Official statement
Other statements from this video 7 ▾
- □ La méthode de production du contenu importe-t-elle vraiment pour Google ?
- □ Le système de contenu utile de Google peut-il vraiment distinguer l'intention éditoriale ?
- □ Faut-il vraiment lire les guidelines Google pour comprendre leurs critères de qualité ?
- □ Le robots.txt suffit-il vraiment à contrôler le crawl de zones spécifiques de votre site ?
- □ Comment Google Extended permet-il de bloquer l'indexation pour Bard et Vertex AI ?
- □ Les robots meta tags permettent-ils vraiment un contrôle précis de l'indexation ?
- □ Les CMS intègrent-ils vraiment les nouvelles options SEO aussi rapidement que Google le prétend ?
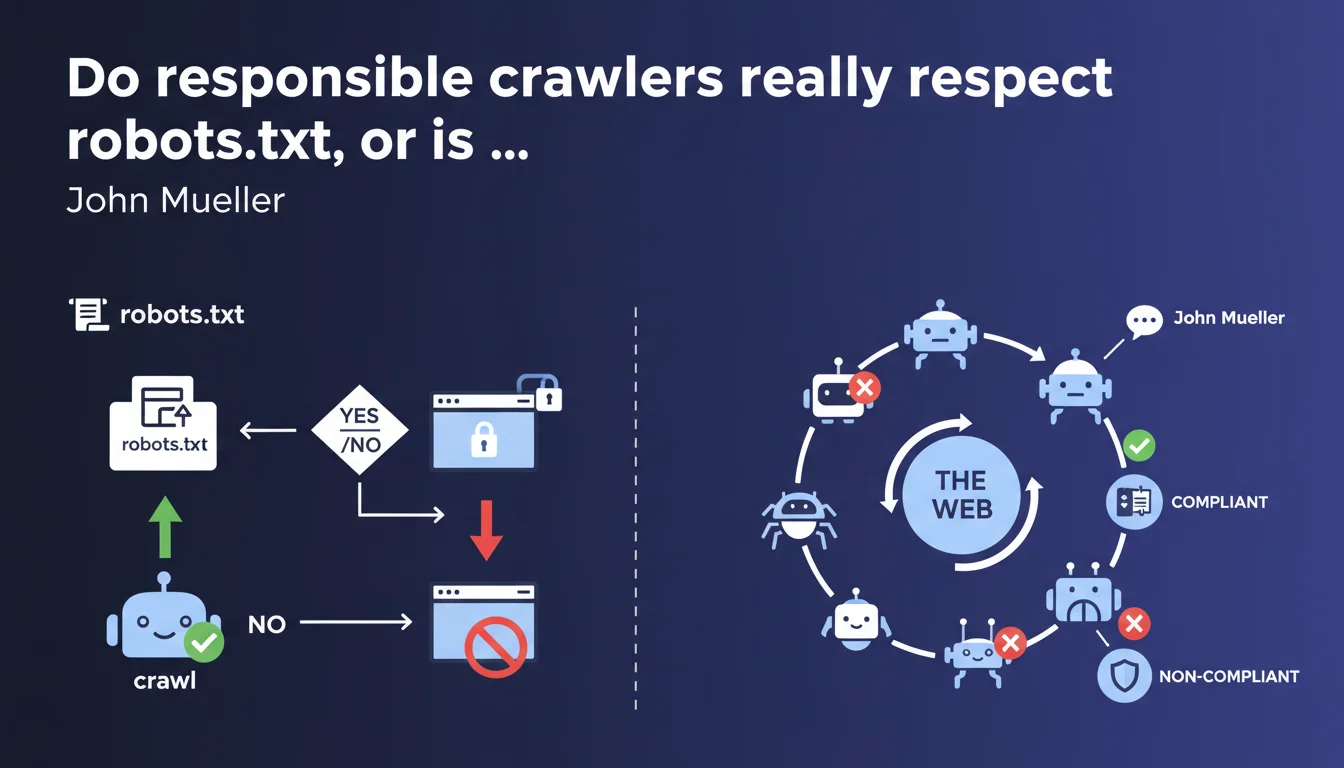
John Mueller reminds us that responsible crawlers have respected the robots.txt protocol for decades. This text file offers definitive access control, but only for crawlers that voluntarily choose to comply with it. The emphasis is on 'responsible' and 'chooses' — two words that change everything.
What you need to understand
Why does Google insist on the term 'responsible'?
The wording is not trivial. Mueller talks about responsible crawlers, not "all crawlers." This nuance signals that respecting robots.txt is a voluntary approach, not a technical obligation.
Established search engines (Google, Bing, Yandex) respect this protocol by convention. But nothing prevents a malicious bot, scraper, or third-party crawler from ignoring it completely. The robots.txt is not a security lock — it's a polite request addressed to good faith actors.
What does 'definitive access control' mean in this context?
The phrase 'definitive access control' can be misleading. Google is not saying that robots.txt prevents access, but rather that it clearly defines what is allowed or not for crawlers that respect it.
