Official statement
Other statements from this video 15 ▾
- □ Comment Google jongle-t-il avec 40 signaux pour choisir l'URL canonique ?
- □ Clustering et canonicalisation : Google fait-il vraiment la différence entre ces deux processus ?
- □ Le rel canonical joue-t-il un double rôle dans l'algorithme de Google ?
- □ Que se passe-t-il quand vos signaux de canonicalisation se contredisent ?
- □ Comment Google choisit-il réellement entre HTTP et HTTPS dans ses résultats ?
- □ Pourquoi vos redirections multiples empêchent-elles Google de choisir la version HTTPS ?
- □ Google traite-t-il vraiment différemment les traductions de boilerplate et de contenu ?
- □ Google va-t-il vraiment faciliter le traitement du hreflang pour les sites fiables ?
- □ X-default est-il vraiment un signal canonique comme les autres ?
- □ Les pages d'erreur 200 créent-elles vraiment des trous noirs de clustering ?
- □ Les pages en soft 404 sont-elles vraiment les seules à créer des clusters problématiques ?
- □ Pourquoi un message d'erreur explicite peut-il sauver votre crawl budget ?
- □ Les redirections JavaScript vers des pages d'erreur sont-elles vraiment prises en compte par Google ?
- □ Pourquoi un no-index supprime-t-il une page plus vite qu'une erreur 404 ou 410 ?
- □ Un rel canonical vide peut-il vraiment supprimer tout votre site de l'index Google ?
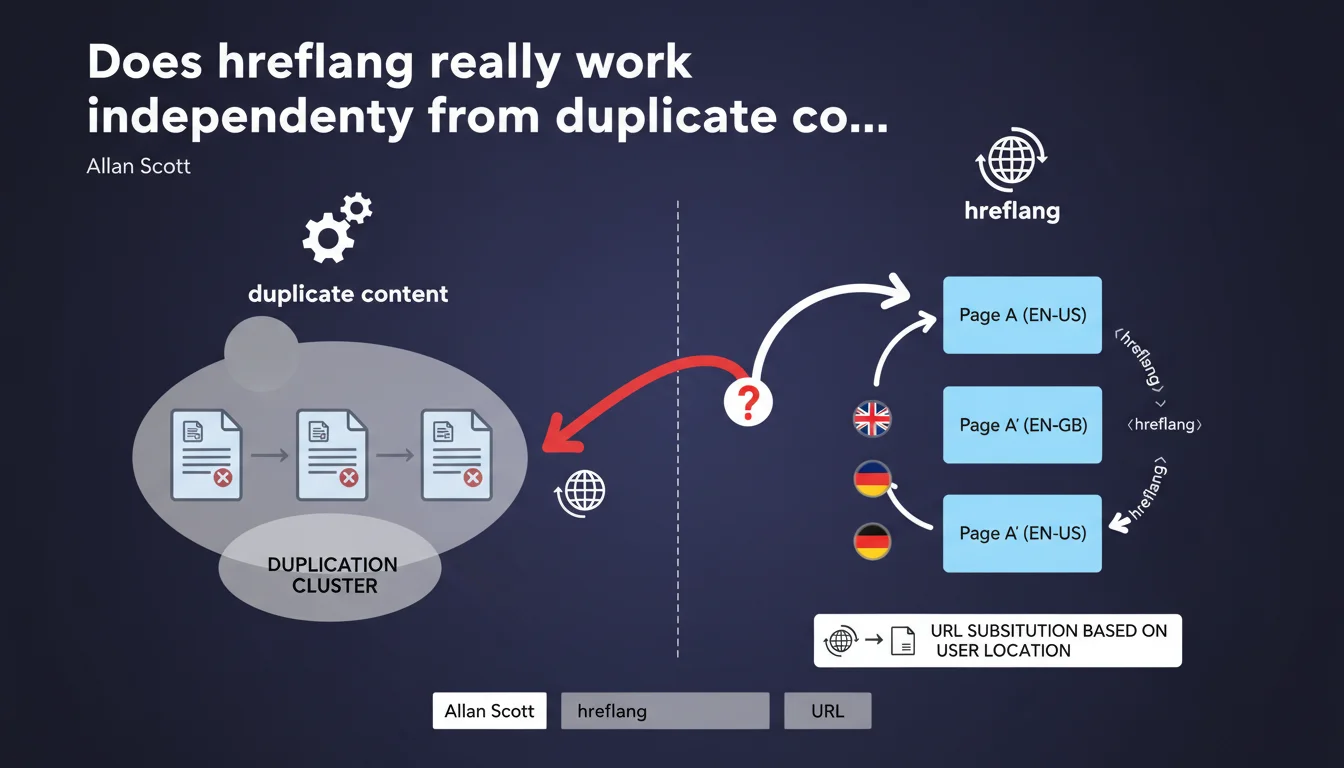
Google confirms that hreflang operates as a distinct system separate from duplicate content clustering. In concrete terms, even if your multilingual pages are considered duplicate content and grouped in the same cluster, hreflang can substitute the displayed URL based on the user's geolocation. This technical separation is a game-changer for international sites worried about cannibalization.
