Official statement
Other statements from this video 15 ▾
- □ Comment Google jongle-t-il avec 40 signaux pour choisir l'URL canonique ?
- □ Le rel canonical joue-t-il un double rôle dans l'algorithme de Google ?
- □ Que se passe-t-il quand vos signaux de canonicalisation se contredisent ?
- □ Comment Google choisit-il réellement entre HTTP et HTTPS dans ses résultats ?
- □ Pourquoi vos redirections multiples empêchent-elles Google de choisir la version HTTPS ?
- □ Google traite-t-il vraiment différemment les traductions de boilerplate et de contenu ?
- □ Hreflang fonctionne-t-il indépendamment du clustering de contenu dupliqué ?
- □ Google va-t-il vraiment faciliter le traitement du hreflang pour les sites fiables ?
- □ X-default est-il vraiment un signal canonique comme les autres ?
- □ Les pages d'erreur 200 créent-elles vraiment des trous noirs de clustering ?
- □ Les pages en soft 404 sont-elles vraiment les seules à créer des clusters problématiques ?
- □ Pourquoi un message d'erreur explicite peut-il sauver votre crawl budget ?
- □ Les redirections JavaScript vers des pages d'erreur sont-elles vraiment prises en compte par Google ?
- □ Pourquoi un no-index supprime-t-il une page plus vite qu'une erreur 404 ou 410 ?
- □ Un rel canonical vide peut-il vraiment supprimer tout votre site de l'index Google ?
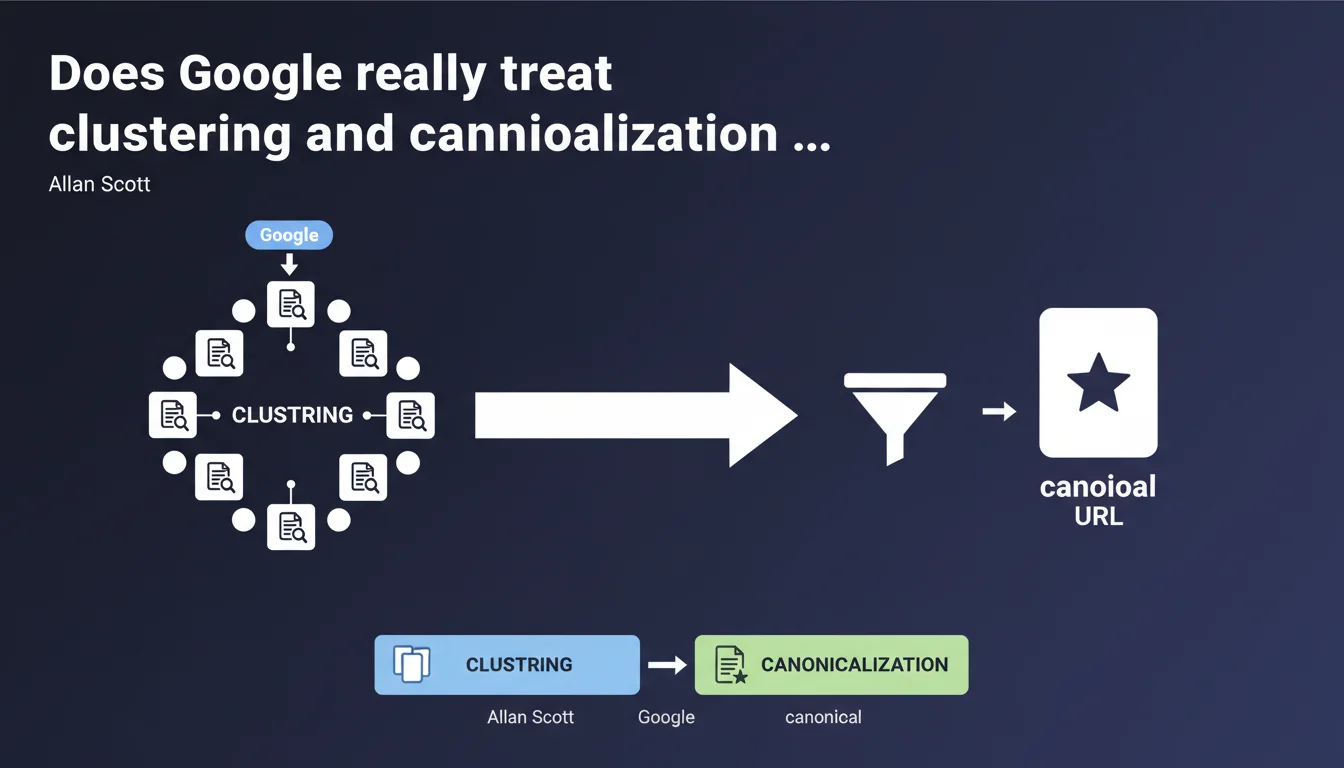
Google formally distinguishes between clustering and canonicalization. Clustering first groups pages that Google considers identical, then canonicalization selects the best URL within that group. Two sequential steps, not a single mechanism.
