Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Pourquoi Google a-t-il open sourcé son parser robots.txt officiel ?
- □ Pourquoi Google a-t-il développé une version Java de son parser robots.txt ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google considère-t-il votre fichier robots.txt comme une menace potentielle ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
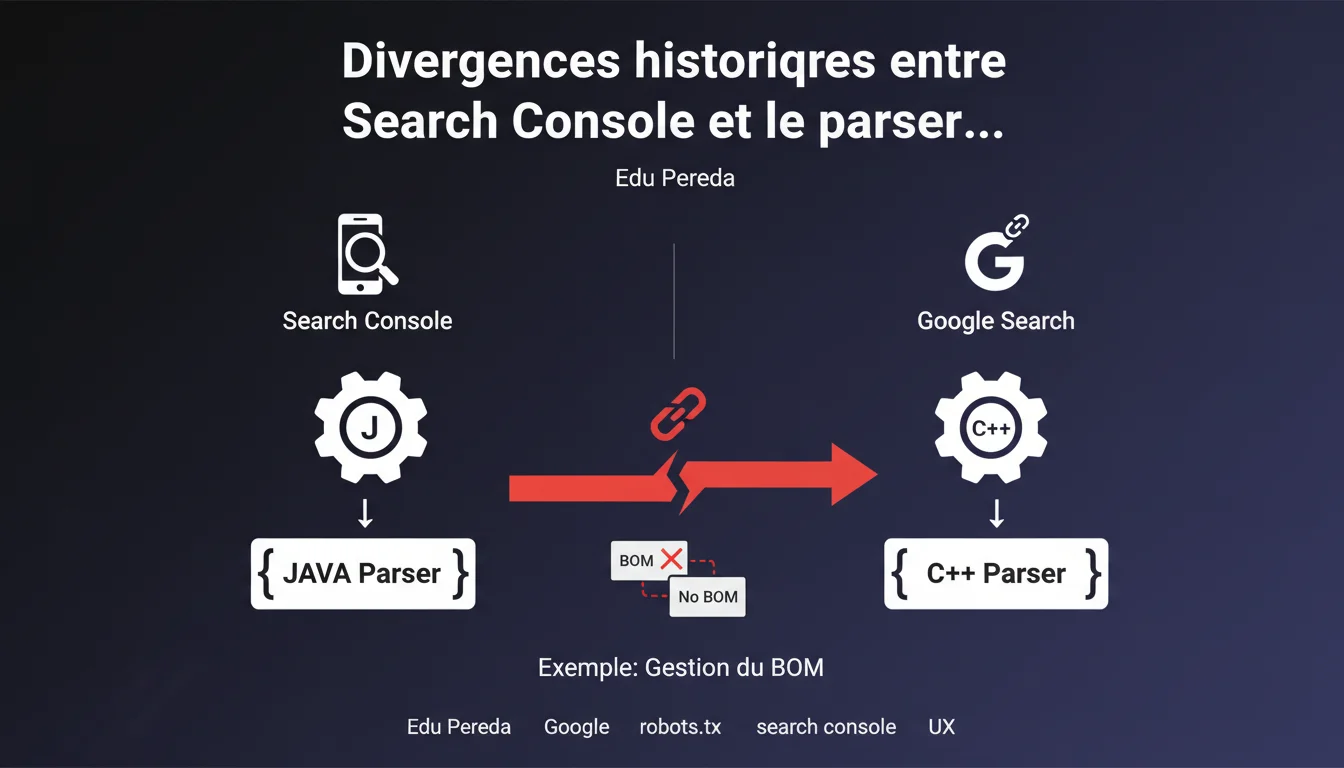
Search Console s'appuyait historiquement sur un parser robots.txt en Java distinct de celui utilisé par Google Search (en C++). Cette divergence technique provoquait des différences d'interprétation — notamment sur la gestion du BOM (Byte Order Mark). Un même fichier robots.txt pouvait donc générer des signaux contradictoires entre l'outil de test et le comportement réel du crawler.
Ce qu'il faut comprendre
Pourquoi deux implémentations différentes du même outil ?
Google Search repose sur un parser robots.txt écrit en C++, optimisé pour la vitesse et le volume. Search Console, en revanche, utilisait une version Java distincte, développée indépendamment. Cette dualité technique n'était pas un choix délibéré pour tromper les SEO — simplement une réalité d'infrastructure où différents services utilisent différents langages.
Le problème ? Les deux parsers ne réagissaient pas toujours de la même façon face aux mêmes instructions, notamment en présence de caractères spéciaux ou de formats de fichier atypiques.
Qu'est-ce que le BOM et pourquoi pose-t-il problème ?
Le Byte Order Mark (BOM) est une séquence de bytes invisibles insérée au début d'un fichier texte pour indiquer l'encodage (UTF-8, UTF-16...). Certains éditeurs de texte l'ajoutent automatiquement.
