Official statement
Other statements from this video 14 ▾
- □ Robots.txt vs no-index : pourquoi tant de pros SEO mélangent encore ces deux mécanismes ?
- □ Faut-il vraiment optimiser tout le site après une mise à jour algorithmique ?
- □ Search Console intègre les données IA : mais savez-vous vraiment ce que vous mesurez ?
- □ Faut-il vraiment optimiser différemment son site pour les AI Overviews de Google ?
- □ Google Trends est-il vraiment un outil stratégique pour orienter sa ligne éditoriale SEO ?
- □ Comment Search Console peut-il vraiment révéler ce que cherche votre audience ?
- □ Le SEO est-il vraiment mort ou juste en train de muter sous nos yeux ?
- □ Comment la qualité du contenu influence-t-elle directement le taux d'indexation par Google ?
- □ Un sitemap suffit-il vraiment à garantir l'indexation de vos pages ?
- □ Votre CDN ou firewall bloque-t-il Googlebot sans que vous le sachiez ?
- □ L'index Google a-t-il vraiment une limite de capacité ?
- □ Le marketing traditionnel est-il devenu indispensable pour ranker sur Google ?
- □ Les données structurées sont-elles vraiment inutiles pour le classement SEO ?
- □ Faut-il vraiment faire vérifier toutes vos traductions automatiques pour le SEO ?
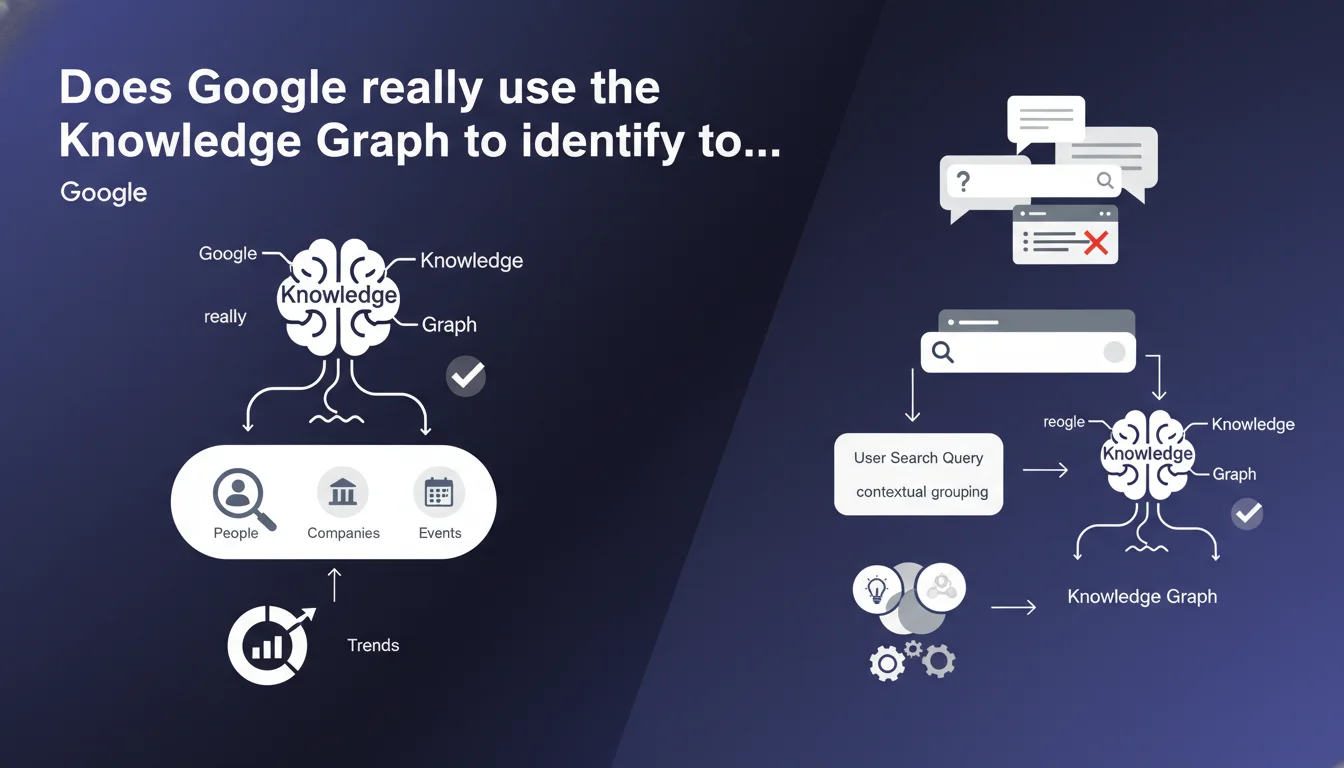
Google confirms that Google Trends topics are directly extracted from the Knowledge Graph, not from simple keyword clustering. The algorithm associates search queries with entities based on the actual search context, not just semantic proximity. This revelation changes how you should interpret trend data for SEO.
