Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Faut-il vraiment valider son HTML W3C pour être crawlé par Google ?
- □ Google rend-il vraiment l'intégralité de vos pages JavaScript ?
- □ Google lit-il vraiment vos retours sur sa documentation SEO ?
- □ Peut-on vraiment faire confiance à la documentation officielle de Google ?
- □ Pourquoi vos scores PageSpeed Insights changent-ils à chaque test ?
- □ Lighthouse calcule-t-il vraiment ses scores de manière transparente ?
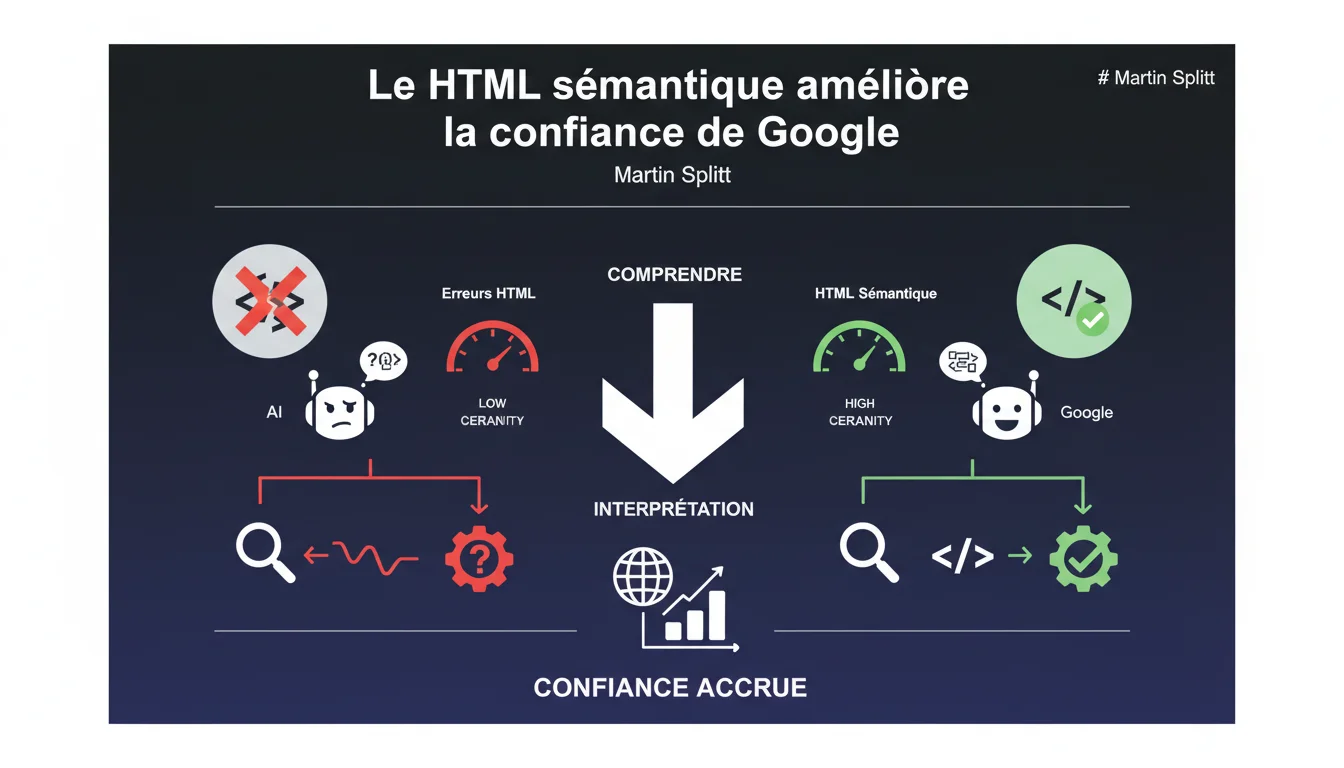
Google peut traiter du HTML imparfait, mais un code sémantique correct augmente sa certitude dans l'interprétation du contenu. Les erreurs HTML réduisent la confiance algorithmique, ce qui peut impacter l'indexation et le positionnement.
Ce qu'il faut comprendre
Que signifie exactement cette notion de « confiance » algorithmique ?
Quand Martin Splitt parle de confiance, il ne s'agit pas d'un facteur de ranking direct mais d'un degré de certitude dans l'analyse du contenu. Google assigne une probabilité à chaque élément HTML : « Cet H1 est-il vraiment le titre principal ? Ce <article> contient-il bien un article ? ».
Un code sémantique clair — titre dans un <h1>, pas dans un <div class="big-title"> — réduit l'ambiguïté. Google n'a pas à deviner. Cette certitude influence ensuite la façon dont le moteur indexe, extrait et affiche votre contenu dans les SERP.
Pourquoi Google ne rejette-t-il pas simplement le HTML incorrect ?
Parce que le web réel est un champ de bataille syntaxique. Des millions de sites fonctionnent avec du HTML bancal — balises non fermées, attributs mal formés, structures foireuses. Google a développé des mécanismes de tolérance pour parser ce bordel.
Mais tolérer n'est pas récompenser. Un site avec du HTML propre envoie un signal : « Ce site est maintenu, le code est cohérent, le contenu est structuré ». Un site avec 200 erreurs de validation crie plutôt : « Personne n'a touché ce code depuis 2012 ».
Concrètement, quels éléments HTML ont le plus d'impact sur cette confiance ?
