Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Google rend-il vraiment l'intégralité de vos pages JavaScript ?
- □ Le HTML sémantique renforce-t-il vraiment la confiance de Google dans votre contenu ?
- □ Google lit-il vraiment vos retours sur sa documentation SEO ?
- □ Peut-on vraiment faire confiance à la documentation officielle de Google ?
- □ Pourquoi vos scores PageSpeed Insights changent-ils à chaque test ?
- □ Lighthouse calcule-t-il vraiment ses scores de manière transparente ?
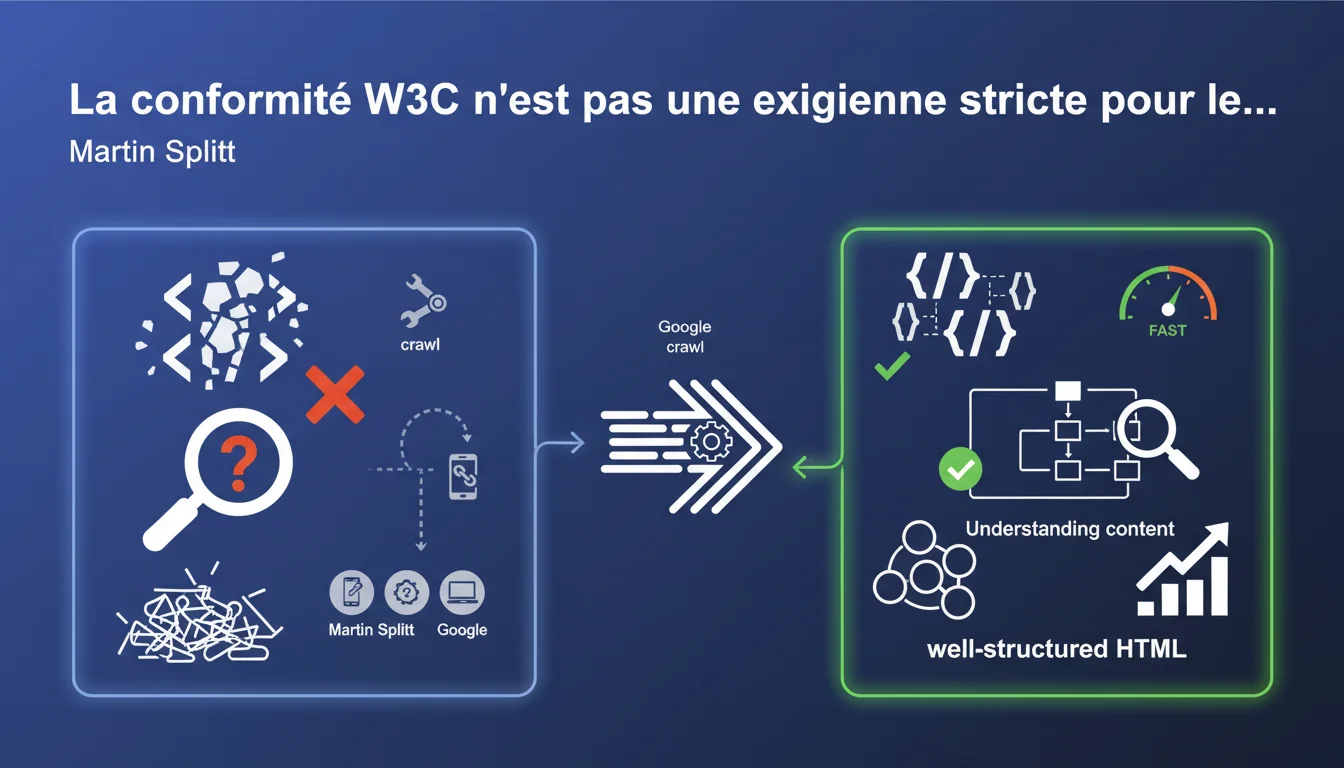
Google ne requiert pas une validation W3C stricte pour crawler et comprendre vos pages. Le moteur tolère les erreurs HTML et tente d'interpréter le contenu même si le code n'est pas parfait, mais un balisage propre et sémantique reste un avantage pour faciliter l'analyse.
Ce qu'il faut comprendre
Pourquoi Google se moque-t-il de la validation W3C parfaite ?
Google conçoit son crawler pour affronter le web réel, pas un web théorique. La majorité des sites contiennent des erreurs HTML — balises non fermées, attributs mal orthographiés, structures imbriquées incorrectement. Si Googlebot exigeait une conformité W3C stricte, il rejetterait une part massive du web indexable.
Le crawler utilise des mécanismes de tolérance aux erreurs similaires aux navigateurs modernes. Il reconstruit l'arborescence DOM même quand le HTML est bancal, en appliquant des règles d'inférence et de correction automatique. L'objectif : extraire du sens, pas sanctionner du code imparfait.
Qu'est-ce qu'un HTML « bien structuré » selon Google ?
Splitt mentionne un HTML sémantique et bien structuré sans définir précisément ce seuil. Concrètement, cela signifie : balises appropriées pour le contenu (titres H1-H6, listes, paragraphes), usage correct des attributs standards, absence d'erreurs bloquant le parsing.
La différence avec la validation W3C complète ? Google tolère les erreurs mineures (attributs obsolètes, ordre des balises légèrement incorrect) tant que la structure logique reste cohérente. Un site peut échouer au validateur W3C tout en étant parfaitement interprété par Googlebot.