Le parser Java de Search Console pouvait interpréter le BOM différemment du parser C++ de Google Search. Résultat : un fichier robots.txt validé dans Search Console pouvait être partiellement ou totalement ignoré par le crawler réel — ou inversement.
Quels autres cas d'incohérence ont été observés ?
Au-delà du BOM, des divergences apparaissaient sur la gestion des espaces en fin de ligne, des commentaires malformés, ou des directives non-standard. Le parser Java était parfois plus permissif, masquant des erreurs que le parser C++ refusait net.
- Le BOM pouvait être ignoré par un parser et pas par l'autre
- Les espaces superflus en fin de ligne ne provoquaient pas les mêmes conséquences
- Certaines directives non-standard passaient dans Search Console mais échouaient en production
- Cette incohérence rendait le test robots.txt de Search Console partiellement trompeur
Avis d'un expert SEO
Cette déclaration explique-t-elle enfin des bugs historiques ?
Oui — et c'est une confirmation bienvenue. Pendant des années, des SEO ont signalé des comportements incohérents entre l'outil de test robots.txt et le crawl réel. Google répondait souvent que « le fichier était bien formé », alors que des sections entières étaient ignorées en production.
Cette déclaration officialise ce qu'on soupçonnait : deux parsers différents = deux vérités. Le problème, c'est que Google n'a jamais documenté publiquement ces divergences avant qu'Edu Pereda n'en parle. [A vérifier] : est-ce que cette dualité est désormais résolue, ou persiste-t-elle dans certains contextes ?
Google a-t-il unifié les deux parsers depuis ?
Edu Pereda mentionne que Search Console utilisait historiquement une implémentation Java. Le passé employé suggère une convergence, mais aucune précision n'est donnée sur la date exacte ni sur l'état actuel.
En pratique, si vous testez un robots.txt aujourd'hui dans Search Console, rien ne garantit formellement que le parser utilisé est strictement identique à celui du crawler. Mieux vaut croiser les validations avec des tests en conditions réelles (logs serveur, Google Search Console Inspection Tool).
Faut-il encore se méfier du test robots.txt de Search Console ?
Soyons honnêtes : cet outil reste utile pour détecter les erreurs grossières. Mais il ne doit jamais être la seule source de vérité. Si votre fichier robots.txt contient des directives complexes, des encodages exotiques ou des commentaires non-standard, validez toujours en observant le comportement réel du crawler.
Impact pratique et recommandations
Que faire si votre robots.txt comporte un BOM ?
Supprimez-le. La plupart des éditeurs de texte modernes permettent de sauvegarder en UTF-8 sans BOM. Sous Windows, évitez le Bloc-notes (Notepad) pour éditer des fichiers robots.txt — préférez Notepad++, VSCode ou Sublime Text.
Vérifiez l'encodage en ouvrant le fichier dans un éditeur hexadécimal. Si vous voyez EF BB BF au début, c'est un BOM UTF-8. Supprimez ces bytes.
Comment détecter des incohérences entre Search Console et le crawl réel ?
Comparez systématiquement trois sources : le test robots.txt de Search Console, l'outil Inspecter l'URL (qui montre si une page est bloquée), et vos logs serveur. Si Googlebot n'accède pas à une URL que Search Console déclare autorisée, creusez.
Utilisez également des outils tiers comme Screaming Frog ou OnCrawl pour simuler le crawl avec différents parsers. Certains outils reproduisent mieux le comportement de Googlebot que Search Console lui-même.
Quelles règles de prudence appliquer pour éviter les pièges ?
- Éditez toujours robots.txt en UTF-8 sans BOM, sous un éditeur de code
- Évitez les espaces superflus en fin de ligne
- Ne comptez pas sur Search Console comme unique validation
- Croisez avec l'Inspection d'URL et les logs serveur
- Testez en conditions réelles après chaque modification critique
- Documentez toute divergence observée entre l'outil et le crawl
Les incohérences historiques entre Search Console et le parser réel de Google Search rappellent une règle simple : testez, mesurez, observez. Ne vous fiez jamais à un seul outil. Si votre architecture technique comporte des spécificités (encodages atypiques, directives avancées, multiples sous-domaines), la validation peut se révéler complexe.
Dans ce type de contexte, un accompagnement par une agence SEO spécialisée permet de sécuriser vos fichiers robots.txt et d'éviter des erreurs coûteuses — notamment lors de migrations ou de refonte.
❓ Questions frequentes
Le BOM dans robots.txt bloque-t-il systématiquement Googlebot ?
Google a-t-il unifié les deux parsers robots.txt ?
Peut-on faire confiance à l'outil de test robots.txt de Search Console ?
Comment vérifier si mon robots.txt contient un BOM ?
Quels autres caractères ou directives peuvent poser problème ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.