Official statement
Other statements from this video 6 ▾
- □ Pourquoi Google limite-t-il la taille de robots.txt à 500 Ko ?
- □ Les flux RSS et Atom sont-ils vraiment utilisés par Google pour découvrir vos contenus ?
- □ Les sitemaps XML sont-ils vraiment indispensables sans standardisation officielle ?
- □ Pourquoi robots.txt reste-t-il indispensable même pour les sites modernes ?
- □ Pourquoi Google a-t-il ouvert le code de son parseur robots.txt ?
- □ Le robots.txt et les sitemaps XML sont-ils désormais officiellement liés ?
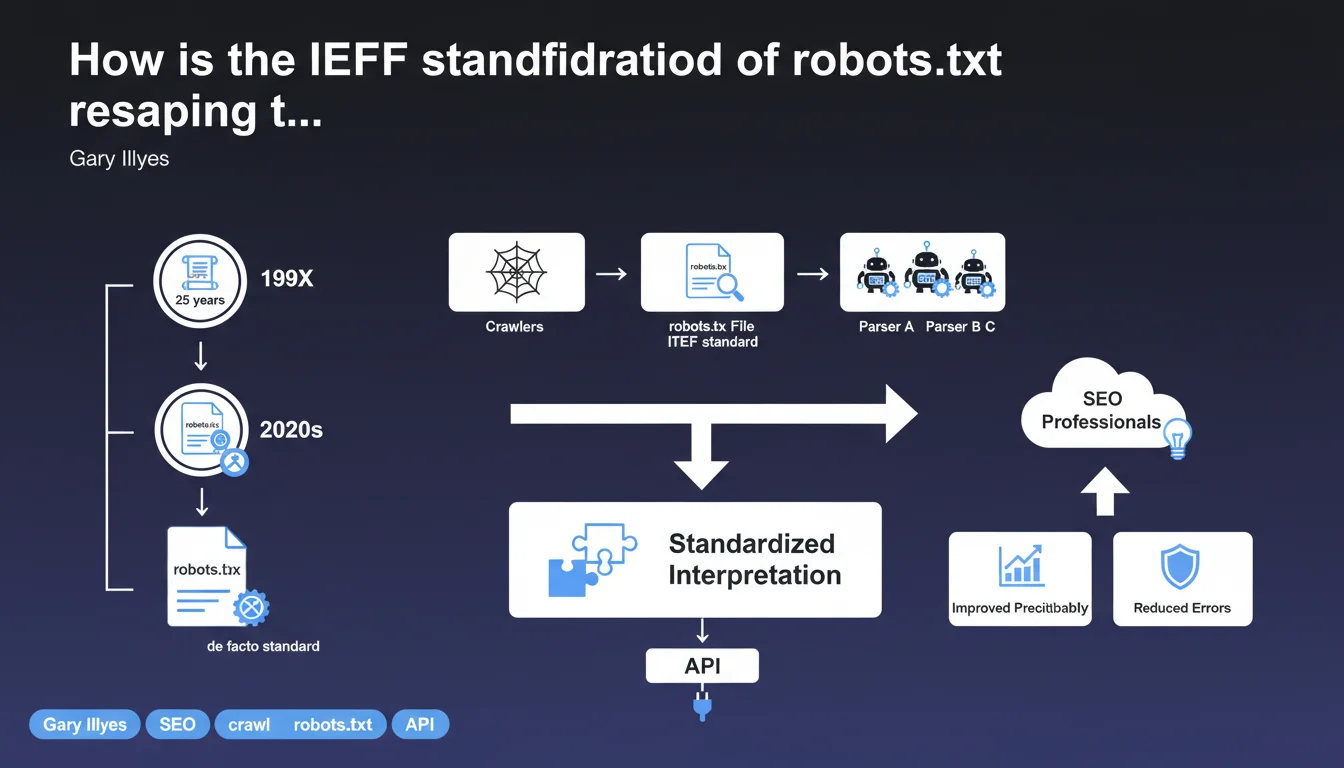
Robots.txt, which remained a simple de facto standard for decades, has just been officially standardized by the IETF after 25 years of usage. This formalization standardizes how different parsers interpret robots.txt files, reducing the ambiguities that could exist between search engines. For SEO professionals, it's the assurance of increased consistency in respecting crawl directives.
What you need to understand
What does IETF standardization actually change in practice?
For a quarter of a century, the robots.txt file operated on the basis of tacit consensus between search engines. Each bot interpreted it in its own way, with sometimes significant variations in how directives were parsed.
The IETF standardization (Internet Engineering Task Force) now imposes a formal framework. Parsers must follow a common specification, which reduces interpretation divergences. Concretely? A directive written once should now be understood identically by Google, Bing, Yandex, or any other crawler that respects the standard.
Why did this standardization take so long to happen?