Quelles sont les erreurs HTML qui posent vraiment problème ?
Certaines erreurs dégradent l'interprétation au point d'affecter la compréhension. Balises fermées au mauvais endroit, imbrications cassant la hiérarchie des contenus, ou balises JavaScript mal échappées provoquent des DOM fragmentés.
Google tente de corriger, mais le résultat n'est pas garanti. Si le crawler doit deviner où commence un paragraphe ou quel élément contient le titre principal, le risque d'erreur d'interprétation augmente — et avec lui, celui d'une indexation imparfaite.
- Validation W3C stricte non obligatoire pour le crawl Google
- HTML sémantique cohérent facilite la compréhension du contenu
- Erreurs mineures tolérées, erreurs structurelles critiques risquent de perturber l'indexation
- Googlebot applique des corrections automatiques similaires aux navigateurs
- Distinction clé : conformité W3C ≠ interprétabilité par Google
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, largement. Des centaines de tests terrain confirment que Google indexe et classe des sites avec des erreurs de validation W3C. Sites e-commerce avec 200+ erreurs au validateur continuent de performer en SEO si la structure globale reste lisible.
On observe que Google privilégie la cohérence sémantique sur la conformité technique absolue. Un site avec quelques erreurs W3C mais une hiérarchie de contenu claire surpasse un site techniquement valide mais mal structuré au niveau sémantique.
Quelles nuances faut-il apporter à cette affirmation ?
Splitt évacue le sujet en déclarant que Google « tente de donner du sens », sans préciser le seuil de tolérance ni les types d'erreurs critiques. Cette formulation vague laisse le praticien dans le flou. [A vérifier] : jusqu'où Google tolère-t-il réellement ?
Sur le terrain, certains types d'erreurs provoquent des effets mesurables. JavaScript mal fermé peut bloquer le rendu côté client et affecter l'indexation dynamique. Des balises Schema.org mal fermées cassent le Rich Snippet. Google « tente » de corriger, mais n'y parvient pas toujours.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Certains contextes exigent un code plus strict. AMP et Web Stories imposent des validations strictes — une erreur bloque l'éligibilité. Les Rich Snippets reposent sur un balisage Schema.org précis : une faute de syntaxe JSON-LD empêche l'affichage des résultats enrichis.
Le rendu JavaScript complexifie l'équation. Si le HTML initial est cassé et que l'hydratation JavaScript échoue, Google peut ne voir qu'un contenu partiel ou vide. La tolérance aux erreurs fonctionne mieux sur du HTML statique classique.
Impact pratique et recommandations
Que faut-il faire concrètement avec la validation W3C ?
Inutile de viser la perfection W3C à 100%. Concentrez-vous sur les erreurs structurelles qui cassent la lisibilité : balises non fermées dans les sections critiques (header, main, article), imbrications incorrectes de listes ou de tableaux, attributs manquants sur les images (alt).
Utilisez le validateur W3C comme outil de diagnostic, pas comme juge absolu. Si une erreur signalée concerne un attribut obsolète mais sans impact (ex : border sur une image), ignorez-la. Si elle touche la structure DOM ou les balises sémantiques, corrigez.
Quelles erreurs HTML méritent vraiment d'être corrigées ?
Priorisez les erreurs affectant la hiérarchie de contenu : multiples H1, sauts de niveaux de titres (H2 → H5), balises de paragraphe fermées au mauvais endroit. Ces erreurs perturbent l'extraction des signaux de pertinence par Google.
Corrigez systématiquement les erreurs sur les données structurées (JSON-LD, Microdata) et les balises critiques pour l'indexation (canonical, hreflang, meta robots). Ici, la tolérance de Google est nulle — une faute syntaxique désactive la directive.
- Passer le site au validateur W3C pour identifier les erreurs structurelles majeures
- Corriger en priorité les erreurs sur titres H1-H6, balises sémantiques (article, section, nav)
- Vérifier la fermeture correcte des balises dans les zones de contenu principal
- Tester le rendu dans plusieurs navigateurs pour détecter les problèmes d'interprétation
- Valider strictement le balisage Schema.org et JSON-LD avec l'outil Google
- Ignorer les avertissements W3C sur attributs obsolètes sans impact réel
- Surveiller les rapports Search Console pour détecter des erreurs d'indexation liées au HTML
La validation W3C complète n'est pas un prérequis pour le SEO Google, mais un HTML propre et sémantiquement cohérent reste un avantage concurrentiel. Concentrez-vous sur la structure logique du contenu plutôt que sur la conformité technique absolue.
Ces optimisations techniques exigent souvent une analyse approfondie de l'architecture du site et une expertise poussée pour distinguer les erreurs critiques du bruit. Si votre équipe manque de temps ou de ressources pour auditer et corriger la qualité du code, un accompagnement par une agence SEO spécialisée peut s'avérer pertinent pour établir une stratégie d'amélioration ciblée et mesurer l'impact réel sur vos performances organiques.
❓ Questions frequentes
Google pénalise-t-il un site qui échoue à la validation W3C ?
Un HTML valide W3C améliore-t-il mon positionnement SEO ?
Quelles erreurs HTML bloquent réellement l'indexation Google ?
Dois-je corriger toutes les erreurs remontées par le validateur W3C ?
Le balisage Schema.org doit-il être strictement valide pour fonctionner ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.