Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google rend-il vraiment toutes les pages HTML indexables sans exception ?
- □ Googlebot suit-il vraiment Chrome en temps réel ?
- □ Les redirections JavaScript sont-elles vraiment traitées comme des redirections serveur par Google ?
- □ Pourquoi le rendu Google ne sera jamais vraiment celui d'un navigateur standard ?
- □ Faut-il vraiment débloquer toutes vos ressources dans robots.txt pour éviter les problèmes d'indexation ?
- □ Google conserve-t-il vraiment les cookies entre chaque rendu de page ?
- □ Pourquoi Google ignore-t-il les bannières de consentement des cookies lors du crawl ?
- □ Faut-il abandonner le dynamic rendering basé sur le user-agent de Googlebot ?
- □ Pourquoi la gestion d'erreurs JavaScript conditionne-t-elle désormais votre capacité à être indexé par Google ?
- □ L'outil d'inspection d'URL est-il vraiment fiable pour tester le rendu par Googlebot ?
- □ Pourquoi Google rend-il toutes les pages HTML même celles qui n'ont pas besoin de JavaScript ?
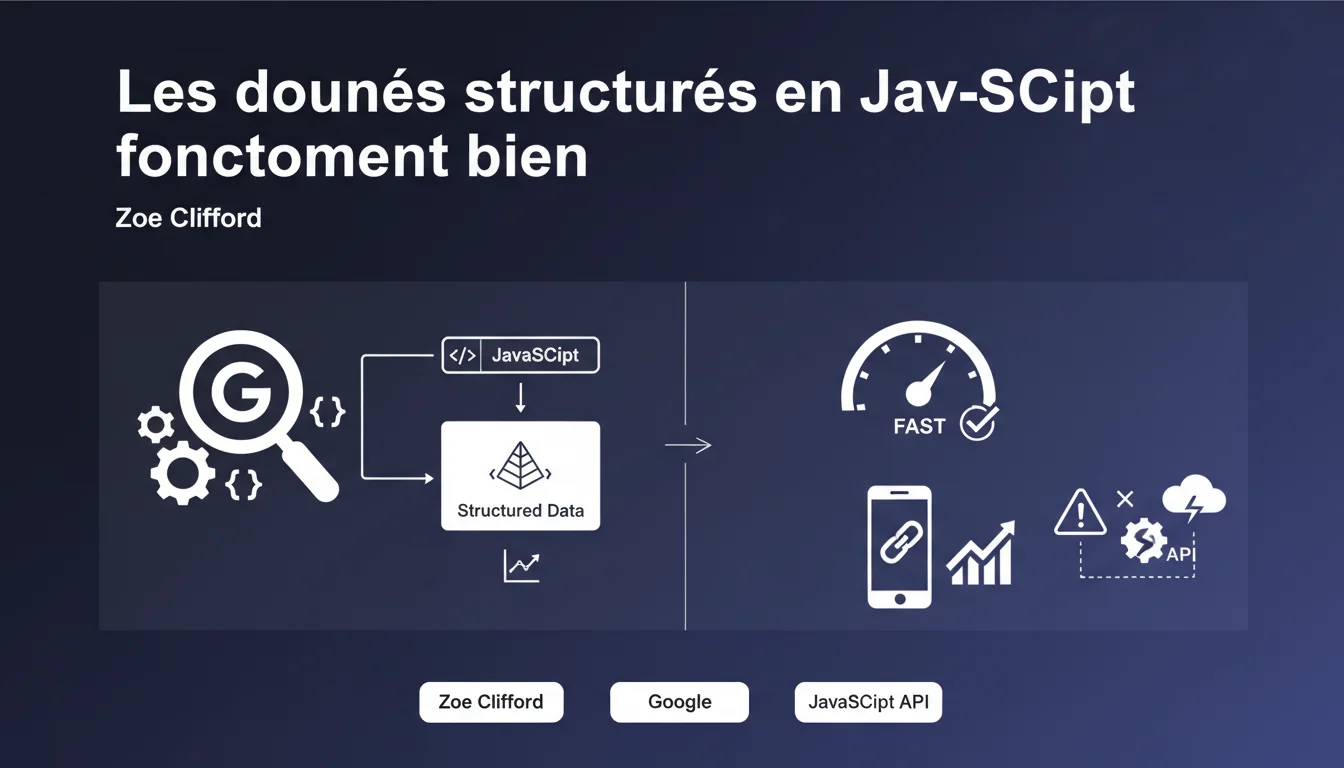
Google confirme que l'implémentation de données structurées via JavaScript fonctionne correctement grâce à sa capacité d'exécution JS. Le vrai risque se situe ailleurs : la fragilité de la page en cas d'erreur de chargement ou d'échec d'appels API. Une mise en garde qui révèle les limites pratiques du rendu côté client.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur sa maîtrise du JavaScript ?
