Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Pourquoi Google limite-t-il la taille de robots.txt à 500 Ko ?
- □ Les flux RSS et Atom sont-ils vraiment utilisés par Google pour découvrir vos contenus ?
- □ Les sitemaps XML sont-ils vraiment indispensables sans standardisation officielle ?
- □ Pourquoi robots.txt reste-t-il indispensable même pour les sites modernes ?
- □ Pourquoi Google a-t-il ouvert le code de son parseur robots.txt ?
- □ Le robots.txt et les sitemaps XML sont-ils désormais officiellement liés ?
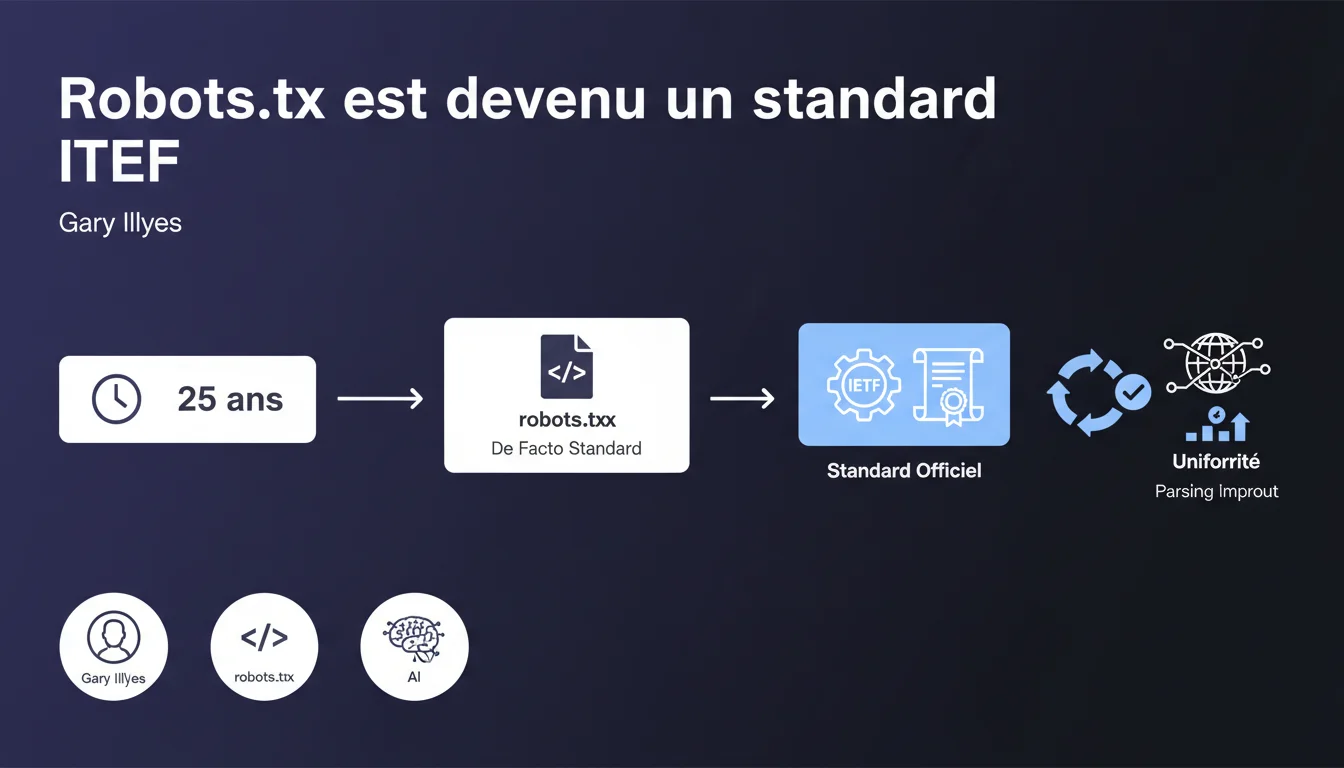
Le robots.txt, longtemps resté un simple standard de facto, vient d'être officiellement standardisé par l'IETF après 25 ans d'usage. Cette formalisation uniformise l'interprétation des fichiers robots.txt par les différents parseurs, réduisant les ambiguïtés qui pouvaient exister entre moteurs de recherche. Pour les SEO, c'est l'assurance d'une cohérence accrue dans le respect des directives d'exploration.
Ce qu'il faut comprendre
Qu'est-ce que la standardisation IETF change concrètement ?
Pendant un quart de siècle, le fichier robots.txt fonctionnait sur la base d'un consensus tacite entre moteurs de recherche. Chaque bot l'interprétait à sa manière, avec des variations parfois significatives dans le parsing des directives.
La standardisation IETF (Internet Engineering Task Force) impose désormais un cadre formel. Les parseurs doivent suivre une spécification commune, ce qui réduit les divergences d'interprétation. Concrètement ? Une directive écrite une fois devrait être comprise de manière identique par Google, Bing, Yandex ou tout autre crawler respectant le standard.
Pourquoi cette uniformisation arrive-t-elle seulement maintenant ?
Le robots.txt est né en 1994, dans un contexte où le web était encore balbutiant. Le protocole s'est imposé naturellement, sans besoin immédiat de formalisation officielle — il fonctionnait « assez bien » pour tout le monde.
Mais avec la multiplication des bots, l'émergence de parseurs exotiques et les cas limites qui s'accumulent, Google a poussé pour une standardisation officielle. Cela évite les ambiguïtés — et surtout, cela facilite l'évolution future du protocole dans un cadre contrôlé.
Quelles étaient les ambiguïtés les plus courantes avant cette standardisation ?
