Official statement
Other statements from this video 6 ▾
- □ Pourquoi la standardisation du robots.txt par l'IETF change-t-elle la donne pour les crawlers ?
- □ Pourquoi Google limite-t-il la taille de robots.txt à 500 Ko ?
- □ Les flux RSS et Atom sont-ils vraiment utilisés par Google pour découvrir vos contenus ?
- □ Les sitemaps XML sont-ils vraiment indispensables sans standardisation officielle ?
- □ Pourquoi robots.txt reste-t-il indispensable même pour les sites modernes ?
- □ Le robots.txt et les sitemaps XML sont-ils désormais officiellement liés ?
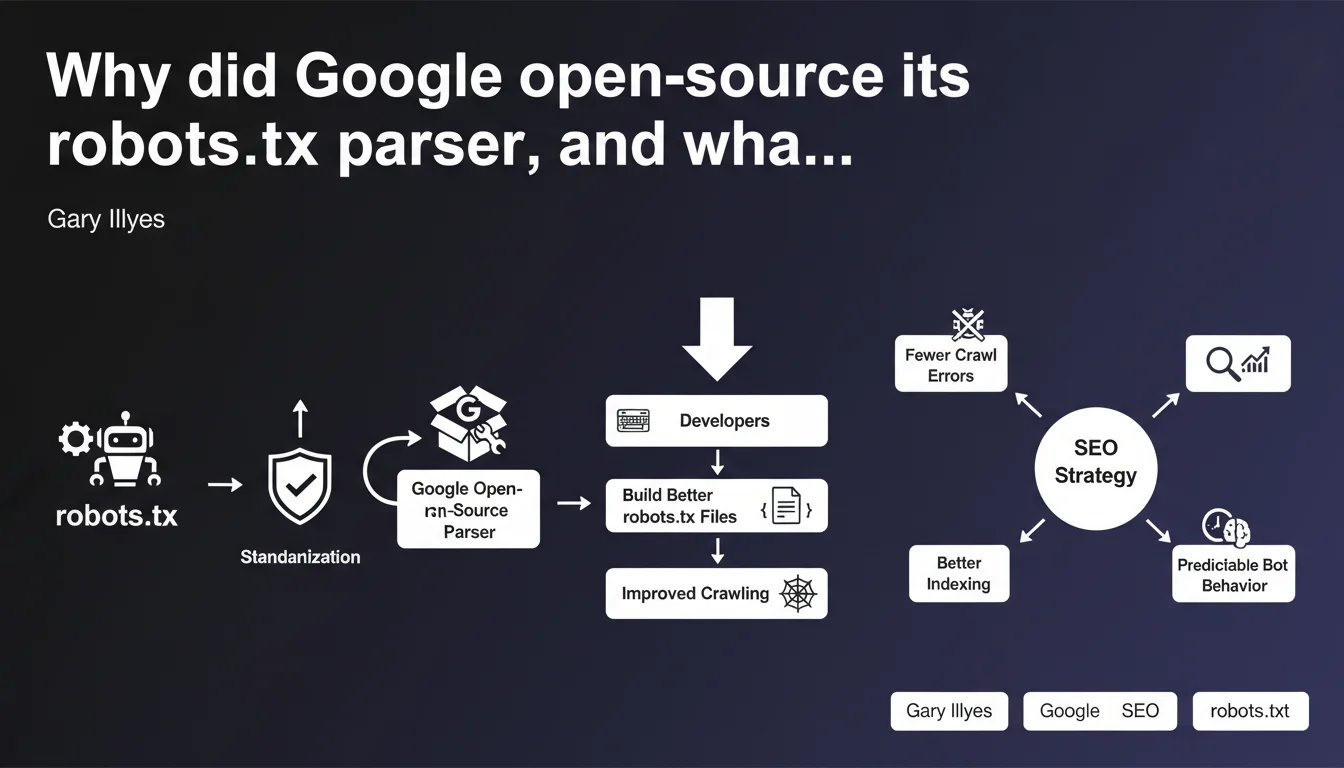
Google has released its official robots.txt parser as open source—the very same tool that analyzes your files on Googlebot. The goal: allow developers to test their directives using exactly the same logic Google uses, avoiding interpretation errors. In concrete terms, you can now validate your robots.txt files with the same engine that crawls your site.
What you need to understand
What exactly is a robots.txt parser, and why does it matter strategically?