What you need to understand
What's the real difference between a topic and a simple search query in Google Trends?
A topic in Google Trends is not an aggregation of keyword variants. It's a Knowledge Graph entity — a structured representation of a real-world concept with its attributes, relationships, and context.
When you select "iPhone (topic)" rather than "iPhone (search term)", you're accessing data from all searches that Google understood as referring to the iPhone entity, regardless of exact wording. This includes "new Apple phone", "iOS smartphone", or even queries without the word iPhone if the context is clear.
How does Google actually link a search query to a specific topic?
Google relies on contextual understanding of user searches, not syntactic matching. If someone searches "French president" after viewing pages about Emmanuel Macron, that search can be attributed to the "Emmanuel Macron" topic.
This attribution is based on analyzing search behavior, visited pages, browsing history, and contextual signals available at the moment of the query. It's probabilistic attribution, not deterministic.
Why does this revelation change how we read Google Trends?
Because the volumes you see for a topic reflect the reality of search intent, not just keyword popularity. A topic can show stable volume while the exact terms vary significantly.
For an SEO, this means optimizing solely for keyword variations without understanding the underlying entity is like missing entire segments of potential traffic. Google already groups these queries conceptually — your content should do the same.
- Trends topics are Knowledge Graph entities, not keyword aggregations
- Query-topic association relies on search context, not syntax
- A single topic can encompass hundreds of different phrasings
- Topic data reflects genuine interest in a concept, independent of the vocabulary used
- This logic also applies to search rankings — Google understands entities, not just words
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Absolutely, and it explains behaviors we've been observing for years. How many times have you seen a page rank for queries that contain no exact words present in the content? That's exactly this entity mechanism at work.
Sites performing well today aren't those that cram keywords, but those that exhaustively cover an entity with its attributes, relationships, and sub-topics. The Knowledge Graph isn't just an internal Google tool — it's the conceptual framework that structures the entire search engine.
What are the implications for traditional keyword research?
Traditional keyword research — volume plus difficulty plus intent — becomes partially obsolete if it ignores the entity dimension. You can identify a high-volume keyword, but if you don't understand which entity Google associates with that term, you risk creating off-topic content.
Take "battery". Is this the "car battery" entity, "kitchen battery" entity, or "drum battery" entity? Google Trends with topics gives you the answer — and more importantly, shows that Google already differentiates these entities in its indexing. Your content strategy should reflect this granularity.
Where does this entity logic show its limits?
With emerging queries or ultra-specialized niches where the Knowledge Graph doesn't yet have a structured entity. In these cases, Google temporarily reverts to more traditional matching based on semantic proximity and behavioral signals.
Another limitation: ambiguous or multi-faceted entities. "Apple" can refer to the brand or the fruit — and even though the Knowledge Graph differentiates them, some queries remain inherently ambiguous until contextual signals enable disambiguation. In these gray areas, topic-query association is less reliable.
Practical impact and recommendations
How do you adapt your content strategy to this entity logic?
First step: identify the main entities in your sector within the Knowledge Graph. Use Google Trends in topic mode, Schema.org, and entity analysis tools to map the conceptual territory you want to cover.
Next, structure your content to exhaustively cover these entities — not just mention keywords, but address attributes, relationships, connected sub-entities. If you're working on the "technical SEO" entity, your content should cover crawl budget, JavaScript rendering, Core Web Vitals, structured data, etc.
Use Schema.org markup to make these entities explicit to Google. It's the direct bridge between your content and the Knowledge Graph. A well-marked page helps Google understand which entity you're addressing, even if vocabulary varies.
What mistakes should you avoid when analyzing Google Trends?
Mistake number one: comparing search terms rather than topics. You'll see variations that simply reflect vocabulary shifts, not real changes in interest.
Second pitfall: ignoring entity granularity. "Digital marketing" is a very broad topic; if you really want to understand trends, you need to drill down to sub-entities: SEO, SEM, social media marketing, etc.
Third mistake: failing to cross-reference Trends data with other sources. The Knowledge Graph evolves, query-topic associations too. Cross-validation with Search Console, Google suggestions, and NLP tools is essential.
What concrete actions should you take right now?
- Audit your main pages to identify the Knowledge Graph entities they target (explicitly or implicitly)
- Compare your target keywords with corresponding topics in Google Trends — are there gaps between what you're optimizing and what Google understands?
- Enrich your content to cover the attributes and relationships of main entities, not just exact terms
- Implement or strengthen your Schema.org markup to clarify which entities you're addressing
- Reanalyze your Google Trends data in topic mode, not search term mode, for a realistic view of trends
- Map connected entities and sub-entities to identify untapped content opportunities
- Train your editorial teams to think "entities" rather than "keywords" when creating content
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 18/12/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.