Les différences portaient principalement sur la gestion des wildcards, le traitement des lignes vides, ou l'ordre de priorité entre directives contradictoires. Certains crawlers toléraient des syntaxes approximatives, d'autres les rejetaient sèchement.
Un autre point de friction : la gestion du Crawl-delay. Google ne l'a jamais supporté, contrairement à Bing ou Yandex. Avec la standardisation, ces divergences devraient soit disparaître, soit être explicitement documentées.
- Le standard IETF impose une grammaire formelle pour le robots.txt
- Les parseurs doivent désormais suivre une spécification commune et publique
- Les ambiguïtés syntaxiques (wildcards, priorités) sont résolues par la norme
- Cette évolution facilite la maintenance et l'évolution future du protocole
- Pour les SEO, c'est une garantie de cohérence cross-crawler
Avis d'un expert SEO
Cette standardisation change-t-elle vraiment quelque chose sur le terrain ?
Soyons honnêtes : pour la majorité des sites bien configurés, l'impact immédiat sera quasi nul. Les robots.txt respectant les conventions classiques (User-agent, Disallow, Allow, Sitemap) fonctionnaient déjà correctement avec tous les crawlers majeurs.
Là où ça devient intéressant, c'est pour les cas limites — syntaxes complexes, directives edge-case, ou bots exotiques. La norme IETF force désormais ces parseurs à respecter une grammaire stricte. Moins de surprises, moins de comportements imprévisibles.
Les crawlers respectent-ils déjà tous cette norme ?
Google affirme l'avoir adoptée — logique, puisqu'ils ont poussé pour sa création. Bing et les autres acteurs majeurs suivront probablement rapidement, ne serait-ce que pour éviter d'être hors norme. [A vérifier] : le délai réel de mise en conformité des bots secondaires reste flou.
Le vrai problème ? Les milliers de scrapers et bots maison qui ne se soucient pas de l'IETF et continueront d'ignorer robots.txt, norme ou pas. Pour ces crawlers, rien ne change — et c'est souvent eux qui posent le plus de problèmes en SEO technique.
Faut-il revoir ses fichiers robots.txt existants ?
Dans 99% des cas, non. Si votre robots.txt est propre, syntaxiquement correct et testé via la Search Console, il continuera de fonctionner exactement de la même manière. La standardisation ne casse pas la rétrocompatibilité.
En revanche, si vous utilisez des directives non-standard (Crawl-delay côté Google, wildcards exotiques, syntaxes bricolées), c'est le moment de faire un audit. La norme clarifie ce qui est supporté et ce qui ne l'est pas — autant s'y conformer.
Impact pratique et recommandations
Que faut-il vérifier dans son robots.txt actuel ?
Première étape : tester son fichier via la Search Console (onglet robots.txt dans Exploration). Google affichera désormais les éventuelles divergences avec le standard IETF. Si le parseur détecte une syntaxe ambiguë, il le signalera.
Ensuite, vérifiez la cohérence des directives : évitez les Allow/Disallow contradictoires sur les mêmes chemins, et assurez-vous que les wildcards (*) sont utilisés correctement. La norme précise désormais leur comportement exact — pas d'approximation.
Quelles erreurs courantes éviter ?
Première erreur : croire que le robots.txt bloque l'indexation. Il bloque le crawl, pas l'indexation. Une URL non crawlée peut quand même apparaître dans l'index (via backlinks externes). Pour bloquer l'indexation, utilisez la balise noindex.
Deuxième erreur : oublier de déclarer le sitemap XML. La directive Sitemap: dans le robots.txt reste un signal fort pour les crawlers — et elle est explicitement supportée par le standard IETF.
Comment s'assurer que tous les crawlers respectent ces directives ?
Impossible à garantir à 100%. Les crawlers majeurs (Google, Bing, Yandex) respectent le standard, mais les bots tiers et scrapers font ce qu'ils veulent. Surveillez vos logs serveur pour détecter les comportements anormaux.
Pour les bots agressifs qui ignorent robots.txt, passez par un blocage serveur (user-agent filtering, rate limiting, ou WAF). Le robots.txt n'a jamais été une barrière technique — juste une convention de politesse.
- Tester son robots.txt via la Search Console et corriger les éventuelles ambiguïtés
- Vérifier que les wildcards (*) sont utilisés conformément au standard IETF
- Supprimer les directives non-standard (Crawl-delay côté Google, par exemple)
- Déclarer explicitement le sitemap XML via la directive Sitemap:
- Ne pas confondre blocage du crawl (robots.txt) et blocage de l'indexation (noindex)
- Surveiller les logs serveur pour détecter les bots qui ignorent robots.txt
- Mettre en place des restrictions serveur pour les crawlers agressifs
La standardisation IETF du robots.txt apporte surtout de la cohérence et de la prévisibilité. Pour les SEO, c'est l'occasion de faire un audit de son fichier et de s'assurer qu'il respecte les bonnes pratiques formalisées.
Si votre configuration actuelle est complexe — multiples user-agents, règles imbriquées, gestion cross-domaine — un accompagnement SEO technique peut s'avérer précieux pour éviter les erreurs de parsing qui impacteraient le crawl. Une agence spécialisée vous aidera à anticiper les cas limites et à optimiser vos directives selon les spécificités de votre infrastructure.
❓ Questions frequentes
Le robots.txt empêche-t-il vraiment l'indexation d'une page ?
Dois-je modifier mon robots.txt suite à cette standardisation ?
Tous les crawlers respectent-ils désormais cette norme IETF ?
Quelle est la différence entre robots.txt et la balise noindex ?
La directive Crawl-delay est-elle supportée par le standard IETF ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 17/04/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.