Robots.txt was born in 1994, in a context where the web was still in its infancy. The protocol naturally established itself without immediate need for official formalization — it worked "well enough" for everyone.
But with the multiplication of bots, the emergence of exotic parsers, and the accumulation of edge cases, Google pushed for official standardization. This prevents ambiguities — and most importantly, it facilitates the future evolution of the protocol within a controlled framework.
What were the most common ambiguities before this standardization?
The differences mainly concerned the handling of wildcards, the treatment of blank lines, or the priority order between contradictory directives. Some crawlers tolerated approximate syntax, others rejected it outright.
Another point of friction: the handling of Crawl-delay. Google has never supported it, unlike Bing or Yandex. With standardization, these divergences should either disappear or be explicitly documented.
- The IETF standard imposes formal grammar for robots.txt
- Parsers must now follow a common and public specification
- Syntactic ambiguities (wildcards, priorities) are resolved by the standard
- This evolution facilitates the maintenance and future evolution of the protocol
- For SEOs, it's a guarantee of cross-crawler consistency
SEO Expert opinion
Does this standardization really change anything on the ground?
Let's be honest: for the majority of well-configured sites, the immediate impact will be virtually none. Robots.txt files following classic conventions (User-agent, Disallow, Allow, Sitemap) already worked correctly with all major crawlers.
Where it becomes interesting is with edge cases — complex syntax, edge-case directives, or exotic bots. The IETF standard now forces these parsers to respect strict grammar. Fewer surprises, fewer unpredictable behaviors.
Do all crawlers already respect this standard?
Google claims to have adopted it — logically, since they pushed for its creation. Bing and other major players will probably follow quickly, if only to avoid being out of compliance. [To be verified]: the actual timeline for secondary bots' compliance remains unclear.
The real problem? The thousands of scrapers and in-house bots that don't care about the IETF and will continue to ignore robots.txt, standard or not. For these crawlers, nothing changes — and they're often the ones that cause the most problems in technical SEO.
Do you need to revise your existing robots.txt files?
In 99% of cases, no. If your robots.txt is clean, syntactically correct, and tested via the Search Console, it will continue to work exactly the same way. Standardization doesn't break backward compatibility.
However, if you're using non-standard directives (Crawl-delay on Google's side, exotic wildcards, makeshift syntax), now is the time to do an audit. The standard clarifies what is supported and what isn't — you might as well comply with it.
Practical impact and recommendations
What should you check in your current robots.txt?
First step: test your file via the Search Console (robots.txt tab in Exploration). Google will now display any potential divergences with the IETF standard. If the parser detects ambiguous syntax, it will flag it.
Next, verify the consistency of your directives: avoid contradictory Allow/Disallow rules on the same paths, and make sure wildcards (*) are used correctly. The standard now specifies their exact behavior — no approximations.
What common mistakes should you avoid?
First mistake: believing that robots.txt blocks indexation. It blocks crawling, not indexation. An uncrawled URL can still appear in the index (via external backlinks). To block indexation, use the noindex meta tag.
Second mistake: forgetting to declare the XML sitemap. The Sitemap: directive in robots.txt remains a strong signal for crawlers — and it's explicitly supported by the IETF standard.
How can you ensure that all crawlers respect these directives?
It's impossible to guarantee 100%. Major crawlers (Google, Bing, Yandex) respect the standard, but third-party bots and scrapers do what they want. Monitor your server logs to detect abnormal behaviors.
For aggressive bots that ignore robots.txt, resort to server-side blocking (user-agent filtering, rate limiting, or WAF). Robots.txt has never been a technical barrier — just a convention of politeness.
- Test your robots.txt via the Search Console and fix any potential ambiguities
- Verify that wildcards (*) are used in accordance with the IETF standard
- Remove non-standard directives (Crawl-delay on Google's side, for example)
- Explicitly declare the XML sitemap via the Sitemap: directive
- Don't confuse blocking crawling (robots.txt) with blocking indexation (noindex)
- Monitor server logs to detect bots that ignore robots.txt
- Implement server-side restrictions for aggressive crawlers
The IETF standardization of robots.txt mainly brings consistency and predictability. For SEO professionals, it's an opportunity to audit your file and ensure it respects the formalized best practices.
If your current configuration is complex — multiple user-agents, nested rules, cross-domain management — technical SEO support can prove valuable to avoid parsing errors that would impact crawling. A specialized agency will help you anticipate edge cases and optimize your directives based on your infrastructure's specific requirements.
❓ Frequently Asked Questions
Le robots.txt empêche-t-il vraiment l'indexation d'une page ?
Dois-je modifier mon robots.txt suite à cette standardisation ?
Tous les crawlers respectent-ils désormais cette norme IETF ?
Quelle est la différence entre robots.txt et la balise noindex ?
La directive Crawl-delay est-elle supportée par le standard IETF ?
🎥 From the same video 6
Other SEO insights extracted from this same Google Search Central video · published on 17/04/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.