Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Pourquoi Google a-t-il développé une version Java de son parser robots.txt ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google considère-t-il votre fichier robots.txt comme une menace potentielle ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
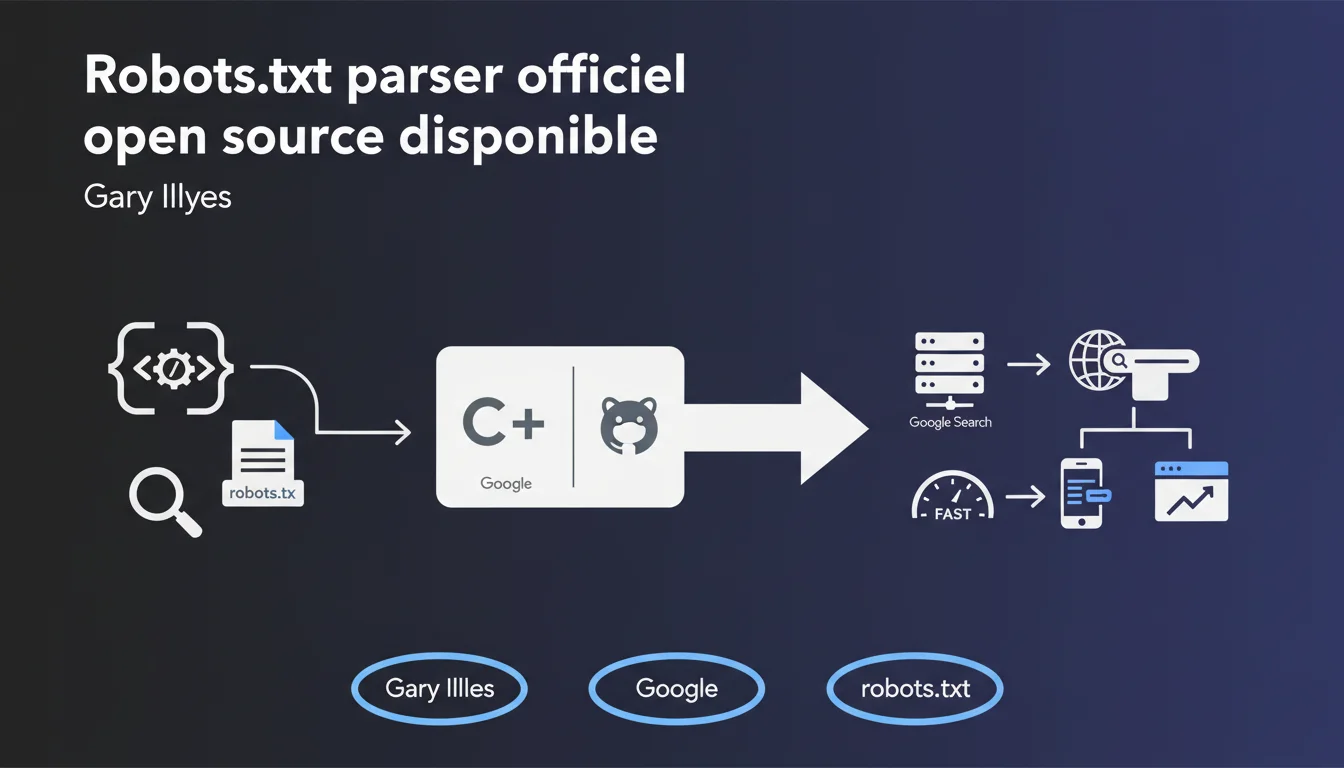
Google a publié sur GitHub son parser robots.txt en C++, la version exacte utilisée en interne par le moteur de recherche. C'est désormais la référence unique pour comprendre comment Google interprète réellement vos fichiers robots.txt. Fini les approximations — vous pouvez tester localement avec le même code que Googlebot.
Ce qu'il faut comprendre
Qu'est-ce qu'un parser robots.txt exactement ?
Un parser est un analyseur syntaxique qui lit et interprète les directives d'un fichier robots.txt. Il détermine quelles URL un robot peut ou ne peut pas crawler.
Jusqu'à présent, les professionnels SEO utilisaient des validateurs approximatifs ou se fiaient aux recommandations Google sans savoir précisément comment le moteur traitait les cas ambigus. Désormais, le code source C++ est public — vous pouvez compiler et tester exactement comme Googlebot le fait.
Pourquoi Google publie-t-il ce code maintenant ?
Google cherche à standardiser l'interprétation du protocole robots.txt à travers le web. En rendant son parser open source, l'entreprise encourage les autres moteurs et outils à adopter les mêmes règles d'interprétation.
C'est aussi une manière de réduire les zones grises : si vous avez un doute sur une directive complexe, vous pouvez littéralement lire ou exécuter le code. Plus d'excuses pour les erreurs d'implémentation.
