Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Pourquoi la standardisation du robots.txt par l'IETF change-t-elle la donne pour les crawlers ?
- □ Pourquoi Google limite-t-il la taille de robots.txt à 500 Ko ?
- □ Les flux RSS et Atom sont-ils vraiment utilisés par Google pour découvrir vos contenus ?
- □ Les sitemaps XML sont-ils vraiment indispensables sans standardisation officielle ?
- □ Pourquoi robots.txt reste-t-il indispensable même pour les sites modernes ?
- □ Pourquoi Google a-t-il ouvert le code de son parseur robots.txt ?
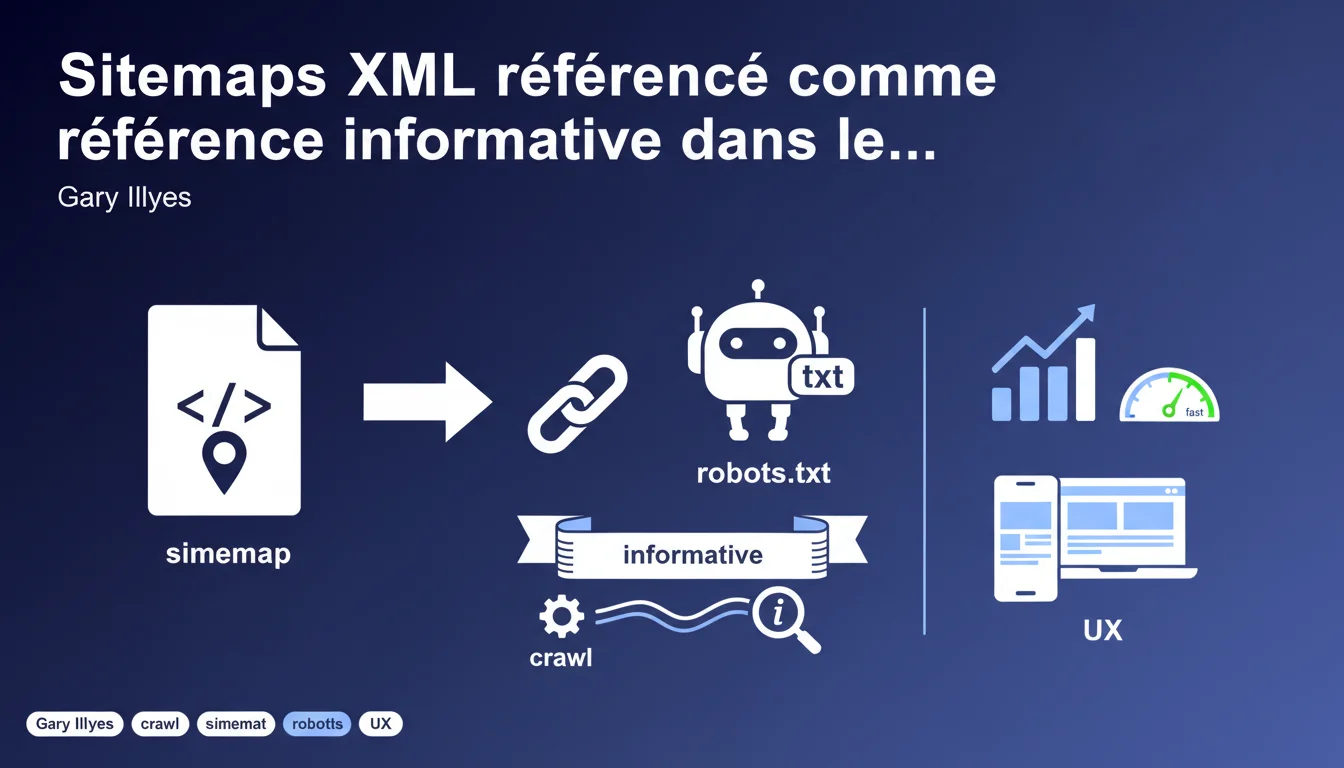
L'IETF intègre les sitemaps XML comme référence informative dans le standard robots.txt, créant un lien formel entre ces deux mécanismes. Cette reconnaissance officialise une pratique déjà courante, mais soulève des questions sur l'impact réel pour le crawl et l'indexation. Concrètement, rien ne change dans l'immédiat — mais cette normalisation pourrait ouvrir la voie à des évolutions futures.
Ce qu'il faut comprendre
Qu'est-ce que cette référence informative change concrètement ?
Le standard robots.txt de l'IETF (Internet Engineering Task Force) mentionne désormais les sitemaps XML comme référence informative. Ce lien formel reconnaît que ces deux fichiers — historiquement séparés — fonctionnent en tandem pour guider les crawlers.
En pratique, la directive Sitemap: dans le robots.txt existait déjà depuis des années. Google et Bing l'utilisent quotidiennement. Cette normalisation ne modifie pas le comportement des moteurs, mais elle ancre cette pratique dans un cadre standardisé.
Pourquoi formaliser un lien qui existait déjà ?
