Official statement
Other statements from this video 9 ▾
- □ Pourquoi Google ignore-t-il vos balises meta placées dans le <body> ?
- □ Pourquoi Google refuse-t-il les balises canonical placées dans le <body> ?
- □ Les balises hreflang dans le <body> sont-elles vraiment ignorées par Google ?
- □ Le code HTML valide W3C améliore-t-il vraiment le référencement ?
- □ Faut-il optimiser les hints de préchargement pour Googlebot ?
- □ Le markup sémantique HTML5 est-il vraiment inutile pour le SEO ?
- □ La performance web améliore-t-elle vraiment votre référencement naturel ?
- □ Google parse-t-il vraiment le HTML comme un navigateur ?
- □ Pourquoi Googlebot ignore-t-il vos hints de préchargement des ressources ?
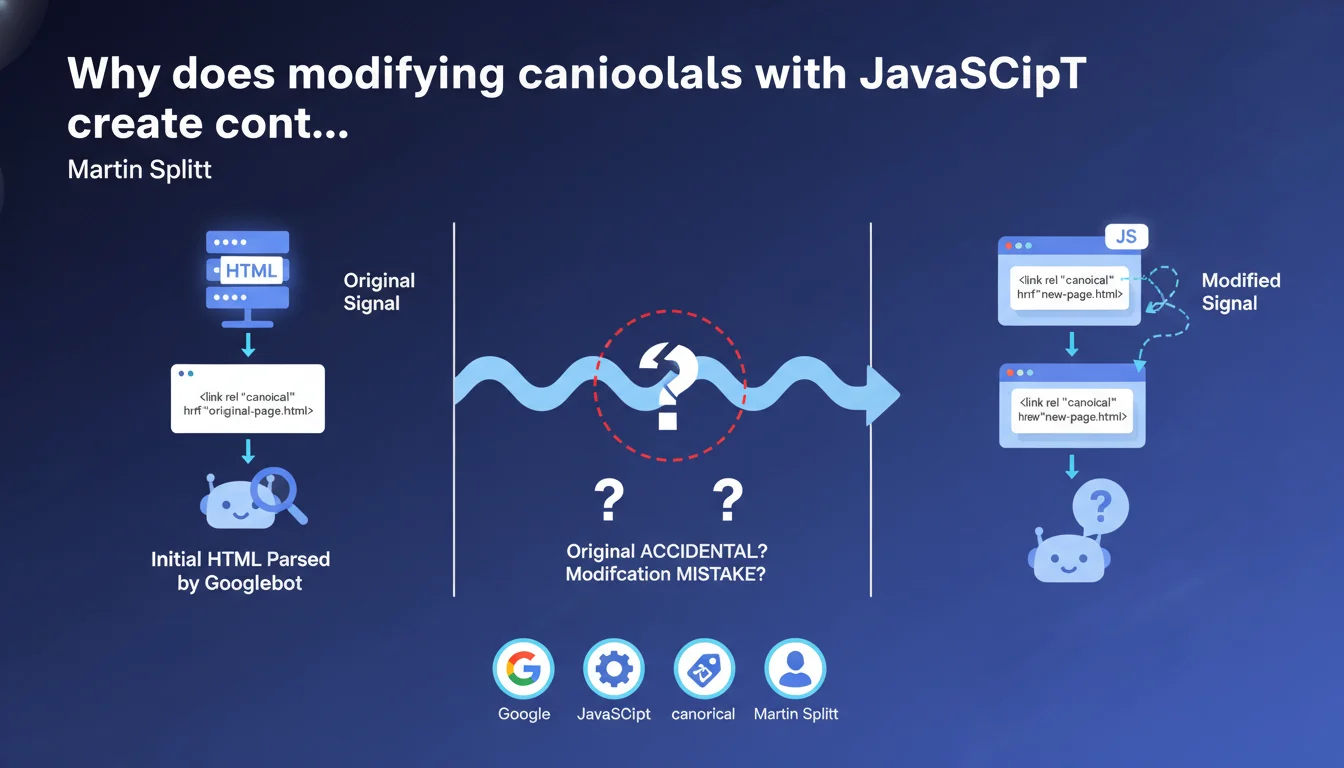
Google formally discourages modifying canonical tags via JavaScript after initial HTML loading. This practice generates contradictory signals that algorithms struggle to interpret: it becomes impossible to determine whether the original URL was an error or if the JS modification is accidental. Result: risk of unpredictable indexation.
What you need to understand
Why does Google talk about "mixed signals"?
When a page loads with a canonical tag in the initial HTML, then a script modifies this tag after rendering, Google receives two different instructions. The first signal comes from the server (raw HTML), the second from the client (after JavaScript execution).
Concretely, if your initial HTML points to example.com/page-a but JavaScript replaces it with example.com/page-b, Google doesn't know which version to respect. The algorithm must guess: was this a server-side error corrected by JS, or a bug in the script that overwrites a correct canonical?
