors.
What's the practical impact of this release?
This library is the single source of truth for Google Search. In other words: if your robots.txt is being misinterpreted, you can now compare observed behavior against the official code.
It's especially useful for complex sites with nested directive patterns, wildcards, or conflicting rules. You can debug locally before pushing to production.
- The parser is written in C++ and available on GitHub
- It's the exact version used by Googlebot—not an approximation
- Allows local testing of complex directive interpretation
- Reduces implementation ambiguities across different crawlers
- Encourages standardization of the robots.txt protocol
SEO Expert opinion
Is this transparency really groundbreaking?
Not entirely. Google has long documented robots.txt specifications and provided testing tools in Search Console. But releasing the actual source code changes everything: no more vague interpretations or silent bugs.
Concretely? When you encounter unexpected Googlebot behavior, you can now compile the parser, run your robots.txt through it, and verify line-by-line what's happening. That's a massive time-saver for debugging edge cases.
What are the limitations of this release?
The open source parser handles robots.txt syntax—it doesn't model Googlebot's full real-world behavior. For example, it doesn't account for crawl priorities, crawl budget, or JavaScript rendering decisions post-crawl.
In other words: even if your robots.txt passes validation with the parser, that doesn't guarantee Google will crawl all authorized pages. Crawl budget constraints and quality signals still matter. [To verify]: Google hasn't clarified whether the parser handles all the nuances of the historical implementation—certain edge cases may still diverge.
Should you change how you manage robots.txt?
Not fundamentally. Best practices remain the same: simplicity, clarity, regular testing. But this release provides a definitive validation tool you can integrate into your CI/CD pipelines.
If you manage platforms with thousands of pages and dynamically generated robots.txt rules, compiling this parser and running it in pre-prod becomes relevant. For typical sites, Search Console tools are more than sufficient.
Practical impact and recommendations
What should you actually do with this parser?
First step: download and compile the parser from the official GitHub repository. You'll need a working C++ environment (CMake, compatible compiler). Once compiled, you get an executable that reads a robots.txt file and simulates Googlebot's interpretation.
Second step: test your current robots.txt files. Feed them into the parser and compare results with what you see in Search Console. If you spot discrepancies, it's time to fix or investigate further.
What critical mistakes should you avoid?
Don't assume the open source parser will catch every business logic error. It validates syntax and interpretation, but not strategic logic: accidentally blocking an entire site section is still possible if your directives aren't well thought out.
Also avoid relying exclusively on this parser for testing—Search Console remains the reference tool for validating Googlebot's actual behavior in production. The parser is a complement, not a replacement.
How do you integrate this tool into your workflows?
If you have a dev team, integrate the parser into your CI/CD pipeline. Any robots.txt modification can trigger an automated test before deployment. This drastically reduces production error risk.
For smaller projects, occasional manual testing is fine. The key is to stop operating blind when you modify complex directives.
- Clone the GitHub repository and compile the C++ parser
- Test your current robots.txt with the local parser
- Compare results with Search Console's robots.txt testing tool
- Integrate the parser into your pre-prod validation workflows if applicable
- Document detected edge cases for future reference
- Don't replace Search Console testing with this parser—both are complementary
❓ Frequently Asked Questions
Le parser open source remplace-t-il l'outil de test robots.txt de Search Console ?
Dois-je compiler ce parser même si mon robots.txt est simple ?
Ce parser gère-t-il tous les cas historiques et edge cases de Google ?
Peut-on utiliser ce parser pour tester des robots.txt pour Bing ou d'autres moteurs ?
Quel est l'intérêt de publier ce code pour Google ?
🎥 From the same video 5
Other SEO insights extracted from this same Google Search Central video · published on 08/03/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.