Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Pourquoi Google a-t-il open sourcé son parser robots.txt officiel ?
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Pourquoi Google a-t-il développé une version Java de son parser robots.txt ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
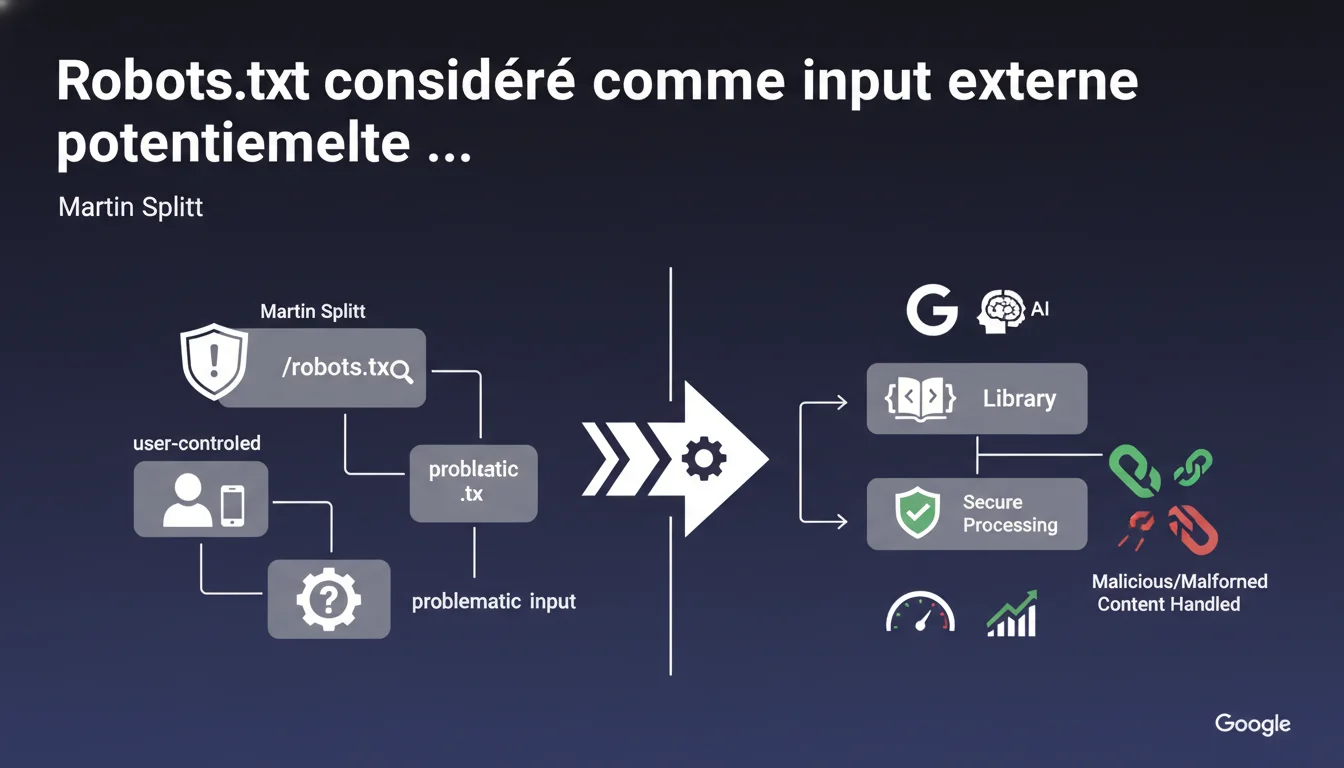
Google traite le contenu du fichier robots.txt comme un input externe contrôlé par les utilisateurs, donc potentiellement malveillant. La bibliothèque de parsing est conçue pour gérer des contenus malformés sans introduire de vulnérabilités de sécurité. Concrètement, cela signifie que Google se protège contre des manipulations intentionnelles ou accidentelles dans ce fichier.
Ce qu'il faut comprendre
Qu'est-ce que cela révèle sur le fonctionnement interne de Google ?
Google catégorise explicitement le robots.txt dans la même famille que les inputs utilisateurs non fiables. C'est-à-dire qu'il applique les mêmes garde-fous de sécurité qu'il utiliserait pour du contenu soumis par un formulaire ou une API externe.
Cette approche défensive n'est pas anodine. Elle montre que Google s'attend à ce que certains webmasters — par erreur ou volontairement — tentent d'exploiter le parsing du robots.txt. Injection de commandes, caractères spéciaux malformés, syntaxes exotiques : tout est sur la table.