Quelle est la portée pratique de cette publication ?
Cette bibliothèque constitue la source de vérité unique pour Google Search. Autrement dit : si votre fichier robots.txt est mal interprété, vous pouvez désormais comparer le comportement observé avec le code officiel.
C'est particulièrement utile pour les sites complexes avec des patterns de directives imbriqués, des wildcards ou des règles contradictoires. Vous pouvez maintenant débugger en local avant de pousser en production.
- Le parser est écrit en C++ et disponible sur GitHub
- C'est la version exacte utilisée par Googlebot — pas une approximation
- Permet de tester localement l'interprétation de directives complexes
- Réduit les ambiguïtés d'implémentation entre différents crawlers
- Encourage une standardisation du protocole robots.txt
Avis d'un expert SEO
Cette transparence est-elle vraiment nouvelle ?
Pas totalement. Google documente depuis longtemps les spécifications du robots.txt et fournit des outils de test dans Search Console. Mais publier le code source exact change la donne : exit les interprétations floues ou les bugs silencieux.
Concrètement ? Si vous êtes confronté à un comportement inattendu de Googlebot, vous pouvez désormais compiler le parser, passer votre robots.txt dedans et vérifier ligne par ligne ce qui se passe. C'est un gain de temps considérable pour débugger des cas edge.
Quelles sont les limites de cette publication ?
Le parser open source traite la syntaxe du robots.txt — il ne modélise pas l'ensemble du comportement de Googlebot en conditions réelles. Par exemple, il ne prend pas en compte les priorités de crawl, le budget, ou les décisions de rendu JavaScript post-crawl.
Autrement dit : même si votre robots.txt est parfaitement valide selon le parser, ça ne garantit pas que Google va crawler toutes les pages autorisées. Les contraintes de crawl budget et de qualité restent en jeu. [A vérifier] : Google n'a pas précisé si le parser gère toutes les subtilités de l'implémentation historique — certains edge cases peuvent encore diverger.
Faut-il changer sa manière de gérer robots.txt ?
Non, pas fondamentalement. Les bonnes pratiques restent les mêmes : simplicité, clarté, tests réguliers. Mais cette publication offre un outil de validation définitive que vous pouvez intégrer dans vos pipelines CI/CD.
Si vous gérez des plateformes avec des milliers de pages et des règles robots.txt générées dynamiquement, compiler ce parser et le faire tourner en pre-prod devient pertinent. Pour un site classique, les outils Search Console suffisent largement.
Impact pratique et recommandations
Que faut-il faire concrètement avec ce parser ?
Première étape : télécharger et compiler le parser depuis le dépôt GitHub officiel. Vous aurez besoin d'un environnement C++ fonctionnel (CMake, compilateur compatible). Une fois compilé, vous obtenez un exécutable qui lit un fichier robots.txt et simule l'interprétation de Googlebot.
Deuxième étape : tester vos fichiers robots.txt actuels. Passez-les dans le parser et comparez les résultats avec ce que vous observez dans Search Console. Si vous détectez des divergences, c'est le moment de corriger ou d'investiguer plus loin.
Quelles erreurs éviter absolument ?
Ne présumez pas que le parser open source va détecter toutes les erreurs métier. Il valide la syntaxe et l'interprétation, mais pas la logique stratégique : bloquer accidentellement une section entière de votre site reste possible si vos directives sont mal pensées.
Évitez également de vous reposer exclusivement sur ce parser pour les tests — Search Console reste l'outil de référence pour valider le comportement réel de Googlebot en production. Le parser est un complément, pas un remplacement.
Comment intégrer cet outil dans vos workflows ?
Si vous avez une équipe dev, intégrez le parser dans votre pipeline CI/CD. Chaque modification du robots.txt peut déclencher un test automatique avant déploiement. Cela réduit drastiquement le risque d'erreur de production.
Pour les projets plus petits, un test manuel ponctuel suffit. L'essentiel est de ne plus naviguer à l'aveugle quand vous modifiez des directives complexes.
- Cloner le dépôt GitHub et compiler le parser C++
- Tester votre robots.txt actuel avec le parser local
- Comparer les résultats avec l'outil de test robots.txt de Search Console
- Intégrer le parser dans vos processus de validation pre-prod si pertinent
- Documenter les cas edge détectés pour référence future
- Ne pas remplacer les tests Search Console par ce parser — les deux sont complémentaires
❓ Questions frequentes
Le parser open source remplace-t-il l'outil de test robots.txt de Search Console ?
Dois-je compiler ce parser même si mon robots.txt est simple ?
Ce parser gère-t-il tous les cas historiques et edge cases de Google ?
Peut-on utiliser ce parser pour tester des robots.txt pour Bing ou d'autres moteurs ?
Quel est l'intérêt de publier ce code pour Google ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.