Official statement
Other statements from this video 8 ▾
- □ Pourquoi la limite de 15 Mo de Googlebot n'est-elle documentée que maintenant ?
- □ Quelles sont les 3 seules exigences techniques absolues pour être indexé par Google ?
- □ Faut-il vraiment ignorer ce que Google ne supporte pas ?
- □ Pourquoi Google a-t-il divisé ses guidelines en règles strictes et simples recommandations ?
- □ Comment prioriser vos actions SEO selon le système de classification de Google ?
- □ Google distingue-t-il vraiment les « exigences absolues » des « bonnes pratiques » en SEO ?
- □ Google distingue-t-il vraiment les changements de documentation des changements d'algorithme ?
- □ HTTPS et vitesse : peut-on vraiment s'en passer pour ranker sur Google ?
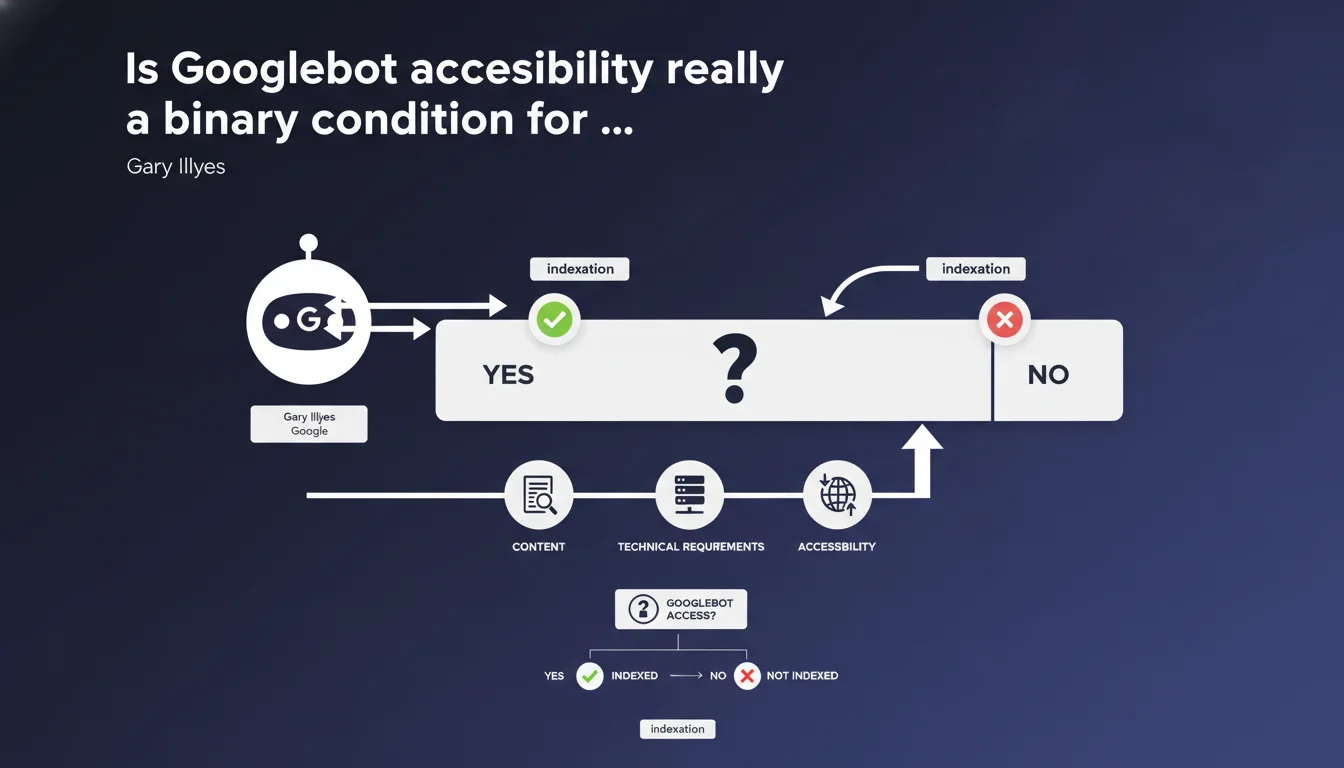
Gary Illyes clarifies that Googlebot accessibility is not a rule you can 'violate' — it's a binary technical condition: either Google can access the pages, or it cannot. This requirement is one of three absolute prerequisites for indexation, just like the absence of noindex and minimum content quality.
What you need to understand
Why does Google insist on the binary nature of accessibility?
This statement aims to clarify a frequent misunderstanding: Googlebot accessibility is not a ranking criterion you can 'optimize' gradually. It's a strict technical threshold.
