Official statement
Other statements from this video 11 ▾
- □ Google rend-il vraiment toutes les pages HTML indexables sans exception ?
- □ Googlebot suit-il vraiment Chrome en temps réel ?
- □ Les redirections JavaScript sont-elles vraiment traitées comme des redirections serveur par Google ?
- □ Pourquoi le rendu Google ne sera jamais vraiment celui d'un navigateur standard ?
- □ Faut-il vraiment débloquer toutes vos ressources dans robots.txt pour éviter les problèmes d'indexation ?
- □ Google conserve-t-il vraiment les cookies entre chaque rendu de page ?
- □ Pourquoi Google ignore-t-il les bannières de consentement des cookies lors du crawl ?
- □ Faut-il abandonner le dynamic rendering basé sur le user-agent de Googlebot ?
- □ Pourquoi la gestion d'erreurs JavaScript conditionne-t-elle désormais votre capacité à être indexé par Google ?
- □ L'outil d'inspection d'URL est-il vraiment fiable pour tester le rendu par Googlebot ?
- □ Pourquoi Google rend-il toutes les pages HTML même celles qui n'ont pas besoin de JavaScript ?
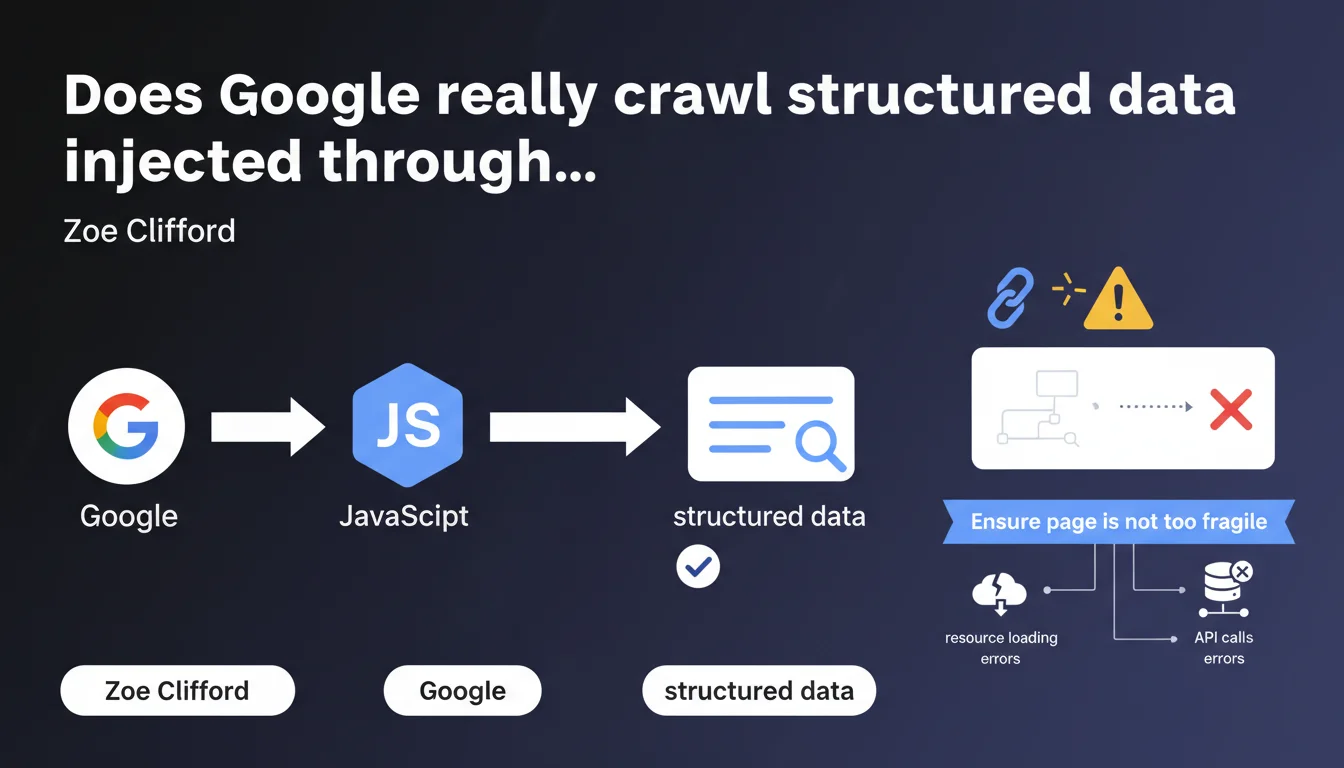
Google confirms that implementing structured data via JavaScript works correctly thanks to its JS execution capability. The real risk lies elsewhere: the fragility of the page in case of loading errors or API call failures. A warning that reveals the practical limits of client-side rendering.