What you need to understand
What exactly is Google's duplicate content clustering?
Google automatically groups pages with nearly identical content into duplication clusters. The algorithm then selects one representative "canonical" URL that it prioritizes in search results, typically ignoring other variants in the cluster.
This mechanism creates problems for multilingual or multi-regional sites: similar translations or localized versions of the same page risk being treated as duplicate content. The result? Only one version appears, often one that doesn't match your target market.
How does hreflang fit into this process?
The hreflang tag tells Google about the relationships between language or geographical versions of a page. According to Allan Scott's statement, hreflang functions as a substitution system independent from clustering.
Even if Google groups your FR, EN, and ES pages in a single cluster, hreflang can replace the displayed URL with the one suited to the user's location. Clustering determines which page to prioritize for indexing, while hreflang determines which one to serve to which user.
Why does this independence change everything for international SEO?
Let's be honest: many practitioners believed that poor clustering would nullify hreflang's effect. This clarification shows that the two systems coexist without blocking each other.
If your hreflang implementation is correct, you can theoretically circumvent some negative effects of clustering. Google will display the right URL even if technically it selected another version as the cluster's canonical representative.
- Hreflang and clustering are two distinct mechanisms that operate at different levels
- Clustering manages which page to index, hreflang manages which URL to display to which user
- Solid hreflang implementation can partially compensate for unfavorable clustering
- This separation doesn't exempt you from optimizing content to avoid unintentional clustering
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes and no. In practice, many sites with correctly implemented hreflang do see the right language version display based on geolocation, even when Google Search Console flags duplicate content.
But — and here's where it gets tricky — we also observe cases where clustering seems to override hreflang. Pages with perfect markup disappear in favor of a dominant version in another language. [To verify]: Google doesn't clarify under what conditions hreflang can fail to substitute the URL if clustering is too aggressive.
What nuances should we add to this rule?
Allan Scott speaks of a substitution system, not prioritization for indexing. In other words, if your ES page is never crawled or indexed because Google excluded it from the cluster, hreflang can't do anything.
The statement remains unclear on one critical point: which version does Google prioritize for indexing when clustering activates? If it's systematically the EN version for a .com site, your Spanish users might see the correct URL... but that URL might never rank independently.
In which cases does this rule not fully apply?
When content is strictly identical across multiple URLs (for example, http/https versions, www/non-www, unnecessary parameters), Google treats this as pure technical duplication. Hreflang has nothing to do here — it's a classic canonicalization problem.
Another observed limitation: sites with poor machine translations or overly similar content between close languages (ES/PT, EN/EN-US). Clustering becomes so dominant that it sometimes seems to short-circuit hreflang, even though technically the systems are meant to be independent. [To verify] with larger-scale testing.
Practical impact and recommendations
What concretely should you do to leverage this independence?
First, ensure your hreflang implementation is flawless. Bidirectional tags, inclusion of x-default self-referencing, consistency between HTML and XML sitemaps. If hreflang operates independently from clustering, it becomes even more strategic to configure it correctly.
Next, differentiate your multilingual content sufficiently to minimize unintentional clustering. Even if hreflang can compensate, it's better to prevent Google from grouping your pages in the first place. Quality translations, cultural adaptations, structural variations — anything that breaks excessive similarity.
What mistakes must you avoid at all costs?
Don't rely solely on hreflang to manage intentional duplicate content. If you publish the same EN page across .com, .co.uk, and .com.au without adaptation, clustering will strike hard and hreflang doesn't guarantee that all versions will be indexed.
Another trap: neglecting canonical tags thinking that hreflang solves everything. The two systems are distinct but complementary. A poorly configured canonical can send contradictory signals to Google and sabotage your international strategy.
How can you verify that your site is truly benefiting from this independence?
Monitor in Google Search Console the coverage reports by language. If certain language versions are marked "Excluded: Duplicate" but still display for users in that country, that's hreflang doing its job despite clustering.
Test with VPNs or geo-targeted searches: verify that the right URL displays based on country, even if Search Console flags duplicate content. This is concrete proof that the two systems coexist as Google describes.
- Audit hreflang implementation (bidirectionality, x-default, consistency)
- Differentiate multilingual content beyond simple translation
- Verify consistency between hreflang and canonical tags
- Monitor coverage reports in Search Console by language
- Test URL display based on geolocations using VPN
- Optimize crawl budget so all versions are visited regularly
❓ Frequently Asked Questions
Hreflang peut-il empêcher totalement le clustering de contenu dupliqué ?
Si mes pages sont dans le même cluster, seront-elles toutes indexées ?
Dois-je toujours utiliser des canonical auto-référencées avec hreflang ?
Que se passe-t-il si hreflang et canonical pointent vers des URLs différentes ?
Comment différencier suffisamment mes contenus multilingues pour éviter le clustering ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 05/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.