Official statement
Other statements from this video 7 ▾
- □ Should you still use rel=next and rel=prev for pagination?
- □ Do you really need to validate your HTML with W3C to get crawled by Google?
- □ Does Google really render all of your JavaScript pages?
- □ Does Google really pay attention to your feedback on its SEO documentation?
- □ Can we really trust Google's official documentation?
- □ Why do your PageSpeed Insights scores fluctuate with each test?
- □ Is it true that Lighthouse scores are calculated transparently?
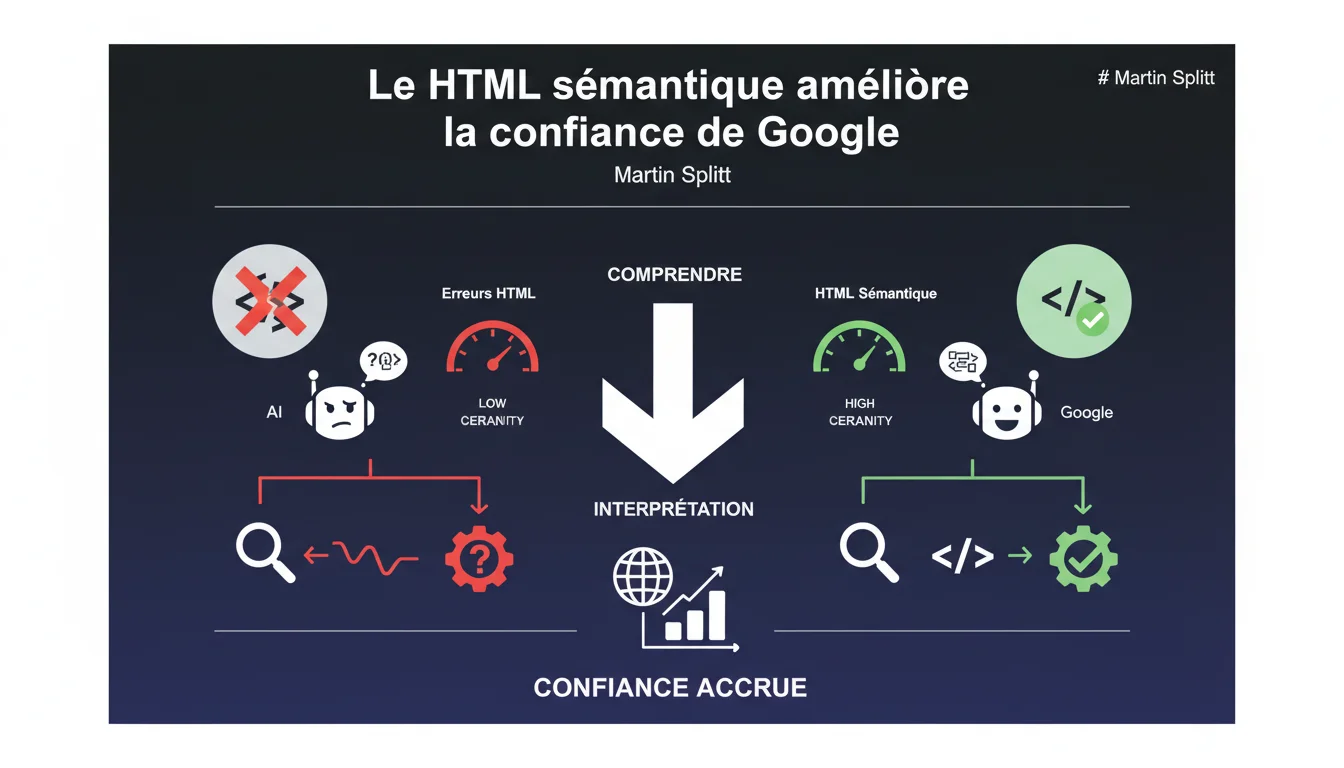
Google can handle imperfect HTML, but correct semantic code increases its certainty in interpreting content. HTML errors reduce algorithmic trust, which can impact indexing and positioning.
