Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Pourquoi la limite de 15 Mo de Googlebot n'est-elle documentée que maintenant ?
- □ Quelles sont les 3 seules exigences techniques absolues pour être indexé par Google ?
- □ Faut-il vraiment ignorer ce que Google ne supporte pas ?
- □ Pourquoi Google a-t-il divisé ses guidelines en règles strictes et simples recommandations ?
- □ Comment prioriser vos actions SEO selon le système de classification de Google ?
- □ Google distingue-t-il vraiment les « exigences absolues » des « bonnes pratiques » en SEO ?
- □ Google distingue-t-il vraiment les changements de documentation des changements d'algorithme ?
- □ HTTPS et vitesse : peut-on vraiment s'en passer pour ranker sur Google ?
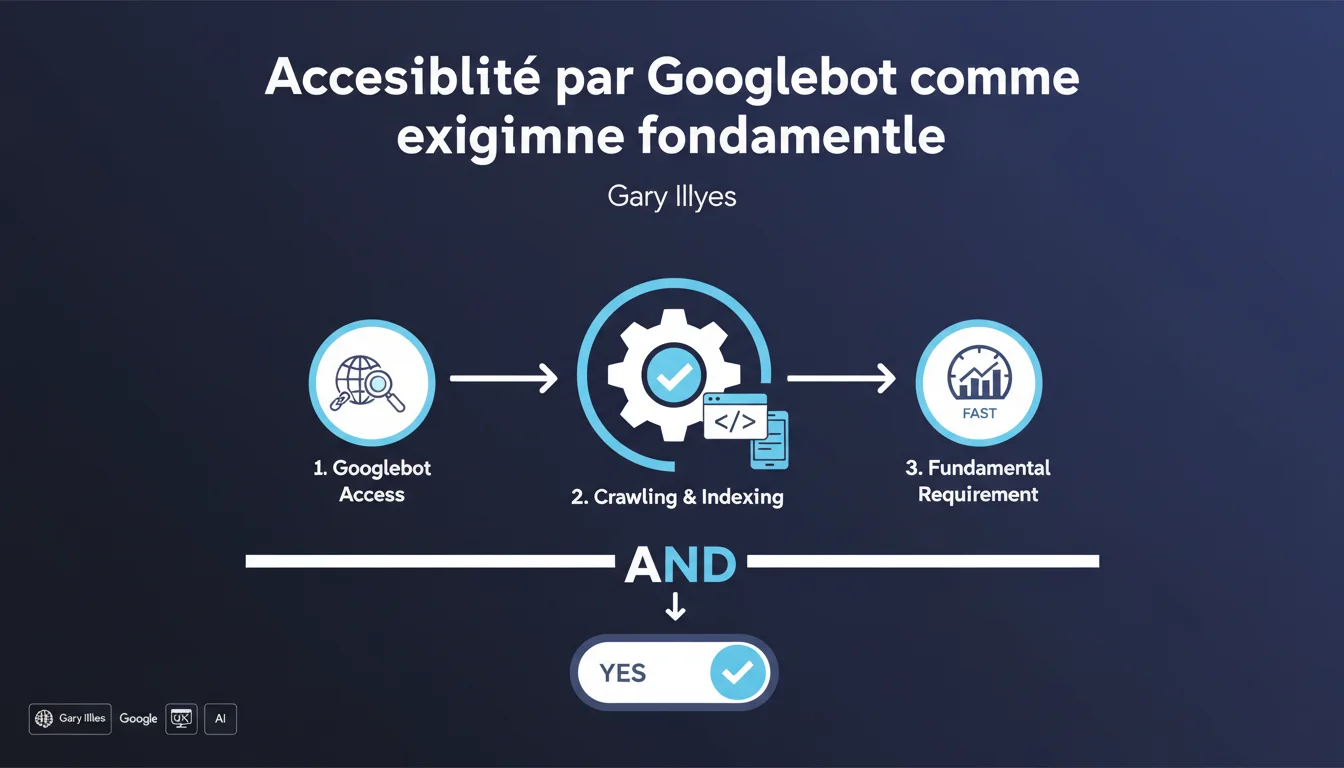
Gary Illyes précise que l'accessibilité par Googlebot n'est pas une règle qu'on peut « violer » — c'est une condition technique binaire : soit Google accède aux pages, soit il ne le peut pas. Cette exigence fait partie des trois prérequis absolus pour l'indexation, au même titre que l'absence de noindex et la qualité minimale du contenu.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur le caractère binaire de l'accessibilité ?
Cette déclaration vise à clarifier un malentendu fréquent : l'accessibilité Googlebot n'est pas un critère de classement qu'on peut « optimiser » graduellement. C'est un seuil technique strict.
Soit le robot peut atteindre vos URLs (robots.txt autorise, serveur répond, pas de blocage réseau), soit il ne le peut pas. Il n'y a pas de zone grise — contrairement à des signaux comme la vitesse ou le maillage interne, où des améliorations progressives ont du sens.
Quelles sont les trois exigences techniques absolues mentionnées par Google ?
Gary Illyes évoque un triptyque de conditions : accessibilité Googlebot, absence de directive noindex, et qualité suffisante du contenu pour justifier l'indexation.
Sans la première, les deux autres n'ont aucune importance. Un contenu exceptionnel bloqué par robots.txt ne sera jamais crawlé. Une page accessible mais marquée noindex ne sera jamais indexée même si Googlebot la lit.
En quoi cette vision binaire change-t-elle l'approche SEO ?
