Official statement
Other statements from this video 11 ▾
- □ Do Core Web Vitals Really Impact Your Content's Search Rankings?
- □ Is mobile-friendliness really no longer a Google ranking factor?
- □ Is Google really switching from FID to INP in Core Web Vitals — and should you worry?
- □ Are Core Web Vitals Really Not Enough to Guarantee a Good User Experience?
- □ Is Google's Search Generative Experience (SGE) about to completely transform how organic traffic works?
- □ Does the Rich Results Test code editor really transform how you validate structured data?
- □ Does Search Console Insights really work without Google Analytics? A game-changer for site owners?
- □ Does Google's improved video indexing report finally reveal the real blocking issues?
- □ Should you really stop using the ping endpoint to submit your sitemaps?
- □ Is Google's new spam report really a game-changer for SEOs?
- □ Should you rethink your domain strategy now that .ai has become a generic ccTLD?
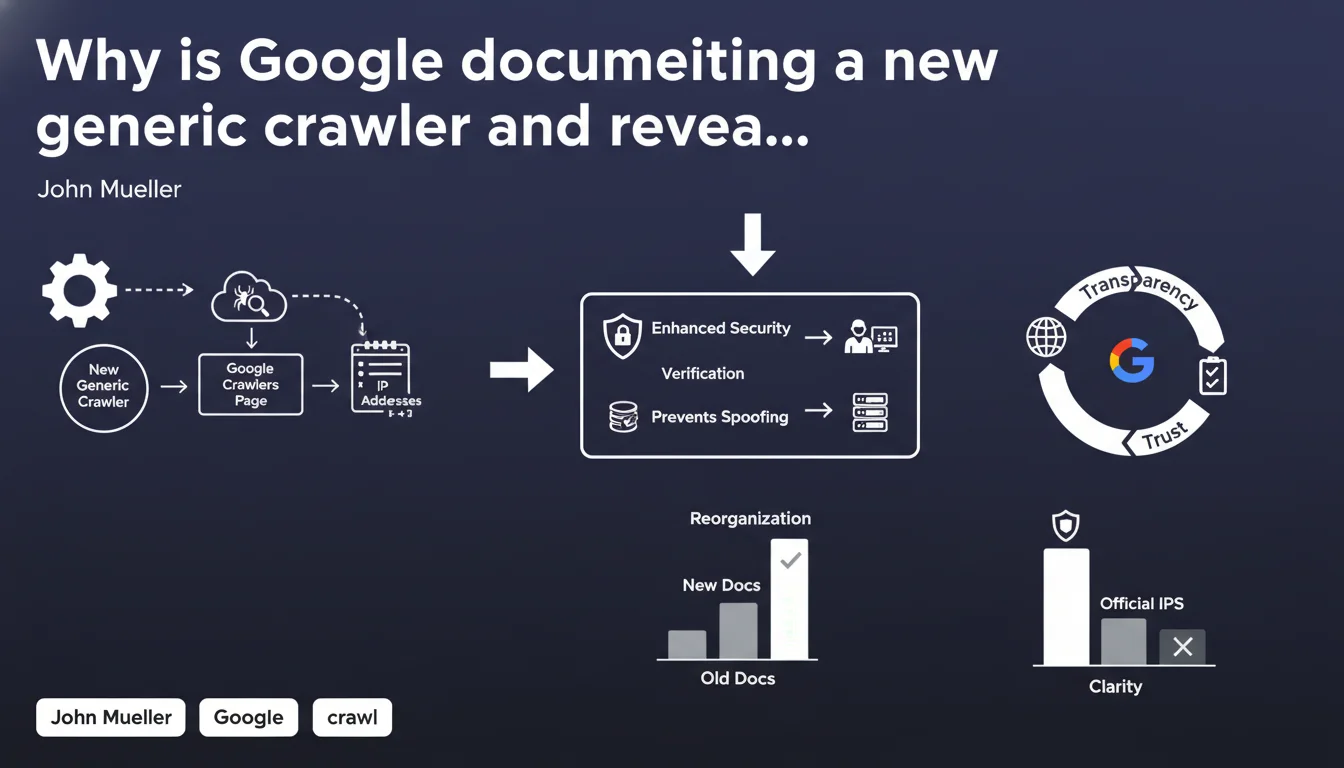
Google has officially documented the existence of a new generic crawler in its documentation, reorganized the complete list of its crawling robots, and published the IP address ranges used by these crawlers. This increased transparency allows SEO professionals to better identify legitimate Google traffic and refine their crawl budget management strategies.
What you need to understand
What is this new generic crawler and what does it do?