Est-ce que cela change quelque chose pour mon fichier robots.txt actuel ?
Si votre fichier est propre et conforme aux spécifications standard, rien ne change. Google va continuer à le lire sans problème.
En revanche, si vous avez des directives bizarres, des commentaires avec des caractères spéciaux, ou des patterns regex complexes non documentés, Google peut les ignorer ou les interpréter différemment de ce que vous attendez. Le parser est tolérant aux erreurs, mais conservateur dans son interprétation.
Pourquoi Google communique-t-il là-dessus maintenant ?
Cette déclaration s'inscrit probablement dans une volonté de transparence technique sur la manière dont Google gère les risques de sécurité. Martin Splitt parle ici dans un contexte de développeurs et de sécurité informatique, pas uniquement SEO.
Cela révèle aussi que Google traite le robots.txt avec la même rigueur que d'autres vecteurs d'attaque. Même un fichier aussi simple peut être un point d'entrée potentiel si mal géré par le crawler.
- Google catégorise le robots.txt comme un input externe non fiable
- Le parser est conçu pour résister aux contenus malformés ou malveillants
- Les fichiers conformes ne sont pas impactés, mais les syntaxes exotiques peuvent être ignorées
- Cette approche défensive protège l'infrastructure de Google contre des exploits potentiels
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. On observe depuis longtemps que Google tolère les erreurs dans le robots.txt sans faire crasher le crawler. Syntaxe approximative, directives non standard : le bot continue son travail en interprétant au mieux.
Ce que Splitt révèle, c'est le pourquoi de cette tolérance. Ce n'est pas de la générosité technique, c'est une contrainte de sécurité. Google doit s'assurer qu'un fichier malformé — volontairement ou non — ne puisse pas compromettre le système de crawl.
Quelles nuances faut-il apporter à cette déclaration ?
La formulation "potentiellement problématique" reste volontairement vague. Google ne dit pas quels types de contenus sont considérés comme dangereux, ni comment le parser réagit exactement face à des patterns spécifiques.
[À vérifier] : est-ce que des directives complexes ou des regex dans les User-agent sont systématiquement ignorées ? Est-ce que certains caractères Unicode provoquent un fallback vers une interprétation plus restrictive ? Splitt ne donne pas ces détails.
Dans quels cas cette règle peut-elle poser problème en pratique ?
Si vous testez des patterns avancés dans le robots.txt — par exemple pour bloquer des crawlers tiers avec des regex complexes — Google pourrait interpréter différemment ou ignorer ces directives sans vous prévenir.
Idem si vous injectez des commentaires techniques dans le fichier pour documenter des choix stratégiques. Le parser pourrait considérer certains caractères comme suspects et skip la ligne entière. Le problème ? Vous ne le saurez jamais via la Search Console.
Impact pratique et recommandations
Que faut-il faire concrètement avec son robots.txt ?
Restez simple et standard. Utilisez uniquement les directives officiellement documentées : User-agent, Disallow, Allow, Crawl-delay (si applicable), Sitemap. Pas de fantaisie.
Évitez les caractères spéciaux dans les commentaires. Si vous documentez le fichier, utilisez uniquement des caractères ASCII standards. Pas d'émojis, pas d'accents, pas de caractères de contrôle.
Comment vérifier que mon fichier est conforme et sûr ?
Utilisez le testeur de robots.txt dans la Search Console. Il vous montrera comment Google interprète vos directives. Si une ligne est ignorée, elle n'apparaîtra pas dans le résultat du test.
Validez la syntaxe avec des outils externes comme le validateur de robots.txt de Merkle ou Screaming Frog. Ces outils détectent les erreurs de syntaxe que Google ignorerait silencieusement.
- Utiliser uniquement les directives standard (User-agent, Disallow, Allow, Sitemap)
- Éviter les caractères spéciaux et non-ASCII dans tout le fichier
- Tester le fichier via la Search Console régulièrement
- Valider la syntaxe avec des outils tiers (Screaming Frog, Merkle)
- Documenter les choix stratégiques en dehors du robots.txt (dans un wiki interne)
- Surveiller les logs de crawl pour détecter des comportements inattendus
❓ Questions frequentes
Est-ce que Google peut ignorer certaines directives de mon robots.txt sans me prévenir ?
Les commentaires dans le robots.txt peuvent-ils poser problème ?
Le testeur de robots.txt dans la Search Console est-il fiable pour détecter les problèmes ?
Puis-je utiliser des regex ou des patterns avancés dans le robots.txt ?
Cette approche défensive de Google impacte-t-elle la vitesse de crawl ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.