Either the robot can reach your URLs (robots.txt allows it, server responds, no network blocking), or it cannot. There is no gray area — unlike signals like speed or internal linking, where progressive improvements make sense.
What are the three absolute technical requirements mentioned by Google?
Gary Illyes refers to a triptych of conditions: Googlebot accessibility, absence of noindex directive, and sufficient content quality to justify indexation.
Without the first, the other two have no importance. Exceptional content blocked by robots.txt will never be crawled. A page that is accessible but marked noindex will never be indexed even if Googlebot reads it.
How does this binary vision change the SEO approach?
It repositions accessibility as an infrastructure prerequisite, not as an optimization lever. You don't 'maximize' accessibility — you guarantee it or you fail.
This distinction is crucial for prioritizing technical projects. Before refining on-page signals, you must verify that Googlebot can physically access each strategic template.
- Googlebot accessibility is binary: no nuance possible
- It constitutes one of the three absolute prerequisites for indexation
- Without access, all other SEO efforts are completely useless
- Blockages can be multiple: robots.txt, server errors, firewall, infinite redirects
- This requirement is verified before even evaluating content or noindex directives
SEO Expert opinion
Is this statement consistent with field observations?
Yes, but it deliberately simplifies. On complex infrastructures (CDN, application firewalls, IP geolocation), accessibility can be partially degraded without being completely blocked.
Concrete example: a site accessible from Google's US datacenters but blocked from certain European IPs used for freshness crawling. Technically, Google 'accesses' the site — but not uniformly. The binary nature then becomes more blurred. [To verify] whether Google considers these situations as 'accessible' or 'blocked'.
What gray areas remain despite this assertion?
The notion of accessibility masks important technical nuances. Is a server that responds with a 200 code but loads content via asynchronous JavaScript 'accessible' in Google's strict sense?
Googlebot can technically reach the URL, but if rendering fails (JS timeout, blocked external dependencies), the content remains invisible. Google probably counts this as 'accessible' — but indexable is another story.
Another frequent case: sites that block Googlebot via User-Agent but accept other crawlers. Technically, the server is reachable — only the Google robot is refused. Is this an accessibility problem or a crawl policy issue? [To verify]
Should this statement be interpreted as a prioritization of technical priorities?
Absolutely. Gary Illyes implicitly signals that too many sites invest in advanced optimizations (schema markup, Core Web Vitals, linking) while basic accessibility is not guaranteed.
It's a blunt reminder: before chasing rich snippets, verify that Googlebot can physically crawl your strategic pages. An intermittent 503 error on key categories nullifies any on-page optimization.
Practical impact and recommendations
How do I concretely verify that my site is accessible to Googlebot?
Search Console remains the reference tool. The 'Coverage' report detects URLs blocked by robots.txt, server errors (5xx), timeouts, and misconfigured redirects.
Supplement with manual tests: use the 'URL Inspection' tool to force a real-time crawl. If Google cannot access, the exact cause appears (DNS, robots.txt, server error, timeout).
For complex infrastructures, audit server logs. Compare documented Googlebot IPs with your actual logs. If certain IP ranges are missing, your firewall or CDN is probably blocking part of the crawl.
What critical errors block accessibility without you realizing it?
Geo-blocked access is frequent: a site accessible from France but blocked from US datacenters where Googlebot operates. Misconfigured CDNs (Cloudflare, Fastly) can treat Googlebot like a malicious bot.
Another classic trap: overly broad robots.txt rules. A simple Disallow: /*? blocks all URLs with parameters — including essential e-commerce facets for indexation.
Redirect chains (A → B → C → D) consume crawl budget and can cause timeouts. Google often abandons after 5 hops. Technically, the site is 'accessible', but in practice, some pages are never reached.
What should you do immediately to secure accessibility?
- Audit the robots.txt file: no Disallow blocking strategic sections
- Verify HTTP codes returned to Googlebot (no intermittent 5xx errors)
- Test server response times: TTFB > 1s slows crawl and can cause abandonment
- Whitelist Googlebot IPs in firewall and CDN rules (official list published by Google)
- Eliminate redirect chains: maximum 2 hops between the entry URL and final destination
- Verify that critical resources (CSS, JS necessary for rendering) are not blocked
- Monitor server logs to detect 503 or 429 errors specific to Googlebot
- Test accessibility from multiple geographic locations (not just your country)
❓ Frequently Asked Questions
Un site peut-il être partiellement accessible à Googlebot ?
Si Googlebot accède à une page mais ne peut pas rendre le JavaScript, est-elle considérée comme accessible ?
Bloquer Googlebot via User-Agent suffit-il à rendre un site inaccessible ?
Combien de temps faut-il à Google pour détecter qu'un blocage a été levé ?
Les erreurs 503 temporaires comptent-elles comme un blocage d'accessibilité ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 22/12/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.