Google has added to its official documentation a new generic crawler whose existence was not formally documented until now. This robot complements the already complex ecosystem of Google crawlers — Googlebot for classic web, Googlebot for mobile, Google-InspectionTool, and others.
The exact function of this generic crawler remains unclear in Google's communication. It could serve specific exploration tasks not covered by other bots, or internal testing purposes. What really matters? Its official documentation is a game-changer for server log analysis.
Why is Google publishing its IP addresses now?
Until now, identifying Google traffic with certainty required reverse DNS verification — a technical process that wasn't always reliable. By publishing the official IP ranges of its crawlers, Google enables more direct and secure identification.
This transparency responds to a long-standing demand from SEO professionals and technical teams. It simplifies firewall rule configuration, log analysis, and detection of potential crawlers impersonating Googlebot.
What has changed in the crawler documentation?
The reference page on Google crawlers has been restructured and clarified. The different robots are now better categorized, with more precise descriptions of their respective functions.
This reorganization makes the documentation more accessible, but it doesn't change the technical functioning of the crawlers themselves. It's primarily an improvement in documentary transparency.
- New generic crawler documented — exact function still unclear
- Publication of official IP ranges for all Google crawlers
- Reorganization of documentation for greater clarity
- Better identification of legitimate Google traffic in server logs
- Simplified firewall configurations and security rules
SEO Expert opinion
Does this transparency really change the game for SEOs?
Yes and no. Publishing the IPs is a real step forward — it simplifies log analysis and reduces the risk of accidentally blocking Googlebot. But in practice, SEO professionals who were already serious about crawl budget were already using reverse DNS verification methods.
The new generic crawler, on the other hand, raises more questions than it answers. Google remains deliberately vague about its exact usage. [To be verified]: we don't know if this crawler impacts crawl budget the same way as classic Googlebot, nor whether it respects the same robots.txt rules.
Should we expect changes in observed crawl patterns?
In practice, professionals analyzing their logs daily haven't necessarily noticed major disruptions linked to this generic crawler. Either it's been operating for a while without being formally identified, or its activity volume remains marginal.
What's certain: Google is multiplying specialized robots (Mobile-Friendly Test, AdsBot, Google-InspectionTool...), and this fragmentation complicates overall crawl behavior analysis. Having clear documentation is good — but it doesn't compensate for the lack of quantified data on budget allocation between these different crawlers.
Is this announcement hiding other undocumented changes?
Google rarely communicates about its crawlers without reason. This formal documentation of a "generic" crawler could indicate internal rationalization of crawl infrastructure — or conversely, increased specialization of exploration tasks.
What's critically missing? Clear guidelines on how to optimize for each of these crawlers. Saying "here's our new robot" without explaining what it indexes, how it prioritizes, or how it consumes crawl budget is providing incomplete information.
Practical impact and recommendations
What should you actually do with these IP addresses?
First step: integrate these IP ranges into your log analysis tools. This will allow you to precisely isolate Google traffic and measure its evolution over time, crawler by crawler.
Second action: if you manage firewall rules or rate limiting, ensure these IPs are never accidentally blocked. Even temporary blocking can have disastrous consequences for your indexation.
How should you adapt your crawl budget strategy?
With multiple Google crawlers active on your site, crawl budget analysis becomes more complex. You now need to segment logs by robot type to understand where Google is really investing its resources.
Watch this new generic crawler especially: if it consumes a significant portion of your budget without clear indexation value, you may want to investigate. But be careful — blocking an undocumented Google crawler can be risky.
What mistakes should you avoid at all costs?
Don't rush to block this new crawler on the pretext that it consumes resources. Without understanding its exact role, you could compromise your visibility on certain search segments.
Another pitfall: relying solely on IPs to identify Googlebot. These lists change — Google can add new ranges without prior communication. Always maintain a reverse DNS verification as a complement.
- Update your log analysis tools with the new Google IP ranges
- Verify that your firewall rules exclude no official Googlebot IPs
- Segment your crawl reports by robot type (classic Googlebot, mobile, generic, etc.)
- Monitor the new generic crawler's activity in your logs without blocking it
- Document the crawl patterns observed for each robot type
- Maintain regular monitoring of Google documentation to detect new IP additions
- Combine IP verification and reverse DNS for reliable identification
❓ Frequently Asked Questions
Dois-je bloquer le nouveau crawler générique de Google dans mon robots.txt ?
Comment vérifier que les IP qui crawlent mon site sont bien celles de Google ?
Ce nouveau crawler consomme-t-il du crawl budget comme Googlebot classique ?
Faut-il modifier mes sitemaps ou ma structure pour ce nouveau crawler ?
Où trouver la liste officielle des adresses IP de Google ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 05/07/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.