Les balises structurantes : <header>, <nav>, <main>, <article>, <aside>, <footer>. Les balises sémantiques de texte : <h1> à <h6>, <p>, <blockquote>, <cite>. Les données structurées Schema.org, qui sont du HTML sémantique poussé à l'extrême.
À l'inverse, abuser de <div> et <span> pour tout structurer dilue le signal. Google peut deviner, mais avec moins de certitude.
- HTML sémantique = moins d'ambiguïté dans l'interprétation du contenu
- Code valide = signal de qualité technique et de maintenance
- Balises structurantes HTML5 = meilleure compréhension de l'architecture de la page
- Erreurs HTML = réduction de la confiance algorithmique, pas nécessairement pénalité directe
- Données structurées = amplification du signal sémantique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, mais avec une nuance importante : l'impact du HTML sémantique n'est pas binaire. On observe régulièrement des sites avec un HTML déplorable ranker correctement — parce qu'ils ont d'excellents backlinks, un contenu ultra-pertinent, une autorité de domaine solide.
Le HTML sémantique joue sur la marge. Il ne sauve pas un contenu médiocre, mais il optimise la façon dont Google traite un bon contenu. Sur des requêtes compétitives, cette marge peut faire la différence entre la position 3 et la position 8.
Quelles erreurs HTML dégradent réellement cette confiance ?
Pas toutes. Un <br> non fermé ? Google s'en fout. Un attribut alt mal encodé ? Pas critique. Mais certaines erreurs créent de l'ambiguïté structurelle :
Plusieurs <h1> sur la même page — lequel est le vrai titre ? Des <ul> imbriqués sans <li> parent — quelle est la hiérarchie ? Un <main> qui contient aussi le <header> et le <footer> — où est le contenu principal ?
Ces incohérences forcent Google à interpréter au lieu de lire. Et toute interprétation introduit de l'incertitude. [À vérifier] : Google ne publie aucune donnée quantitative sur le seuil d'erreurs HTML qui dégrade significativement la confiance.
Faut-il viser le 100/100 au validateur W3C ?
Non. Soyons honnêtes : beaucoup de sites top-performants en SEO ne passent pas la validation W3C. Certains frameworks modernes (React, Vue, Next.js) génèrent du HTML techniquement invalide mais parfaitement fonctionnel.
L'objectif n'est pas la perfection académique, mais la cohérence sémantique. Un site avec 5 erreurs de validation mais une structure claire bat un site parfaitement valide mais structuré en <div> partout.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site existant ?
Commence par la structure des titres. Un seul <h1> par page, contenant le titre principal. Une hiérarchie logique H2 > H3 > H4, sans sauts (pas de H4 directement sous un H2). Vérifie avec Screaming Frog ou Sitebulb.
Ensuite, les balises HTML5 structurantes. Est-ce que chaque page a un <main> clair ? Le contenu principal est-il dans <article> ou <section> selon le contexte ? Le menu est-il dans <nav> ?
Enfin, les erreurs critiques de parsing. Lance un audit avec le validateur W3C sur quelques pages types. Ignore les warnings cosmétiques. Focus sur les erreurs qui cassent la structure : balises non fermées, imbrications interdites, attributs requis manquants.
Quelles actions concrètes pour améliorer la confiance algorithmique ?
Remplace les <div> génériques par des balises sémantiques. <div class="header"> devient <header>. <div class="article-content"> devient <article>. C'est du refactoring simple, mais avec un impact mesurable sur la clarté du code.
Nettoie les hiérarchies de titres. Si tu as 5 H1 sur une page, choisis le vrai titre principal et passe les autres en H2. Si tu as des sauts (H2 > H4), comble les trous. Google lit cette hiérarchie comme un plan de document.
Ajoute ou complète les données structurées Schema.org. Article, Product, FAQ, BreadcrumbList — tout ce qui renforce le signal sémantique. Google a explicitement dit que Schema.org améliore la compréhension du contenu.
Comment mesurer l'effet de ces optimisations ?
Difficile d'isoler l'impact pur du HTML sémantique. Mais surveille les métriques de crawl et d'indexation : temps de crawl, nombre de pages indexées, fréquence de re-crawl. Un site mieux structuré est souvent crawlé plus efficacement.
Surveille aussi les featured snippets et rich results. Un HTML sémantique + Schema.org augmente la probabilité d'extraction pour les résultats enrichis. Si tu vois une hausse de présence en position 0, c'est bon signe.
- Auditer la hiérarchie des titres H1-H6 avec Screaming Frog ou Sitebulb
- Remplacer les
<div>génériques par des balises HTML5 sémantiques - Vérifier qu'il n'y a qu'un seul
<h1>par page, correspondant au titre principal - Valider les pages types avec le validateur W3C et corriger les erreurs structurelles critiques
- Implémenter ou compléter les données structurées Schema.org pertinentes
- Surveiller les métriques de crawl et d'indexation dans Search Console
- Monitorer l'évolution des rich results et featured snippets
❓ Questions frequentes
Un site avec du HTML invalide peut-il quand même bien ranker ?
Quelle est la différence entre HTML valide et HTML sémantique ?
Les frameworks JavaScript (React, Vue) posent-ils un problème pour le HTML sémantique ?
Faut-il corriger toutes les erreurs remontées par le validateur W3C ?
Le HTML sémantique a-t-il un impact direct sur le ranking ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.