Official statement
Other statements from this video 16 ▾
- □ Les Web Components JavaScript sont-ils vraiment crawlables par Google ?
- □ Le balisage FAQ Schema impose-t-il un format strict de présentation ?
- □ Le balisage FAQ Schema garantit-il vraiment l'affichage des FAQ snippets dans Google ?
- □ Faut-il vraiment éviter de dupliquer son propre contenu pour le SEO ?
- □ Pourquoi Google pénalise-t-il les variations excessives d'un même contenu ?
- □ Comment vérifier si Googlebot voit vraiment votre contenu JavaScript ?
- □ WordPress pénalise-t-il vraiment le référencement par rapport au HTML statique ?
- □ Pourquoi vos pages ne sont-elles pas indexées malgré un site techniquement irréprochable ?
- □ Pourquoi les études utilisateurs externes sont-elles devenues incontournables pour résoudre les problèmes de qualité ?
- □ Les backlinks vers des 404 sont-ils vraiment perdus pour le SEO ?
- □ Le disavow tool efface-t-il vraiment toute trace des liens toxiques dans les algorithmes Google ?
- □ Un certificat SSL peut-il vraiment pénaliser votre référencement ?
- □ Une baisse progressive multi-domaines révèle-t-elle un problème de qualité plutôt que technique ?
- □ Les problèmes techniques SEO ont-ils vraiment un impact immédiat sur vos rankings ?
- □ Bloquer Google Translate impacte-t-il vraiment votre référencement ?
- □ La balise meta notranslate peut-elle vraiment bloquer le lien « Traduire cette page » dans les SERP Google ?
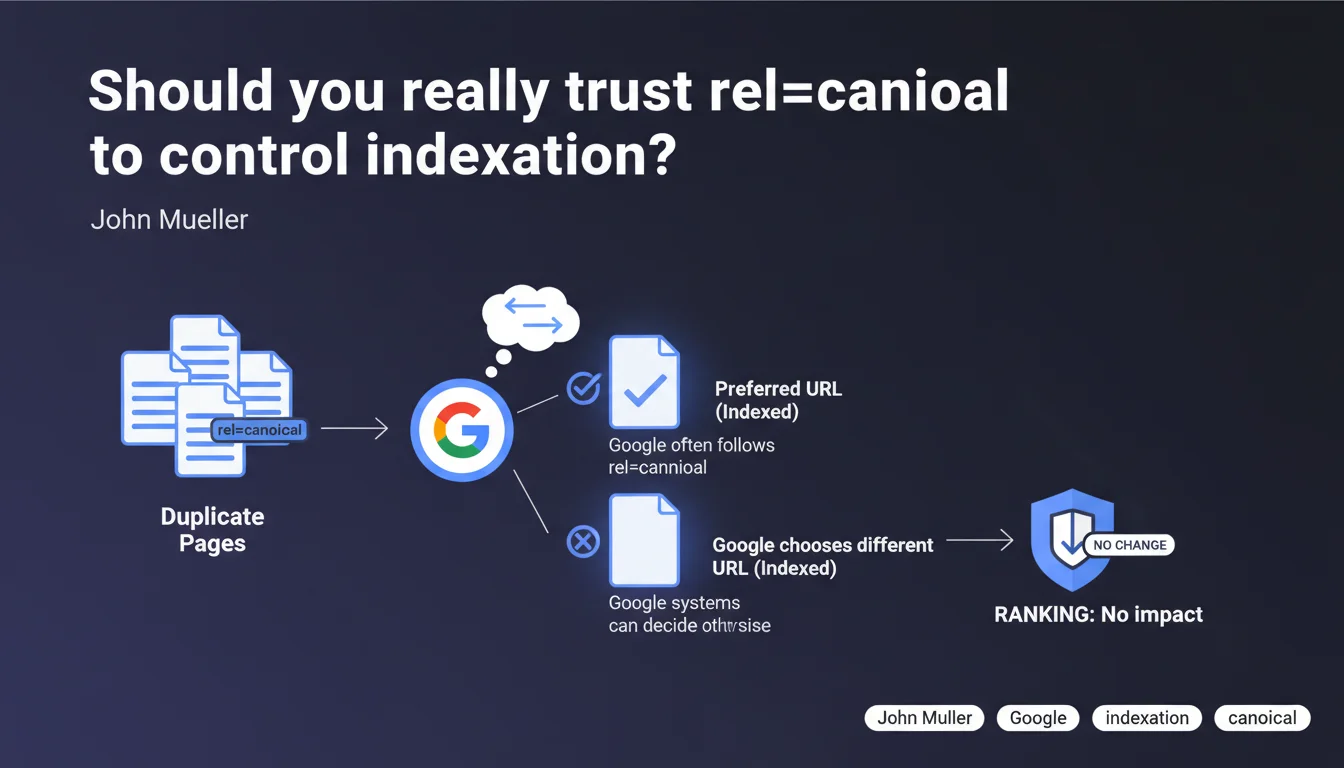
Google treats rel=canonical as a simple signal, not as an imperative directive. Its algorithms can decide to index a different URL than the one indicated, without affecting rankings. In practice: you suggest, Google decides.
