Official statement
Other statements from this video 5 ▾
- □ Pourquoi Google a-t-il open sourcé son parser robots.txt officiel ?
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Pourquoi Google a-t-il développé une version Java de son parser robots.txt ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
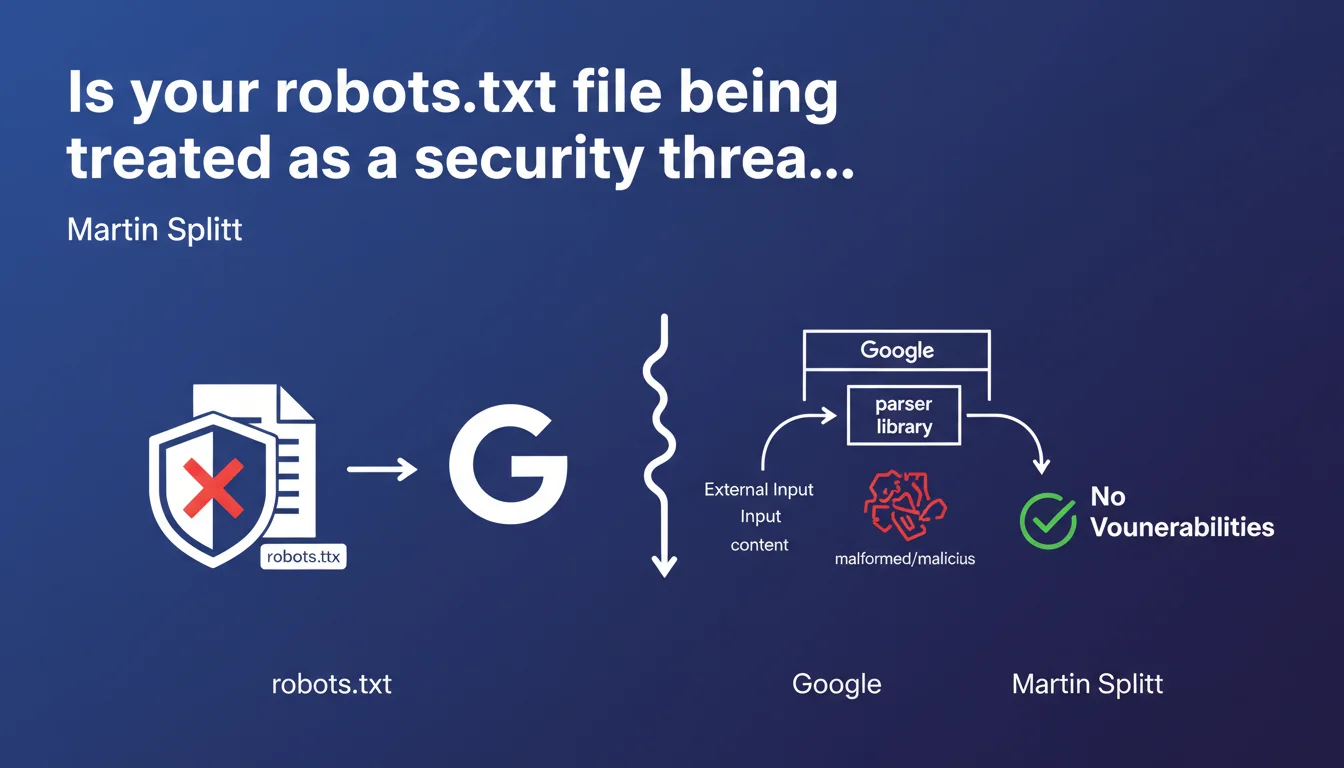
Google treats the content of robots.txt files as external input controlled by users, therefore potentially malicious. The parsing library is designed to handle malformed content without introducing security vulnerabilities. In practice, this means Google protects itself against intentional or accidental manipulations in this file.
What you need to understand
What does this reveal about Google's internal operations?
Google explicitly categorizes robots.txt in the same family as untrusted user inputs. In other words, it applies the same security safeguards it would use for content submitted through a form or external API.
This defensive approach is far from trivial. It shows that Google expects certain webmasters — whether by mistake or intentionally — to attempt to exploit robots.txt parsing. Command injection, malformed special characters, exotic syntaxes: everything is on the table.
Does this change anything for my current robots.txt file?
If your file is clean and compliant with standard specifications, nothing changes. Google will continue to read it without any issues.
However, if you have unusual directives, comments with special characters, or complex undocumented regex patterns, Google may ignore them or interpret them differently than you expect. The parser is error-tolerant, but conservative in its interpretation.
Why is Google communicating about this now?
This statement likely reflects a desire for technical transparency about how Google manages security risks. Martin Splitt is speaking here in a context of developers and information security, not solely SEO.
It also reveals that Google treats robots.txt with the same rigor as other attack vectors. Even a file this simple can be a potential entry point if mishandled by the crawler.
- Google categorizes robots.txt as an untrusted external input
- The parser is designed to resist malformed or malicious content
- Compliant files are not impacted, but exotic syntaxes may be ignored
- This defensive approach protects Google's infrastructure against potential exploits
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. We have long observed that Google tolerates errors in robots.txt without crashing the crawler. Approximate syntax, non-standard directives: the bot continues its work by interpreting as best it can.
What Splitt reveals is the why behind this tolerance. It's not technical generosity, it's a security constraint. Google must ensure that a malformed file — intentionally or not — cannot compromise the crawl system.
What nuances should be added to this statement?
The phrasing "potentially problematic" remains intentionally vague. Google doesn't say which types of content are considered dangerous, nor exactly how the parser reacts to specific patterns.
[To verify]: Are complex directives or regex in User-agent systematically ignored? Do certain Unicode characters trigger a fallback to a more restrictive interpretation? Splitt doesn't provide these details.
In what cases might this rule cause practical problems?
If you test advanced patterns in robots.txt — for example, to block third-party crawlers with complex regex — Google might interpret them differently or ignore these directives without warning you.
Same if you inject technical comments into the file to document strategic choices. The parser could consider certain characters as suspicious and skip the entire line. The problem? You'll never know through Search Console.
Practical impact and recommendations
What should you actually do with your robots.txt?
Keep it simple and standard. Use only officially documented directives: User-agent, Disallow, Allow, Crawl-delay (if applicable), Sitemap. No experimentation.
Avoid special characters in comments. If you document the file, use only standard ASCII characters. No emojis, no accents, no control characters.
How can I verify that my file is compliant and secure?
Use the robots.txt tester in Search Console. It will show you how Google interprets your directives. If a line is ignored, it won't appear in the test results.
Validate the syntax with external tools like Merkle's robots.txt validator or Screaming Frog. These tools detect syntax errors that Google would silently ignore.
- Use only standard directives (User-agent, Disallow, Allow, Sitemap)
- Avoid special characters and non-ASCII throughout the file
- Test the file via Search Console regularly
- Validate syntax with third-party tools (Screaming Frog, Merkle)
- Document strategic choices outside of robots.txt (in an internal wiki)
- Monitor crawl logs to detect unexpected behavior
❓ Frequently Asked Questions
Est-ce que Google peut ignorer certaines directives de mon robots.txt sans me prévenir ?
Les commentaires dans le robots.txt peuvent-ils poser problème ?
Le testeur de robots.txt dans la Search Console est-il fiable pour détecter les problèmes ?
Puis-je utiliser des regex ou des patterns avancés dans le robots.txt ?
Cette approche défensive de Google impacte-t-elle la vitesse de crawl ?
🎥 From the same video 5
Other SEO insights extracted from this same Google Search Central video · published on 08/03/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.