Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Pourquoi Google a-t-il open sourcé son parser robots.txt officiel ?
- □ Pourquoi votre robots.txt peut-il être interprété différemment par Search Console et Google Search ?
- □ Comment Google teste-t-il vraiment la robustesse de son parser robots.txt ?
- □ Pourquoi Google considère-t-il votre fichier robots.txt comme une menace potentielle ?
- □ Pourquoi Google teste-t-il son parser robots.txt avec autant de rigueur ?
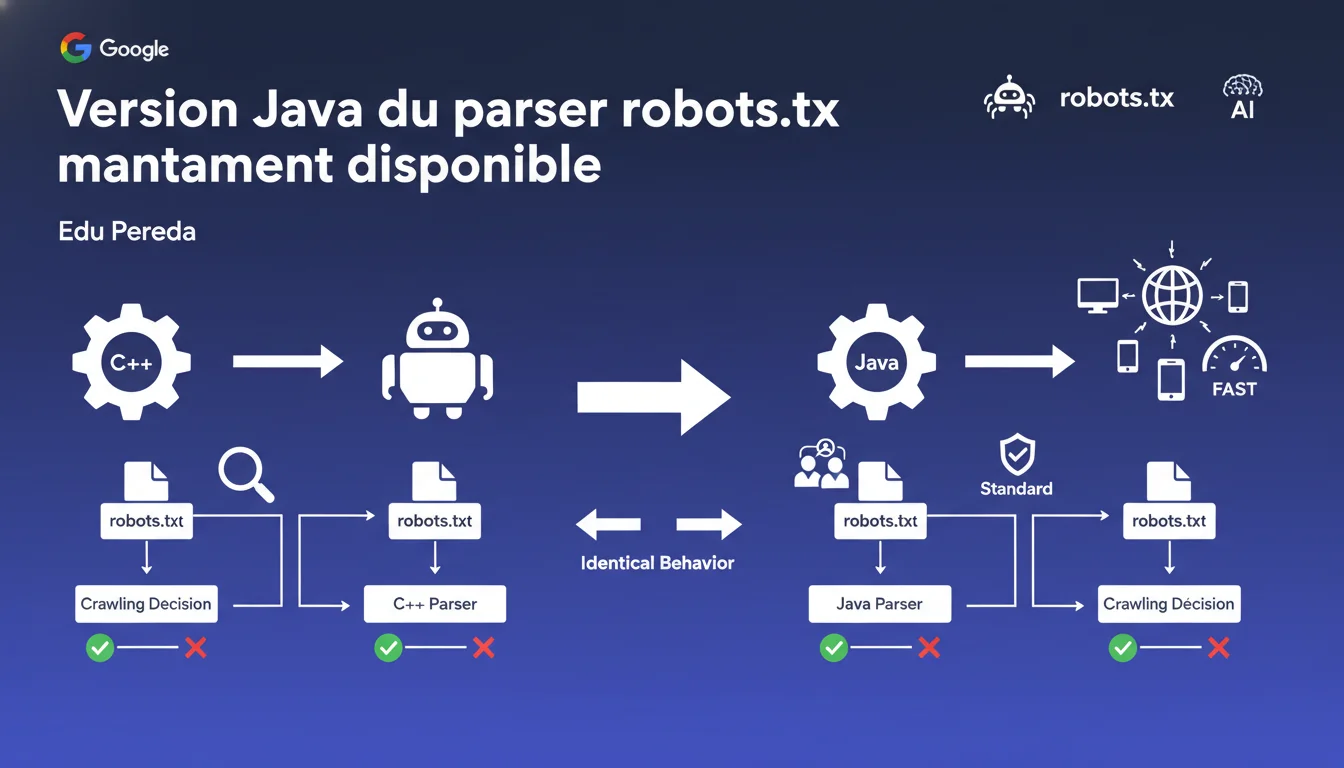
Google publie une version Java de son parser robots.txt officiel qui réplique exactement le comportement de la version C++ existante. Cette implémentation suit le même standard RFC 9309 et garantit une cohérence totale d'interprétation entre les deux langages. Pour les SEO : un outil de plus pour tester et valider les fichiers robots.txt sans risque de divergence d'interprétation.
Ce qu'il faut comprendre
Pourquoi Google propose-t-il maintenant une version Java ?
Google disposait déjà d'une version C++ de son parser robots.txt, publiée en open source depuis plusieurs années. Cette version sert de référence pour interpréter les règles d'exploration définies par les webmasters.
La nouvelle version Java a été développée pour répondre à un besoin simple : permettre aux développeurs et SEO utilisant Java d'avoir accès à un parser qui réplique exactement le comportement de celui utilisé par Google. Le fait qu'elle ait été développée par des stagiaires montre que Google considère cette implémentation comme suffisamment standardisée pour être confiée à des profils juniors — ce qui en dit long sur la maturité du standard.
Quelle est la différence avec les autres parsers robots.txt ?
