Official statement
Other statements from this video 5 ▾
- □ Pourquoi Google a-t-il open sourcé son parser robots.txt officiel ?
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google considère-t-il votre fichier robots.txt comme une menace potentielle ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
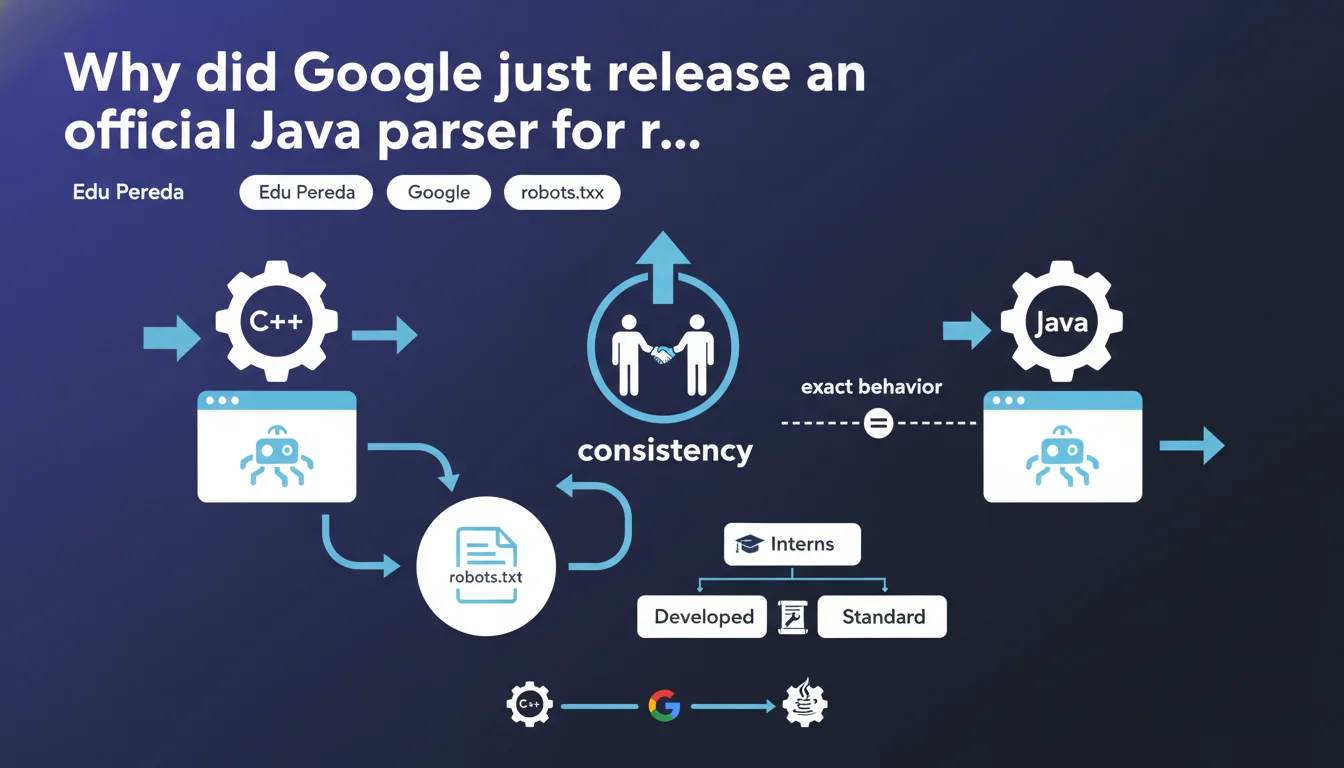
Google has released a Java version of its official robots.txt parser that replicates the exact behavior of the existing C++ version. This implementation follows the same RFC 9309 standard and guarantees complete consistency in interpretation between the two languages. For SEOs: one more tool to test and validate robots.txt files without risking interpretation discrepancies.
What you need to understand
Why is Google now offering a Java version?
Google already had a C++ version of its robots.txt parser, released as open source for several years. This version serves as the reference for interpreting the crawl rules defined by webmasters.