What you need to understand
What does this notion of “algorithmic trust” really mean?<\/h3>
When Martin Splitt talks about trust<\/strong>, it’s not a direct ranking factor but a degree of certainty<\/strong> in analyzing content. Google assigns a probability to each HTML element: “Is this H1 really the main title? Does this A clear semantic code — title in a Because the real web is a syntax battlefield. Millions of sites operate with shaky HTML — unclosed tags, malformed attributes, broken structures. Google has developed tolerance mechanisms<\/strong> to parse this mess.<\/p> But tolerating is not rewarding. A site with clean HTML sends a signal: “This site is maintained, the code is consistent, the content is structured.” A site with 200 validation errors rather screams: “No one has touched this code since 2012.”<\/p> The structural tags<\/strong>: On the other hand, overusing <article><\/code> actually contain an article?”<\/p><h1><\/code>, not in a <div class="big-title"><\/code> — reduces ambiguity. Google doesn’t have to guess. This certainty then influences how the engine indexes, extracts, and displays<\/strong> your content in the SERPs.<\/p>Why doesn’t Google just reject incorrect HTML outright?<\/h3>
Which HTML elements really impact this trust the most?<\/h3>
<header><\/code>, <nav><\/code>, <main><\/code>, <article><\/code>, <aside><\/code>, <footer><\/code>. The semantic text tags<\/strong>: <h1><\/code> to <h6><\/code>, <p><\/code>, <blockquote><\/code>, <cite><\/code>. The Schema.org structured data<\/strong>, which is HTML semantic taken to the extreme.<\/p><div><\/code> and <span><\/code> to structure everything dilutes the signal. Google can guess, but with less certainty.<\/p>
SEO Expert opinion
Is this statement consistent with field observations?<\/h3>
Yes, but with an important nuance<\/strong>: the impact of semantic HTML is not binary. We regularly see sites with dreadful HTML rank well — because they have excellent backlinks, ultra-relevant content, and solid domain authority.<\/p> Semantic HTML operates on the margin<\/strong>. It doesn’t save mediocre content, but it optimizes how Google handles good content. In competitive queries, this margin can make the difference between position 3 and position 8.<\/p> Not all. An unclosed Multiple These inconsistencies force Google to interpret<\/strong> instead of read. And any interpretation introduces uncertainty. [To be checked]<\/strong>: Google does not publish any quantitative data on the threshold of HTML errors that significantly degrade trust.<\/p> No. Let’s be honest: many top-performing SEO sites do not pass W3C validation. Some modern frameworks (React, Vue, Next.js) generate technically invalid HTML but perfectly functional.<\/p> The goal is not academic perfection<\/strong>, but semantic consistency<\/strong>. A site with 5 validation errors but a clear structure beats a perfectly valid site but structured with What HTML errors actually degrade this trust?<\/h3>
<br><\/code>? Google doesn’t care. A poorly encoded alt<\/code> attribute? Not critical. But some errors create structural ambiguity<\/strong>:<\/p><h1><\/code> tags on the same page — which one is the real title? Nested <ul><\/code> tags without a parent <li><\/code> — what is the hierarchy? A <main><\/code> that also contains <header><\/code> and <footer><\/code> — where is the main content?<\/p>Should we aim for a 100/100 on the W3C validator?<\/h3>
<div><\/code> everywhere.<\/p>
Practical impact and recommendations
What should you prioritize auditing on an existing site?<\/h3>
Start with the title structure<\/strong>. One Next, the HTML5 structural tags<\/strong>. Does each page have a clear Finally, the critical parsing errors<\/strong>. Run an audit using the W3C validator on some sample pages. Ignore cosmetic warnings. Focus on errors that break the structure: unclosed tags, forbidden nesting, missing required attributes.<\/p> Replace generic Clean up the title hierarchies. If you have 5 H1s on a page, choose the true main title and change the others to H2. If you have gaps (H2 > H4), fill in the holes. Google reads this hierarchy as a document outline<\/strong>.<\/p> Add or complete Schema.org structured data. Article, Product, FAQ, BreadcrumbList — anything that reinforces the semantic signal. Google has explicitly stated that Schema.org enhances content understanding.<\/p> It’s difficult to isolate the pure impact of semantic HTML. But monitor the crawl and indexing metrics<\/strong>: crawl time, number of indexed pages, re-crawl frequency. A better-structured site is often crawled more efficiently.<\/p> Also keep an eye on the featured snippets and rich results<\/strong>. Semantic HTML + Schema.org increases the likelihood of extraction for rich results. If you see an uptick in presence in position 0, that’s a good sign.<\/p><h1><\/code> per page, containing the main title. A logical hierarchy H2 > H3 > H4, without jumps (no H4 directly under an H2). Check with Screaming Frog or Sitebulb.<\/p><main><\/code>? Is the main content in <article><\/code> or <section><\/code> according to context? Is the menu in <nav><\/code>?<\/p>What concrete actions can improve algorithmic trust?<\/h3>
<div><\/code> tags with semantic tags. <div class="header"><\/code> becomes <header><\/code>. <div class="article-content"><\/code> becomes <article><\/code>. It’s simple refactoring, but with a measurable impact<\/strong> on code clarity.<\/p>How can you measure the effect of these optimizations?<\/h3>
<div><\/code> tags with semantic HTML5 tags<\/li><h1><\/code> per page, corresponding to the main title<\/li>
❓ Frequently Asked Questions
Un site avec du HTML invalide peut-il quand même bien ranker ?
Quelle est la différence entre HTML valide et HTML sémantique ?
Les frameworks JavaScript (React, Vue) posent-ils un problème pour le HTML sémantique ?
Faut-il corriger toutes les erreurs remontées par le validateur W3C ?
Le HTML sémantique a-t-il un impact direct sur le ranking ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 13/01/2022
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.