Parce que jusqu'ici, rien n'obligeait les moteurs à respecter ou même reconnaître la directive Sitemap: dans le robots.txt. C'était une convention tacite, non documentée dans un standard officiel.
Cette formalisation garantit une cohérence entre moteurs et outils tiers. Elle clarifie également le rôle du robots.txt : non seulement bloquer l'accès, mais aussi indiquer où trouver les URLs à crawler.
Quels sont les bénéfices pour un site web ?
- Centralisation : déclarer les sitemaps directement dans le robots.txt évite de passer par la Search Console ou les outils webmaster.
- Automatisation : les nouveaux crawlers ou robots tiers peuvent découvrir les sitemaps sans configuration manuelle.
- Validation : un standard reconnu facilite l'audit et le contrôle qualité des fichiers techniques.
- Pérennité : cette reconnaissance réduit le risque que Google ou d'autres acteurs ignorent cette directive à l'avenir.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Totalement. La directive Sitemap: dans le robots.txt fonctionne depuis au moins 15 ans. Google l'a toujours respectée, au même titre que la déclaration via Search Console.
Ce qui interpelle, c'est le timing. Pourquoi officialiser maintenant une pratique déjà universelle ? Soit Google anticipe une évolution future du crawl (traitement différencié selon la source du sitemap ?), soit l'IETF cherche simplement à documenter l'existant. [À vérifier] : aucune donnée publique ne confirme un changement de comportement côté Googlebot.
Faut-il s'attendre à un impact sur le crawl budget ou l'indexation ?
Non, pas dans l'immédiat. Les sites qui déclarent déjà leur sitemap dans le robots.txt ne verront aucun changement. Ceux qui ne le font pas peuvent continuer à utiliser la Search Console sans problème.
Le seul cas où cette formalisation compte : les sites avec plusieurs sitemaps ou des architectures complexes. Centraliser toutes les déclarations dans le robots.txt simplifie la gestion — mais encore faut-il que l'équipe tech maintienne ce fichier à jour. Un sitemap obsolète déclaré dans le robots.txt peut poser plus de problèmes qu'il n'en résout.
Quelles nuances faut-il apporter ?
Cette normalisation ne rend pas le robots.txt indispensable pour déclarer un sitemap. Google continue d'accepter les déclarations via Search Console, qui restent la méthode la plus fiable pour suivre les erreurs d'indexation.
Autre point : la directive Sitemap: n'influence pas la priorité de crawl. Un moteur peut ignorer un sitemap entier s'il juge le contenu de faible qualité ou déjà connu. Formaliser le lien ne change rien à cette réalité.
Impact pratique et recommandations
Que faut-il faire concrètement après cette annonce ?
Si votre robots.txt contient déjà une ou plusieurs directives Sitemap:, vérifiez qu'elles pointent vers des URLs valides et à jour. Un sitemap 404 ou obsolète peut ralentir le crawl — mieux vaut le retirer que le laisser en erreur.
Si vous n'utilisez pas encore cette méthode, testez-la en parallèle de la Search Console. Déclarez votre sitemap principal dans le robots.txt et surveillez les logs serveur pour confirmer que Googlebot le récupère bien.
Quelles erreurs éviter absolument ?
Ne multipliez pas les déclarations incohérentes. Si un sitemap est listé dans le robots.txt et dans la Search Console avec des URLs différentes, Google privilégiera celui de la Search Console — mais vous créez de la confusion dans vos audits.
Autre piège : déclarer un sitemap index dans le robots.txt sans maintenir les sous-sitemaps à jour. Si un sous-sitemap renvoie une erreur 500, tout l'index devient suspect. Mieux vaut déclarer directement les sitemaps finaux.
Comment vérifier que votre configuration est optimale ?
- Ouvrez votre fichier robots.txt : chaque ligne Sitemap: doit pointer vers une URL accessible en HTTPS et retournant un code 200.
- Testez chaque sitemap dans la Search Console pour vérifier qu'il ne contient pas d'erreurs de parsing ou d'URLs bloquées.
- Analysez vos logs serveur : Googlebot doit requêter le robots.txt avant de crawler les URLs du sitemap. Si ce n'est pas le cas, le lien n'est peut-être pas exploité.
- Documentez la méthode de déclaration choisie (robots.txt, Search Console, ou les deux) pour éviter les doublons lors des audits futurs.
- Automatisez la mise à jour du robots.txt si votre CMS génère dynamiquement des sitemaps. Un fichier statique devient rapidement obsolète.
❓ Questions frequentes
Dois-je obligatoirement déclarer mon sitemap dans le robots.txt maintenant ?
Si je déclare mon sitemap dans le robots.txt, puis-je supprimer celui de la Search Console ?
Un sitemap déclaré dans le robots.txt est-il crawlé plus rapidement ?
Que se passe-t-il si plusieurs sitemaps sont déclarés dans le robots.txt et la Search Console ?
Cette normalisation impacte-t-elle les autres moteurs de recherche comme Bing ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 17/04/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.