What you need to understand
What is the true nature of rel=canonical according to Google?
The rel=canonical is not an instruction that Google executes blindly. It's a signal among others that algorithms evaluate to determine which URL deserves to be indexed when multiple pages present identical or very similar content.
Google can therefore ignore your canonical tag if its systems believe that another URL better represents the content. This decision is based on multiple signals: internal and external links, redirects, sitemaps, and crawl history.
Why doesn't Google always follow our indications?
Google's algorithms seek to identify the most relevant version of a page for the user. If your technical signals are contradictory — for example, you canonicalize to A but 80% of your internal links point to B — Google can legitimately prefer B.
This flexibility also allows Google to correct obvious mistakes: a canonical pointing to a 404, a page with noindex, or a completely off-topic URL.
Does this impact my SEO?
No, according to Mueller. The fact that Google chooses a different URL than your canonical does not affect rankings. Relevance and authority signals are consolidated on the URL that Google considers canonical, whatever it may be.
But be careful: if Google systematically indexes unwanted URLs, it's often a symptom of an inconsistent technical architecture. The problem isn't the ignored canonical, but the contradictory signals you're sending.
- rel=canonical is a signal, not an absolute directive
- Google can choose a different URL if its algorithms judge it more relevant
- Contradictory signals (links, redirects, sitemaps) weaken the canonical's effectiveness
- This doesn't impact rankings, but often reveals structural problems
- Signal consolidation happens on the URL Google deems canonical
SEO Expert opinion
Does this statement match real-world observations?
Yes, absolutely. Any SEO who has worked on complex sites has already noticed that Google sometimes ignores canonicals. Typical cases: filtered facets that remain indexed despite a canonical to the parent page, or geographic/language variants where Google favors a regional version.
What's more interesting — and what Mueller glosses over — is the hierarchy of signals. In my observations, a canonical consistent with internal links, XML sitemap, and the absence of suspicious parameters in the URL is followed 95%+ of the time. When Google ignores it, it's rarely arbitrary.
What nuances are missing from this statement?
Mueller says that "this doesn't affect rankings," which is technically true and practically misleading. If Google massively indexes non-optimized URLs (generic titles, partial content, technical parameters), your overall visibility suffers. Not because of a penalty, but through dilution.
[To verify] The notion that there's no impact on rankings deserves clarification. If Google consolidates signals on a different URL than the one you're optimizing — metadata, enriched content, internal linking — there is indeed an indirect impact.
In which cases does this principle fail most often?
E-commerce sites with multiple facets are the prime terrain for ignored canonicals. When you have 50 filter combinations and some accumulate external backlinks, Google hesitates to consolidate them to the parent page.
Another classic case: multilingual or multi-regional sites where Google judges that a local version deserves its own indexation, even if you try to canonicalize everything to a global URL. Hreflang tags and canonicals must work together, not against each other.
Practical impact and recommendations
What should you do concretely to maximize canonical effectiveness?
First, harmonize all your technical signals. An effective canonical doesn't live alone: it must be consistent with your internal linking, XML sitemap, 301 redirects, and — if relevant — your hreflang tags.
Next, verify in Search Console which URL Google actually selected as canonical. The URL inspection tool shows you "URL selected as canonical by Google" — if it differs from yours, investigate why rather than simply reinforcing the canonical.
- Audit consistency between canonicals, internal links, and XML sitemap
- Use the URL inspection tool to identify gaps between declared canonical and retained canonical
- Prioritize self-referencing canonicals (a page points to itself) on all URLs you want indexed
- Avoid canonical chains (A → B → C): always point to the final URL
- Never canonicalize to a page with noindex, 404, or under redirect
- For paginated content, ensure each page canonicalizes to itself unless an explicit strategy says otherwise
What critical mistakes must you absolutely avoid?
Never canonicalize to a URL that returns an HTTP code other than 200. Google ignores canonicals pointing to 301s, 404s, or 503s. This is a frequent mistake after migrations where old canonical URLs haven't been updated.
Also avoid "default" canonicals auto-generated by your CMS without strategic thought. I've seen sites where each category page canonicalized to the homepage — result: zero indexation of categories.
How do you verify that your canonicalization strategy is working?
Regularly export the coverage report from Search Console and cross-reference it with your declared canonicals. If you notice a significant gap between what you want indexed and what Google actually indexes, that's a red flag.
A crawl with Screaming Frog or Oncrawl lets you map all your canonicals and identify inconsistencies: orphaned pages being canonicalized, canonical chains, canonicals pointing to non-crawlable URLs.
❓ Frequently Asked Questions
Google suit-il toujours mes balises canonical ?
Si Google ignore mon canonical, est-ce que cela pénalise mon référencement ?
Comment savoir quelle URL Google a choisi comme canonique ?
Quels signaux influencent le choix de Google quand il ignore mon canonical ?
Peut-on forcer Google à respecter notre canonical ?
🎥 From the same video 16
Other SEO insights extracted from this same Google Search Central video · published on 08/05/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.