What are the concrete risks of this ambiguity?
The main danger: random indexation. Google may choose one URL or the other — or worse, ignore both signals and decide for itself which page to canonicalize. In some cases, the page may even be completely excluded if the signals are deemed too contradictory.
This uncertainty particularly affects JavaScript-heavy sites (React, Vue, Angular) where meta tags are often injected after the fact. Without Server-Side Rendering (SSR) or pre-rendering, you create this problematic scenario by default.
Why doesn't Google systematically choose the JavaScript version?
Because Google doesn't execute instantly the JavaScript of all crawled pages. JS rendering often happens in a secondary queue, meaning the initial HTML is analyzed first. If it already contains metadata, it's taken into account immediately.
When the engine later executes the JS and discovers different values, it faces a temporal contradiction. Martin Splitt emphasizes that this situation prevents understanding the real intention of the webmaster — hence the recommendation for absolute consistency.
- The initial HTML and JavaScript signals must be identical to avoid any confusion
- Google cannot guess whether a JS modification is a fix or an error
- The main risk: unpredictable indexation or page exclusion
- SPA sites without SSR are particularly vulnerable to this problem
- Metadata consistency must be guaranteed before client-side rendering
SEO Expert opinion
Does this statement really reflect the behavior observed in the field?
Yes, and it's even an understatement. In audits I conduct, poorly configured SPA sites show erratic indexation rates precisely for this reason. Google Search Console displays canonicalized URLs differently from what the developer thought they had defined.
The problem particularly affects e-commerce platforms with product variants: a script may want to adjust the canonical based on the selected filter, but if the initial HTML already points elsewhere, it's a lottery. I've seen cases where Google completely ignored both signals and invented its own canonical URL.
Should all JavaScript be banned from critical metadata?
Let's be honest: the ideal would indeed be to manage everything server-side. SSR, pre-rendering, or static generation ensure that the initial HTML already contains the correct tags. But this isn't always technically or economically feasible.
If you absolutely must use JavaScript for metadata, make sure the initial HTML contains no contradictory default values. Leave the tag empty or absent rather than putting a placeholder that will be overwritten. It limits the damage — even if it's not the optimal solution.
In which cases can you still modify metadata with JavaScript?
Non-critical metadata for indexation is less risky. For example, modifying an Open Graph title for social display, or dynamically adjusting structured data like BreadcrumbList. Google tolerates better adjustments that don't directly touch the canonical signal or indexable content.
But for canonical, robots meta, hreflang — everything that directly drives indexation decisions — Martin Splitt's rule is unforgiving: consistency between HTML and JS, or nothing. [To verify]: Google has never published an exhaustive list of sensitive vs. tolerant tags for JS modifications, so maximum caution remains the best approach.
Practical impact and recommendations
What should you do immediately if your site modifies canonicals with JavaScript?
First step: audit the raw HTML sent by the server. Use curl or the browser's "View Source" tool (not the inspector, which shows the DOM after JS). Compare it with what you see in the inspector after full page load.
If the values differ, you have a problem. Move to SSR, pre-rendering (Prerender.io, Rendertron), or static generation (Next.js, Nuxt). The goal: the initial HTML should already be correct, regardless of JavaScript.
How do you verify that Google sees the intended version?
Use the URL inspection tool in Search Console. Look at the render "as Google sees it" and verify that the canonical, robots, hreflang tags match your expectations. If they don't, the initial HTML signal is winning or Google is ignoring both.
Also test with Google's Mobile-Friendly Test, which shows the rendered HTML. If you still see inconsistencies, it means your JavaScript fix wasn't taken into account — or worse, that it's creating the confusion Splitt describes.
What technical mistakes should you absolutely avoid?
Never put a "placeholder" canonical tag in the initial HTML that JavaScript will overwrite later. If the canonical must be dynamic, either generate it server-side, or inject it only via JS without pre-existing value. Two signals are better than one contradictory signal.
Also avoid poorly configured frameworks that inject self-referential canonicals by default then modify them according to client-side navigation. It's a classic SPA trap: each internal navigation can create a new signal conflict.
- Systematically compare raw HTML (curl) and DOM after JS
- Prioritize SSR, pre-rendering or static generation for critical metadata
- If JS is mandatory: don't insert a contradictory default value in the HTML
- Verify actual indexation via Search Console (URL inspection)
- Test with Mobile-Friendly Test to see what Googlebot receives
- Ban "placeholder" canonicals overwritten by scripts
- Audit SPA frameworks to disable auto-generated canonicals
❓ Frequently Asked Questions
Peut-on modifier d'autres métadonnées en JavaScript sans risque ?
Le pré-rendu suffit-il à résoudre ce problème ?
Que se passe-t-il si Google détecte deux canonicals contradictoires ?
Les sites React ou Vue sont-ils tous concernés ?
Comment savoir si mon site est affecté ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 26/02/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.