What you need to understand
Why does Google separate clustering and canonicalization?
Clustering happens upstream: Google crawls your pages and detects those with nearly identical content. It's an automatic process that creates groups without human intervention.
Canonicalization comes after. Once the cluster is formed, Google selects the representative URL — the one it will display in search results. This second step takes your signals into account (canonical tags, redirects, sitemap) but Google can ignore your preferences if they seem inconsistent.
What does this actually change for a website?
If you thought placing a canonical tag was enough to fix everything, this statement clarifies things. Google groups first, then chooses. Your canonical tags don't trigger clustering — they only influence the final selection.
In other words: even with flawless canonicals, if Google considers two pages identical, it will cluster them. Your tag will then play a role, but without absolute guarantee.
What signals trigger clustering at Google?
Google never reveals the complete details, but we know that textual similarity, HTML structure, and user behavior carry significant weight. Two pages with 95% identical content will end up in the same cluster, regardless of your editorial intentions.
The problem? You have no official report showing you which pages Google has clustered. You must deduce these groupings from indexed URLs, the canonicals Google chooses, and ranking fluctuations.
- Clustering: automatic grouping of similar pages
- Canonicalization: selection of the representative URL in each cluster
- Sequential process: clustering before canonicalization
- Your signals (canonical, redirects) influence step 2, not step 1
- No official report shows you the clusters formed by Google
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, and it explains a lot of frustrations. How many times have you seen Google ignore your canonical tag and choose a completely different URL? It's often linked to clustering: Google grouped your pages, then decided your preference wasn't the best choice.
Where it gets tricky: Google doesn't warn you when it forms a cluster. You discover the problem after the fact, when a wrong URL appears in the SERPs or when a strategic page disappears from the index. [To verify] on sites with heavy pagination or e-commerce facets — clusters can explode without any warning signal.
What nuances should be added to this claim?
Allan Scott talks about two "distinct and sequential" processes, but reality is more iterative. Google recrawls, regroups, and re-evaluates continuously. A cluster formed today can evolve tomorrow if you substantially modify a page.
Another point: saying Google "considers pages identical" remains vague. Identical to what degree? 80%? 95%? Google provides no numerical threshold. [To verify] through A/B testing with minor content variations — impossible to draw a clear boundary.
In what cases does this rule not apply?
If your pages are truly different (unique content, distinct structure, different user intent), no clustering. Makes sense. But the gray zone is massive: a product sheet available in 5 colors, regional landing pages with 70% shared text, translated articles with some local adaptations.
Google may cluster pages that you consider different, simply because its algorithm detects too much similarity. No absolute rules, just probabilities based on opaque signals.
Practical impact and recommendations
What should you do concretely to master clustering and canonicalization?
First, reduce similarities between pages you want indexed separately. If two pages share 90% of content, Google will cluster them — regardless of your tags. Enrich the content, differentiate structures, add unique sections.
Next, place coherent canonicals on true duplicates (pagination, filters, UTM parameters). Google will take them into account after clustering, but only if they're logical. A canonical pointing to a completely different page will be ignored.
How do you verify that Google isn't clustering your strategic pages?
Use Search Console: compare the URLs you submit (sitemap, internal linking) with those Google actually indexes. If a page disappears or if Google imposes a different canonical than yours, it's a signal of undesired clustering.
Test with site:yourdomain.com "unique excerpt" — choose a snippet of text present only on one target page. If Google returns another URL, it has clustered and chosen a different canonical.
What mistakes should you absolutely avoid?
Don't multiply cross-canonicals (page A to B, page B to C). Google will cluster everything and choose based on its own logic, ignoring your contradictory directives.
Avoid massive boilerplate content: identical headers/footers occupying 60% of HTML code, repeated advertising blocks everywhere. The lower the unique content / shared content ratio, the higher the risk of undesired clustering.
- Audit indexed pages vs. submitted pages in Search Console
- Substantially differentiate content on pages you want indexed separately
- Place coherent and unidirectional canonicals
- Monitor canonicals imposed by Google (coverage reports)
- Reduce boilerplate content in favor of unique content
- Test actual indexation with targeted
site:queries
Clustering and canonicalization are not interchangeable: Google groups first, then selects. Your signals (canonical, redirects, hreflang) influence the selection, but don't block the initial grouping.
To stay in control, truly differentiate your content and maintain strict editorial consistency. On complex architectures (e-commerce, multiregional, faceted sites), these optimizations require specialized expertise and continuous monitoring. Calling on a specialized SEO agency may be wise to diagnose invisible clusters and fine-tune your technical directives without risking massive deindexation.
❓ Frequently Asked Questions
Google peut-il clustériser des pages que je considère différentes ?
Une balise canonical empêche-t-elle le clustering ?
Comment savoir quelles pages Google a clustérisées ensemble ?
Que se passe-t-il si je pose une canonical vers une page très différente ?
Le clustering peut-il faire disparaître des pages stratégiques de l'index ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 05/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.