Official statement
Other statements from this video 7 ▾
- □ La méthode de production du contenu importe-t-elle vraiment pour Google ?
- □ Le système de contenu utile de Google peut-il vraiment distinguer l'intention éditoriale ?
- □ Faut-il vraiment lire les guidelines Google pour comprendre leurs critères de qualité ?
- □ Le robots.txt suffit-il vraiment à contrôler le crawl de zones spécifiques de votre site ?
- □ Comment Google Extended permet-il de bloquer l'indexation pour Bard et Vertex AI ?
- □ Le robots.txt est-il vraiment respecté par tous les crawlers ?
- □ Les CMS intègrent-ils vraiment les nouvelles options SEO aussi rapidement que Google le prétend ?
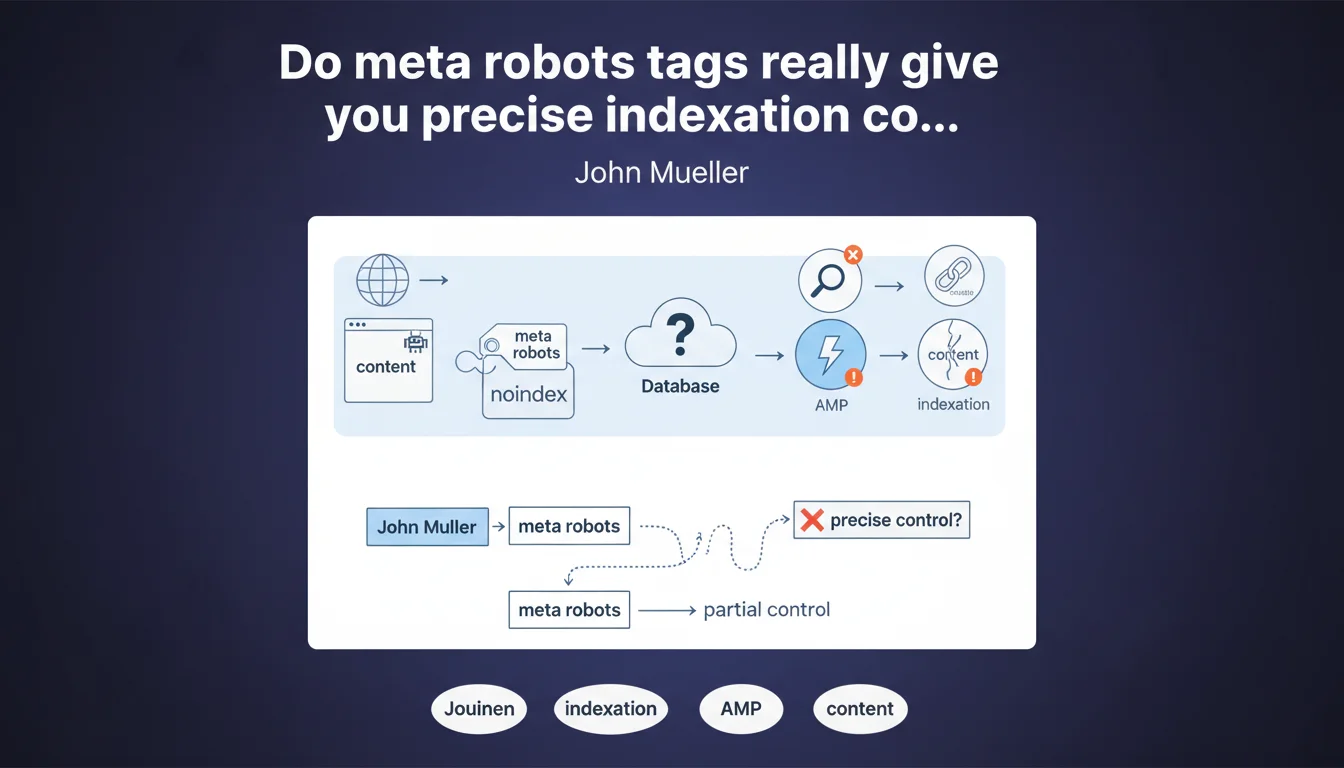
Google confirms that meta robots tags offer granular control at the individual page level. The noindex tag specifically prevents content from being indexed in public search results. It's a direct lever to manage what should or shouldn't appear in the SERP.
What you need to understand
What exactly are meta robots tags?