What you need to understand
Why does Google keep emphasizing its mastery of JavaScript?
For years, Google has repeated that it can perfectly execute and index JavaScript. This statement fits into that pattern: reassuring developers who favor modern frameworks (React, Vue, Next.js) rather than traditional server-side rendering.
Concretely, if your structured data (Schema.org, JSON-LD) is dynamically injected via JS, Google will detect and exploit it — provided the script executes correctly. This isn't new, but the nuance about "fragility" deserves attention.
What does a "too fragile" page mean according to Google?
The expression "too fragile page" refers to a silent failure scenario: your script loads structured data via a third-party API, that API is slow or unavailable, the timeout expires, and your Schema markup never appears. Googlebot passes, crawls, and leaves without anything.
This isn't a problem with Google's technical capability, but with the robustness of your implementation. If your architecture depends on a chain of external dependencies, every link can break.
What are the concrete risks identified by this statement?
- Unhandled JavaScript errors that block complete page execution
- Failed API calls (timeout, 500, rate limiting) that prevent data injection
- Unavailable external resources (third-party CDN, analytics scripts) that interrupt rendering
- Missing fallback mechanisms: no backup plan if JS doesn't execute
- Blocking scripts that delay rendering beyond the allocated crawl budget
SEO Expert opinion
Is this statement consistent with field observations?
Yes, in principle. Google does effectively crawl JS and extract dynamically injected structured data — we verify this regularly with the Rich Results testing tool. But the part about "Google excels" deserves nuance.
In practice, JS rendering remains resource-intensive for Google. It requires a second wave of crawl (wave of indexing), which introduces a delay between URL discovery and indexing of rendered content. On massive sites with tight crawl budgets, this delay can be problematic.
What are the blind spots in this claim?
[To verify] Google doesn't specify how much its JS engine tolerates partial errors. If a script crashes but 80% of content displays, does it index the partial version or wait for complete rendering? Field reports are contradictory.
Another point: the statement doesn't mention crawl prioritization. A page with pure HTML structured data will be processed faster than a page requiring JS execution — this is an established fact, even though Google minimizes the gap.
In which cases does this rule not apply?
If your site requires ultra-fast indexing (news, e-commerce with fluctuating stock), betting on JS for critical data remains risky. The window between publication and actual crawl could make you lose opportunities.
Practical impact and recommendations
What should you do concretely to secure your structured data in JS?
First, prioritize server-side rendering (SSR) or static generation (SSG) for critical structured data. If you're using Next.js, Nuxt, or Gatsby, inject your Schema markup at build time or server rendering — not client-side.
If JS is unavoidable, implement a fallback system: a minimal JSON-LD in pure HTML that loads even if the script fails. It's not elegant, but it guarantees that Google retrieves at least the essential information.
How do you verify that your JS structured data is being crawled?
Use the URL Inspection Tool in Search Console. It simulates Googlebot rendering and shows you what's actually being indexed. Compare the "crawled" version with the "live" version — any discrepancy signals a problem.
Then, monitor Core Web Vitals and JS execution time. If your script takes more than 3 seconds to run on mobile 3G, Google may abandon it before extracting your structured data.
What mistakes should you absolutely avoid?
- Don't skip testing Googlebot rendering — always verify with Search Console or a headless crawl tool
- Don't rely on API calls without timeout and retry mechanisms — a network failure = missing data
- Don't load scripts in a blocking manner — use async or defer consistently
- Don't ignore JS errors in production — monitor with Sentry, LogRocket or equivalent
- Don't fail to plan a degraded version if JS doesn't execute
- Don't inject structured data after user interaction (scroll, click) — Googlebot doesn't interact
Google crawls JS, that's established. But the reliability of your implementation remains your responsibility. Prioritize SSR/SSG, test exhaustively, and never rely on JS alone for critical data.
These optimizations require solid architecture and continuous monitoring. If you lack internal resources or your technical stack is complex, support from a specialized SEO agency can help you avoid costly mistakes and guarantee a sustainable implementation tailored to your business needs.
❓ Frequently Asked Questions
Les données structurées en JS sont-elles indexées aussi rapidement qu'en HTML pur ?
Si mon script plante, Google indexe-t-il quand même la page ?
Dois-je abandonner le JS pour mes données structurées ?
Comment détecter si mes données structurées JS ne sont pas crawlées ?
Les frameworks JS comme React posent-ils problème pour le SEO ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 11/07/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.