For Googlebot and similar crawlers, the file's directives are indeed binding. But this control only applies if the crawler decides to play by the rules. In other words: it's definitive for those who comply, not for everyone.
Is robots.txt enough to protect sensitive content?
No. And this is a point Google regularly emphasizes. The robots.txt blocks crawling, not human access or indexation of URLs discovered through other means (via external links, for example).
If you have truly confidential content, you need server-level authentication (htaccess, mandatory login) or a noindex directive combined with technical blocking. The robots.txt alone is not sufficient to secure anything.
- The robots.txt is a voluntary protocol, not an impenetrable technical barrier
- Established search engines respect it, but not malicious bots or certain scrapers
- It controls crawling, not indexation or direct URL access
- File readable by everyone — never list sensitive paths you actually want to hide
- For confidential content, use proper server-level authentication
SEO Expert opinion
Is this statement consistent with practices observed in the field?
Yes, broadly speaking. Googlebot scrupulously respects the robots.txt — this is verifiable in server logs. When a section is blocked, the bot doesn't access it, even if internal links point to those pages.
But — and this is where it gets tricky — some third-party crawlers, particularly those from SEO tools, data aggregators, or commercial scrapers, completely ignore the file. We regularly observe in logs bots that access sections explicitly forbidden. Mueller speaks of the 'responsible' ones, which de facto excludes all actors who don't recognize themselves in this category.
What nuances should be added to this narrative?
First point: robots.txt guarantees no confidentiality. It is publicly accessible and can even serve as a treasure map for malicious actors seeking sensitive sections. Blocking /admin/ in robots.txt amounts to saying "look over here."
Second point: a URL blocked from crawling can still be indexed if discovered via an external backlink. Google will display it in the SERPs without a snippet or description, but the URL will be visible. To prevent this, you must combine robots.txt and a meta noindex tag — which requires temporarily allowing crawling so Google can read the tag. [To verify] exact timeframes for application depending on contexts.
In what cases does this rule not fully apply?
The robots.txt has no effect on non-compliant crawlers. Scraping bots, certain competitive analysis tools, or advertising network crawlers don't always bother with the protocol.
Furthermore, Mueller doesn't specify behavior in edge cases: poorly defined generic user-agents, crawlers masking their identity, or situations where the file is temporarily inaccessible (server error). Google has previously indicated that if robots.txt fails, it suspends crawling as a precaution — but this tolerance is not universal.
Practical impact and recommendations
What should you concretely do with your robots.txt file?
First, audit your existing file. Check that it doesn't accidentally block critical resources: CSS, JS, images needed for rendering, or strategic pages. Google Search Console offers a robots.txt tester — use it systematically after every modification.
Next, adopt a minimalist approach. Block only what truly needs blocking: test pages, staging environments, internal search engines, parameterized URLs without SEO value. Avoid creating an endless list of directives that complicates maintenance.
What mistakes should you absolutely avoid?
Classic mistake: blocking resources (JS/CSS) that Google must crawl to properly render the page. For several years now, Google needs to execute JavaScript to index certain content. If you block .js or .css files, you risk incomplete rendering and indexation problems.
Another trap: listing sensitive paths in robots.txt thinking you're protecting them. It's the opposite — you're publicly announcing their existence. If /backoffice/ or /staging/ must remain confidential, don't mention them at all and secure them differently.
Finally, don't rely on robots.txt to manage crawl budget in a granular way. It's a binary tool (blocked/allowed). To optimize crawling, work on site architecture, internal linking, server speed, and content quality.
How can you verify everything is working as intended?
Three essential verifications. First, use the robots.txt tester in Google Search Console to validate syntax and test specific URLs.
Second, analyze your server logs to confirm that Googlebot properly respects the directives and identify any unwanted crawlers ignoring them. If certain bots cause problems, block them at the server level (htaccess, firewall).
Third, monitor indexation via Search Console and targeted site: queries. If pages blocked from crawling still appear in the index, they're being discovered through external links. Add a noindex tag and temporarily allow crawling so Google can read it.
- Audit the current robots.txt to identify accidental blocking of critical resources
- Test every modification with the Search Console tool before pushing to production
- Never block CSS, JS, or images necessary for rendering strategic pages
- Avoid listing sensitive paths — use proper server-level authentication instead
- Analyze logs to verify Googlebot's compliance with directives
- Identify and block non-compliant unwanted crawlers at the server level
- Monitor indexation to detect URLs blocked from crawling but indexed via backlinks
- Combine robots.txt and meta noindex for complete control over sensitive content
❓ Frequently Asked Questions
Le robots.txt empêche-t-il réellement l'indexation d'une page ?
Peut-on lister des sections sensibles dans le robots.txt pour les protéger ?
Tous les crawlers respectent-ils le robots.txt ?
Faut-il bloquer les fichiers CSS et JavaScript dans le robots.txt ?
Comment savoir si Googlebot respecte bien mes directives robots.txt ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 01/11/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.