The new Java version was developed to address a simple need: giving developers and SEOs using Java access to a parser that replicates exactly the behavior used by Google. The fact that it was developed by interns shows that Google considers this implementation sufficiently standardized to entrust to junior profiles — which says a lot about the maturity of the standard.
How does this differ from other robots.txt parsers?
There are dozens of libraries available for parsing robots.txt files, but they don't all follow the same interpretation rules. Some handle wildcards poorly, others interpret Crawl-delay or Allow/Disallow directives differently.
Google's official parser — whether in C++ or Java — follows the RFC 9309 standard, which precisely defines how to interpret each directive. Using the Java version guarantees that you test your rules exactly as Googlebot will understand them.
What does this concretely change for SEO?
- Ability to test locally your robots.txt files using the same logic as Googlebot
- Easier integration into automated audit tools developed in Java
- Reduced risk of interpretation errors with complex configurations (wildcards, multiple Allow/Disallow)
- Complete consistency between development environments and Google production
- Precise validation of directives before going live, especially for sites with complex URL structures
SEO Expert opinion
Does this announcement really bring anything new to the table?
Let's be honest: for the vast majority of SEOs, this announcement has no immediate impact. Google Search Console already offers a robots.txt tester that works perfectly. Third-party tools like Screaming Frog or OnCrawl handle standard rules correctly.
The real value lies for developers building SEO audit tools or technical teams at large sites automating their controls. For them, having access to an official Java implementation eliminates any doubt about the compliance of their validations.
Should we be concerned that this was developed by interns?
Quite the opposite — it's actually reassuring. It demonstrates that the RFC 9309 standard is clear and well-documented enough that a faithful implementation doesn't require senior engineers. The interns were certainly supervised, but entrusting them with this project proves its maturity.
Google would never have released this version if it didn't replicate the exact behavior of the C++ parser. Compliance testing must have been exhaustive — their reputation as a standards publisher is on the line.
What are the limits to this promised consistency?
Google claims "complete consistency in interpretation" between both versions. [To verify]: this promise assumes both implementations will be maintained in parallel with equal rigor. If the C++ parser evolves to handle a particular edge case, how long before the Java version is updated?
The other point — and this is crucial — concerns potential bugs. If Googlebot uses the C++ version in production, then that version is the reference in case of divergence. The Java version is a testing tool, not the ground truth of actual crawl behavior.
Practical impact and recommendations
What should you concretely do with this information?
If you're developing SEO audit tools in Java or if your technical team uses Java to automate compliance checks, integrate this library. It guarantees validation that conforms to Googlebot's actual behavior.
For SEOs who don't code: this announcement changes nothing about your daily practices. Continue using the Search Console robots.txt tester, which remains the reference tool for validating your rules before going live.
What errors should you avoid when managing robots.txt?
Even with the official parser, configuration errors remain frequent. The problem rarely comes from rule interpretation, but from their initial formulation. A poorly placed Disallow directive can block entire sections of your site.
Wildcards (*) are particularly tricky: many webmasters think they work like regex, when their behavior is specific to the robots.txt standard. Testing with the official parser won't fix a misunderstanding of the syntax.
How can you validate that your robots.txt is properly configured?
- Systematically test each new directive in Search Console before going live
- Verify that your strategic URLs (product pages, categories, key content) aren't accidentally blocked
- Regularly audit server logs to detect crawl attempts on sections supposedly blocked
- Document each Disallow rule with a comment explaining its purpose — your future self will thank you
- Avoid overly broad Disallow directives that could block more than intended as the site evolves
- If you use wildcards, double-test with multiple URL variations affected by the rule
❓ Frequently Asked Questions
Dois-je obligatoirement utiliser le parser Java si je développe en Java ?
Le parser Java fonctionne-t-il aussi pour Bing et les autres moteurs ?
Cette version Java remplace-t-elle le testeur de la Search Console ?
Où trouver cette version Java du parser robots.txt ?
Les deux parsers (C++ et Java) seront-ils toujours synchronisés ?
🎥 From the same video 5
Other SEO insights extracted from this same Google Search Central video · published on 08/03/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.