Elle repositionne l'accessibilité comme un prérequis infrastructure, pas comme un levier d'optimisation. On ne « maximise » pas l'accessibilité — on la garantit ou on échoue.
Cette distinction est capitale pour prioriser les chantiers techniques. Avant de peaufiner les signaux on-page, il faut vérifier que Googlebot peut physiquement accéder à chaque template stratégique.
- L'accessibilité Googlebot est binaire : aucune nuance possible
- Elle constitue l'un des trois prérequis absolus pour l'indexation
- Sans accès, tous les autres efforts SEO sont totalement inutiles
- Les blocages peuvent être multiples : robots.txt, erreurs serveur, pare-feu, redirections infinies
- Cette exigence se vérifie avant même l'évaluation du contenu ou des directives noindex
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, mais elle simplifie volontairement. Sur des infrastructures complexes (CDN, pare-feu applicatifs, géolocalisation IP), l'accessibilité peut être partiellement dégradée sans être totalement bloquée.
Exemple concret : un site accessible depuis les datacenters Google US mais bloqué depuis certaines IPs européennes utilisées pour le crawl de freshnesse. Techniquement, Google « accède » au site — mais pas uniformément. Le caractère binaire devient alors plus flou. [À vérifier] si Google considère ces situations comme « accessible » ou « bloqué ».
Quelles zones grises subsistent malgré cette affirmation ?
La notion d'accessibilité masque des nuances techniques importantes. Un serveur qui répond avec un code 200 mais charge du contenu en JavaScript asynchrone est-il « accessible » au sens strict de Google ?
Googlebot peut techniquement atteindre l'URL, mais si le rendu échoue (timeout JS, dépendances externes bloquées), le contenu reste invisible. Google compte probablement cela comme « accessible » — mais indexable, c'est une autre histoire.
Autre cas fréquent : les sites qui bloquent Googlebot via User-Agent mais acceptent d'autres crawlers. Techniquement, le serveur est joignable — seul le robot Google est refusé. Est-ce un problème d'accessibilité ou de politique de crawl ? [À vérifier]
Faut-il interpréter cette déclaration comme une hiérarchisation des priorités techniques ?
Absolument. Gary Illyes signale implicitement que trop de sites investissent dans des optimisations avancées (schema markup, Core Web Vitals, maillage) alors que l'accessibilité de base n'est pas garantie.
C'est un rappel brutal : avant de courir après les rich snippets, vérifiez que Googlebot peut physiquement crawler vos pages stratégiques. Une erreur 503 intermittente sur des catégories clés annule toute optimisation on-page.
Impact pratique et recommandations
Comment vérifier concrètement que mon site est accessible à Googlebot ?
La Search Console reste l'outil de référence. Le rapport « Couverture » détecte les URLs bloquées par robots.txt, les erreurs serveur (5xx), les timeouts et les redirections mal configurées.
Complétez avec des tests manuels : utilisez l'outil « Inspection d'URL » pour forcer un crawl en temps réel. Si Google ne peut pas accéder, la cause exacte apparaît (DNS, robots.txt, erreur serveur, timeout).
Pour les infrastructures complexes, auditez les logs serveur. Comparez les IPs Googlebot documentées avec vos logs réels. Si certaines plages IP sont absentes, votre pare-feu ou CDN bloque probablement une partie du crawl.
Quelles erreurs critiques bloquent l'accessibilité sans qu'on s'en rende compte ?
Les blocages géolocalisés sont fréquents : un site accessible depuis la France mais bloqué depuis les datacenters US où Googlebot opère. Les CDN mal configurés (Cloudflare, Fastly) peuvent traiter Googlebot comme un bot malveillant.
Autre piège classique : les règles robots.txt trop larges. Un simple Disallow: /*? bloque toutes les URLs avec paramètres — y compris les facettes e-commerce indispensables à l'indexation.
Les redirections en chaîne (A → B → C → D) consomment le budget crawl et peuvent provoquer des timeouts. Google abandonne souvent après 5 sauts. Techniquement, le site est « accessible », mais en pratique, certaines pages ne sont jamais atteintes.
Que faut-il faire immédiatement pour sécuriser l'accessibilité ?
- Auditer le fichier robots.txt : pas de Disallow bloquant des sections stratégiques
- Vérifier les codes HTTP retournés à Googlebot (pas d'erreurs 5xx intermittentes)
- Tester les temps de réponse serveur : un TTFB > 1s ralentit le crawl et peut provoquer des abandons
- Whitelister les IPs Googlebot dans le pare-feu et les règles CDN (liste officielle publiée par Google)
- Éliminer les redirections en chaîne : maximum 2 sauts entre l'URL d'entrée et la destination finale
- Vérifier que les ressources critiques (CSS, JS nécessaires au rendu) ne sont pas bloquées
- Monitorer les logs serveur pour détecter les erreurs 503 ou 429 spécifiques à Googlebot
- Tester l'accessibilité depuis plusieurs localisations géographiques (pas seulement votre pays)
❓ Questions frequentes
Un site peut-il être partiellement accessible à Googlebot ?
Si Googlebot accède à une page mais ne peut pas rendre le JavaScript, est-elle considérée comme accessible ?
Bloquer Googlebot via User-Agent suffit-il à rendre un site inaccessible ?
Combien de temps faut-il à Google pour détecter qu'un blocage a été levé ?
Les erreurs 503 temporaires comptent-elles comme un blocage d'accessibilité ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/12/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.