A parser is the code that reads and interprets the instructions in a robots.txt file. Each search engine has its own, and until now, Google's was a black box. You wrote your directives without knowing precisely how Google would interpret them.
Open-sourcing the parser changes everything. You now have access to the exact source code that Google uses to analyze your crawl instructions. No more guesswork—you can test your rules with the same logic as Googlebot.
How does this tie in with the standardization of the robots.txt protocol?
Google first pushed to make robots.txt an official standard recognized by the IETF (the body that defines Internet protocols). That was the first step: transforming a 25-year-old de facto usage into a documented technical standard.
Open-sourcing the parser is the logical next step. A standard without a reference implementation remains vague. Here, Google provides the reference code: if you want to know how a directive will be interpreted, you compile the parser and test it.
What are the concrete advantages for developers and SEO professionals?
- Precise validation: you can test your robots.txt files with the same engine Google uses, before going live
- Easier debugging: if a directive doesn't work as expected, you can analyze the code to understand why
- Interoperability: other search engines can build on this foundation to harmonize their own parsers
- Transparency: no more gray areas about handling special characters, wildcards, or rule priorities
- Learning: perfect for understanding the subtleties of the protocol by reading the implementation directly
SEO Expert opinion
Is this code opening really useful for most SEO professionals?
Let's be honest: most robots.txt files are simple. User-agent, a few Disallow rules, a Sitemap. For those cases, open-sourcing the parser changes nothing in your daily work. You won't compile C++ to validate three lines of directives.
However, once you're managing a complex site—multi-faceted architecture, dynamic URL parameters, sophisticated conditional rules—having access to the official parser becomes valuable. You can test edge cases, verify rule priority order when rules conflict, and anticipate behavior on non-standard URL patterns.
Does the open-source parser truly reflect actual Googlebot behavior in production?
Google claims it's the same code used in production. But let's stay critical: the parser only analyzes the file. It doesn't handle crawl budget, prioritization decisions, or network timeouts.
In other words, even if your robots.txt passes all tests with the parser, that doesn't guarantee Google will actually crawl the allowed URLs, or respect your Crawl-delay (which remains non-standard). [To verify]: Google doesn't document how this parser integrates into the crawler's complete stack.
What are the risks of relying solely on this tool?
First pitfall: believing robots.txt is the universal solution for controlling indexation. It's only a tool for controlling crawl, not indexation. Blocking a URL in robots.txt won't prevent Google from indexing it if it receives backlinks.
Second trap: relying on the parser without testing in real conditions. The code might be correct, but if your server returns a 500 when Googlebot tries to fetch the file, or if you have a CDN caching aggressively, the result will be different.
Practical impact and recommendations
How do you practically use Google's open-source parser?
The parser is available on GitHub (search for "google/robotstxt"). It's written in C++, so you'll need to compile it or use one of the wrapper libraries available in Python, Node.js, or Go. If you're not a developer, online tools are beginning to integrate this parser.
Typical usage: you write a complex robots.txt file, pass it through the parser with different test URLs, and verify the results match your expectations. This is a much better alternative to old approximative testers that didn't respect Google's exact logic.
What frequent errors can you now avoid thanks to this tool?
- Misplaced wildcards: test if your "*" is correctly interpreted in complex paths
- Rule order: verify which directive takes precedence when multiple rules apply to the same URL
- Special characters: validate behavior with URLs containing %, #, or encoded spaces
- Case sensitivity: confirm that robots.txt is case-insensitive for User-agent but case-sensitive for paths
- Maximum length: test whether your file doesn't exceed the limits Google will actually respect
Should you review your existing robots.txt files in light of this tool?
If your site is working well, your strategic pages are being crawled and indexed, and you don't have crawl budget issues, there's no need to overhaul everything. The parser won't magically improve your robots.txt.
However, if you notice anomalies—important pages not being crawled, entire sections ignored, server logs showing odd patterns—then yes, running your file through Google's official parser might reveal a malformed directive that's blocking more than intended.
❓ Frequently Asked Questions
Le parseur open source de Google fonctionne-t-il exactement comme le Googlebot en production ?
Dois-je savoir programmer pour utiliser ce parseur ?
Tester mon robots.txt avec ce parseur garantit-il que Google crawlera mes pages ?
Puis-je utiliser ce parseur pour d'autres moteurs que Google ?
Quels sont les cas d'usage prioritaires pour cet outil ?
🎥 From the same video 6
Other SEO insights extracted from this same Google Search Central video · published on 17/04/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.