Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:02 Pourquoi intégrer Page Experience dans votre stratégie SEO desktop ?
- 2:08 Comment le rapport Page Experience pour desktop influence-t-il le SEO ?
- 4:03 Comment les clics sur 'Autres questions posées' influencent-ils vos stats SEO?
- 7:54 Faut-il s'inquiéter des variations d'URL pour le référencement ?
- 18:45 Pourquoi les rapports de couverture de Search Console sont-ils parfois à la traîne ?
- 20:08 Faut-il obligatoirement mentionner les sources externes pour AggregateRating ?
- 25:45 Pourquoi la relation entre sites d'un même groupe ne garantit-elle pas les avis SEO ?
- 27:47 Comment Google utilise-t-il réellement vos rapports de spam ?
- 32:29 Comment Google utilise-t-il réellement les Spam Reports pour améliorer ses algorithmes ?
- 35:52 Pourquoi privilégier robots.txt pour bloquer le crawl ?
- 39:18 Pourquoi miser sur le canonical plutôt que de bloquer le crawl ?
- 42:07 Pourquoi privilégier le DMCA pour le contenu copié plutôt que Search Console ?
- 44:00 Pourquoi les demandes DMCA pourraient-elles impacter votre strategie SEO ?
- 46:06 Pourquoi Google limite-t-il les demandes DMCA à 1000 URLs ?
- 48:41 Pourquoi optimisons-nous encore pour Google au lieu des lecteurs ?
- 54:27 Les campagnes de commentaires clients sont-elles devenues un piège à pénalité Google ?
- 56:02 Pourquoi l'attribut UGC est-il crucial pour vos liens de commentaires de blog ?
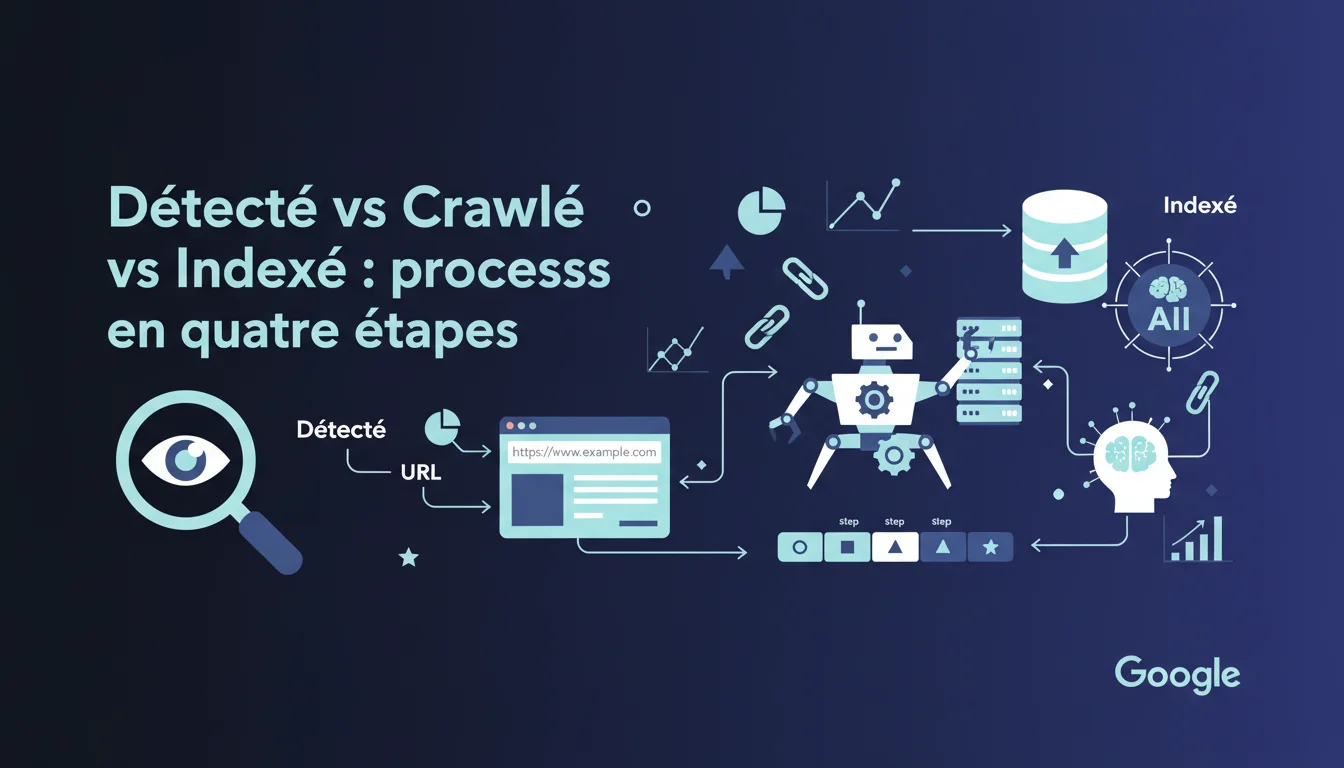
Indexation en quatre étapes : découverte, crawl, indexation, affichage. 'Détecté - non indexé' et 'Crawlé - non indexé' illustrent des phases critiques où l'URL n'avance pas dans le processus. Maîtriser ces étapes est crucial pour tout SEO.
Ce qu'il faut comprendre
Quelle est la différence entre détecté et crawlé ?
'Détecté' signifie que l'URL est identifiée par Google mais pas encore explorée. 'Crawlé' indique que le contenu de l'URL a été récupéré.
- Détection : Premiers pas de l'URL vers la visibilité.
- Crawl : Récupération du contenu, indispensable pour avancer vers l'indexation.
Pourquoi certaines URL ne parviennent pas à l'indexation ?
Plusieurs raisons peuvent expliquer cela : contenu peu qualitatif, erreurs techniques ou restrictions dans le fichier robots.txt. L'identification du problème est clé.
Rappel : Tout contenu crawlé n'est pas automatiquement indexé.
- Vérifiez les erreurs via Google Search Console.
- Assurez-vous que le contenu mérite l'indexation.
Avis d'un expert SEO
La déclaration est-elle réaliste avec les pratiques observées ?
Souvent, l'écart entre la théorie et la pratique se révèle. Beaucoup de professionnels rapportent que certaines URL restent ancrées en 'crawlé - non indexé' sans explication évidente. [A vérifier]
Google est-il transparent sur ces étapes ?
Pas toujours. Si l'ordre général des opérations est clair, la réalité terrain montre des nuances. Parfois, un excellent contenu stagne.
Impact pratique et recommandations
Que faut-il faire concrètement pour améliorer l'indexation ?
Optimisez les étapes pré-crawl. Assurez-vous que les URL sont facilement accessibles et que les fichiers robots.txt ne bloquent pas le crawl.
- Revoyez les sitemaps XML régulièrement.
- Gérez le budget crawl.
- Analysez les logs serveurs pour détecter les anomalies.
Quelles erreurs éviter pour ne pas stagner ?
Évitez le contenu dupliqué. Assurez-vous d'un maillage interne solide qui facilite le travail des robots.
Comment vérifier que mon site reste bien indexé ?
Utilisez Google Search Console. Suivez les alertes et problèmes signalés. Ajustez vos stratégies selon les retours concrets.
❓ Questions frequentes
Qu'est-ce que signifie 'Détecté - non indexé' ?
Pourquoi certaines URL restent-elles 'Crawlé - non indexé' ?
Comment améliorer la découverte de mes URL ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · durée 1h01 · publiée le 27/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.