Meta robots tags are HTML tags placed in the <head> section of a page. They transmit instructions to crawling bots — not just Google, but all search engines that respect the standard.
Unlike robots.txt which blocks crawling upstream, these tags intervene after the bot has accessed the page. They dictate what can be done with the retrieved content: indexation, link following, caching, snippet display.
Why does Mueller emphasize the word "granular"?
Because each page can carry its own directives. A product page can authorize full indexation, while an internal search page receives a noindex. A technical specification allows snippets, a confidential PDF blocks them.
This unit-level flexibility contrasts with robots.txt, which works by URL pattern and blocks in bulk. Meta tags enable surgical decisions page by page.
What are the most common directives?
- noindex: excludes the page from public search results
- nofollow: prevents following of outbound links on the page
- noarchive: prohibits caching of the page
- nosnippet: blocks display of content excerpts in SERPs
- max-snippet:[number]: limits the length of displayed snippets
- max-image-preview:[setting]: controls the size of image previews
- max-video-preview:[number]: sets the maximum video preview duration
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. noindex has worked reliably for years — it's probably one of the best-respected directives by Google. When a page carries this tag, it disappears from the index within a variable timeframe (a few days to a few weeks depending on crawl frequency).
Be careful though: a noindex does not prevent crawling. The page is still visited, consumes crawl budget, and passes PageRank if it receives links. It's a nuance that many overlook.
What limitations should you know about?
First pitfall: if Google cannot crawl the page (blocked by robots.txt), it will never see the meta tag. The page then remains indexed with a truncated snippet "No information available". This is a classic misconfiguration case.
Second point — combined directives can create side effects. A noindex + nofollow on a hub page blocks indexation AND cuts PageRank flow to target pages. Before stacking tags, you must understand the cascading implications.
[To verify]: Mueller doesn't specify the average delay for a newly added noindex to take effect. Based on our observations, it varies between 3 days and 6 weeks depending on site authority and crawl frequency — but Google doesn't document an SLA.
In which cases does this directive fail?
If the tag is malformed (syntax error, improperly closed tag), Google silently ignores it. Same if the tag appears in the <body> instead of the <head>, or if it's injected via JavaScript without SSR — Googlebot may not see it in time.
Practical impact and recommendations
What should you actually do to leverage these tags?
First, audit what exists. Crawl your site with Screaming Frog or OnCrawl and extract all pages carrying meta robots tags. Compare with what's actually indexed in Google (via site: or Search Console).
Then define a clear strategy: which page types should be excluded from the index? Internal search pages, parameterized filters, technical duplicate content, member areas, thank-you pages after form submission — all of that deserves a noindex.
Implement tags at the template level, not page by page manually. If you're on WordPress, use an SEO plugin to inject directives conditionally based on content type. On custom builds, add rules in your controllers.
What mistakes should you absolutely avoid?
Never block via robots.txt a page you want to deindex. Google must be able to crawl the page to read the noindex. If you block crawling, the page remains in the index with an empty snippet.
Don't confuse noindex and canonical. A canonical redirects the signal to another URL — it doesn't prevent indexation. If you really want to exclude a page, it's noindex, not canonical to itself.
Watch for conflicts between meta tags and X-Robots-Tag headers. If your server sends a noindex header on all pages by mistake (it happens after a bad nginx/Apache change), all your pages disappear from the index, HTML meta tag or not.
How do you verify that everything is working correctly?
- Crawl the site and extract meta robots tags from each page
- Check through Search Console the excluded pages with reason "Excluded by 'noindex' tag"
- Test a few URLs with the URL Inspection tool to confirm Google sees the tag
- Control HTTP headers with curl or a proxy (Fiddler, Charles) to detect any X-Robots-Tag
- Monitor the number of indexed pages (Search Console > Coverage) after adding/removing noindex
- Set up alerts if the number of indexed pages drops sharply (symptom of accidental global noindex)
❓ Frequently Asked Questions
Un noindex empêche-t-il le crawl de la page ?
Peut-on combiner noindex et canonical sur la même page ?
Le X-Robots-Tag en HTTP header fonctionne-t-il pareil que le meta tag HTML ?
Combien de temps faut-il pour qu'une page noindexée disparaisse de l'index ?
Un nofollow au niveau page bloque-t-il tous les liens sortants ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 01/11/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.