Il existe des dizaines de bibliothèques pour parser les fichiers robots.txt, mais elles ne respectent pas toutes les mêmes règles d'interprétation. Certaines gèrent mal les wildcards, d'autres interprètent différemment les directives Crawl-delay ou Allow/Disallow.
Le parser officiel de Google — qu'il soit en C++ ou Java — suit le standard RFC 9309, qui définit précisément comment interpréter chaque directive. Utiliser la version Java garantit que vous testez vos règles exactement comme Googlebot les comprendra.
Qu'est-ce que ça change concrètement pour le SEO ?
- Possibilité de tester en local vos fichiers robots.txt avec la même logique que Googlebot
- Intégration facilitée dans des outils d'audit automatisés développés en Java
- Réduction du risque d'erreurs d'interprétation lors de configurations complexes (wildcards, multiples Allow/Disallow)
- Cohérence totale entre les environnements de développement et la production Google
- Validation précise des directives avant mise en ligne, notamment pour les sites avec des structures d'URL complexes
Avis d'un expert SEO
Cette annonce apporte-t-elle vraiment quelque chose de nouveau ?
Soyons honnêtes : pour la majorité des SEO, cette annonce n'a aucun impact immédiat. La Search Console propose déjà un testeur robots.txt qui fonctionne parfaitement. Les outils tiers comme Screaming Frog ou OnCrawl gèrent correctement les règles standards.
Le véritable intérêt concerne les développeurs qui créent des outils d'audit SEO ou les équipes techniques de grands sites qui automatisent leurs contrôles. Pour eux, avoir accès à une implémentation Java officielle élimine tout doute sur la conformité de leurs validations.
Le fait que ce soit développé par des stagiaires doit-il inquiéter ?
Au contraire — c'est plutôt rassurant. Cela démontre que le standard RFC 9309 est suffisamment clair et documenté pour qu'une implémentation fidèle ne nécessite pas l'intervention d'ingénieurs seniors. Les stagiaires ont probablement été encadrés, mais le fait qu'on leur confie ce projet prouve sa maturité.
Google n'aurait jamais publié cette version si elle ne répliquait pas exactement le comportement du parser C++. Les tests de conformité ont forcément été exhaustifs — c'est leur réputation d'éditeur de standard qui est en jeu.
Quelles limites à cette cohérence promise ?
Google affirme une "cohérence totale d'interprétation" entre les deux versions. [À vérifier] : cette promesse suppose que les deux implémentations soient maintenues en parallèle avec la même rigueur. Si le parser C++ évolue pour gérer un cas particulier, combien de temps avant que la version Java soit mise à jour ?
L'autre point — et c'est crucial — concerne les bugs éventuels. Si Googlebot utilise la version C++ en production, alors c'est cette version qui fait référence en cas de divergence. La version Java est un outil de test, pas la vérité terrain du crawl réel.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Si vous développez des outils d'audit SEO en Java ou si votre équipe technique utilise Java pour automatiser les contrôles de conformité, intégrez cette bibliothèque. Elle vous garantit une validation conforme au comportement réel de Googlebot.
Pour les SEO qui ne codent pas : cette annonce ne change rien à vos pratiques quotidiennes. Continuez à utiliser le testeur robots.txt de la Search Console, qui reste l'outil de référence pour valider vos règles avant mise en production.
Quelles erreurs éviter dans la gestion du robots.txt ?
Même avec le parser officiel, les erreurs de configuration restent fréquentes. Le problème vient rarement de l'interprétation des règles, mais de leur formulation initiale. Une directive Disallow mal placée peut bloquer des sections entières du site.
Les wildcards (*) sont particulièrement traîtres : beaucoup de webmasters pensent qu'elles fonctionnent comme des regex, alors que leur comportement est spécifique au standard robots.txt. Tester avec le parser officiel ne corrige pas une mauvaise compréhension de la syntaxe.
Comment valider que votre robots.txt est correctement configuré ?
- Testez systématiquement chaque nouvelle directive dans la Search Console avant mise en production
- Vérifiez que vos URLs stratégiques (pages produits, catégories, contenus clés) ne sont pas bloquées par erreur
- Auditez régulièrement les logs serveur pour détecter des tentatives de crawl sur des sections censément bloquées
- Documentez chaque règle Disallow avec un commentaire expliquant son objectif — vous remercierez votre futur vous
- Évitez les directives Disallow trop larges qui pourraient bloquer plus que prévu lors d'évolutions du site
- Si vous utilisez des wildcards, doublez les tests avec plusieurs variations d'URL concernées
❓ Questions frequentes
Dois-je obligatoirement utiliser le parser Java si je développe en Java ?
Le parser Java fonctionne-t-il aussi pour Bing et les autres moteurs ?
Cette version Java remplace-t-elle le testeur de la Search Console ?
Où trouver cette version Java du parser robots.txt ?
Les deux parsers (C++ et Java) seront-ils toujours synchronisés ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.