Depuis des années, Google répète qu'il sait parfaitement exécuter et indexer le JavaScript. Cette déclaration s'inscrit dans cette lignée : rassurer les développeurs qui privilégient les frameworks modernes (React, Vue, Next.js) plutôt que le rendu serveur classique.
Concrètement, si vos données structurées (Schema.org, JSON-LD) sont injectées dynamiquement via JS, Google les détectera et les exploitera — sous réserve que le script s'exécute correctement. Ce n'est pas nouveau, mais la nuance apportée sur la « fragilité » mérite attention.
Que signifie une page « trop fragile » selon Google ?
L'expression « page trop fragile » désigne un scénario d'échec silencieux : votre script charge les données structurées via une API tierce, cette API est lente ou indisponible, le timeout expire, et vos marqueurs Schema ne s'affichent jamais. Googlebot passe, crawle, et repart sans rien.
Ce n'est pas un problème de capacité technique de Google, mais de robustesse de votre implémentation. Si votre architecture dépend d'une chaîne de dépendances externes, chaque maillon peut casser.
Quels sont les risques concrets identifiés par cette déclaration ?
- Erreurs JavaScript non gérées qui bloquent l'exécution complète de la page
- Appels API qui échouent (timeout, 500, rate limiting) et empêchent l'injection des données
- Ressources externes indisponibles (CDN tiers, scripts analytics) qui interrompent le rendu
- Absence de fallback : pas de mécanisme de secours si le JS ne s'exécute pas
- Scripts bloquants qui retardent le rendu au-delà du budget de crawl alloué
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, sur le principe. Google crawle effectivement le JS et extrait les données structurées injectées dynamiquement — on le vérifie régulièrement avec l'outil de test des résultats enrichis. Mais la partie « Google excelle » mérite nuance.
Dans la pratique, le rendu JS reste coûteux en ressources pour Google. Il nécessite une seconde vague de crawl (wave of indexing), ce qui introduit un délai entre la découverte de l'URL et l'indexation du contenu rendu. Sur des sites massifs avec des budgets de crawl serrés, ce délai peut être problématique.
Quels sont les angles morts de cette affirmation ?
[À vérifier] Google ne précise pas à quel point son moteur JS tolère les erreurs partielles. Si un script plante mais que 80 % du contenu s'affiche, indexe-t-il la version partielle ou attend-il un rendu complet ? Les retours terrain sont contradictoires.
Autre point : la déclaration ne mentionne pas la priorisation du crawl. Une page avec données structurées en HTML pur sera traitée plus rapidement qu'une page nécessitant exécution JS — c'est un fait établi, même si Google minimise l'écart.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site nécessite une indexation ultra-rapide (actualités, e-commerce avec stocks fluctuants), miser sur du JS pour les données critiques reste risqué. La window entre publication et crawl effectif peut vous faire perdre des opportunités.
Impact pratique et recommandations
Que faut-il faire concrètement pour sécuriser vos données structurées en JS ?
D'abord, privilégiez le rendu côté serveur (SSR) ou la génération statique (SSG) pour les données structurées critiques. Si vous utilisez Next.js, Nuxt ou Gatsby, injectez vos marqueurs Schema au build ou au rendu serveur — pas côté client.
Si le JS est incontournable, implémentez un système de fallback : un JSON-LD minimal en HTML pur qui se charge même si le script échoue. Ce n'est pas élégant, mais ça garantit que Google récupère au minimum les infos essentielles.
Comment vérifier que vos données structurées JS sont bien crawlées ?
Utilisez l'outil d'inspection d'URL de la Search Console. Il simule le rendu Googlebot et vous montre ce qui est effectivement indexé. Comparez la version « crawlée » et la version « en direct » — tout écart signale un problème.
Ensuite, monitorer les Core Web Vitals et le temps d'exécution JS. Si votre script met plus de 3 secondes à s'exécuter sur un mobile 3G, Google risque d'abandonner avant d'extraire vos données structurées.
Quelles erreurs éviter absolument ?
- Ne pas tester le rendu Googlebot — toujours vérifier avec la Search Console ou un outil de crawl headless
- Dépendre d'appels API sans timeout ni retry — un échec réseau = données manquantes
- Charger les scripts de manière bloquante — utilisez async ou defer systématiquement
- Ignorer les erreurs JS en production — monitorer avec Sentry, LogRocket ou équivalent
- Ne pas prévoir de version dégradée si le JS ne s'exécute pas
- Injecter des données structurées après user interaction (scroll, clic) — Googlebot ne clique pas
Google crawle le JS, c'est acquis. Mais la fiabilité de votre implémentation reste votre responsabilité. Privilégiez SSR/SSG, testez exhaustivement, et ne comptez jamais sur le JS seul pour des données critiques.
Ces optimisations demandent une architecture solide et une surveillance continue. Si vous manquez de ressources internes ou que votre stack technique est complexe, un accompagnement par une agence SEO spécialisée peut vous éviter des erreurs coûteuses et garantir une implémentation pérenne adaptée à vos enjeux métier.
❓ Questions frequentes
Les données structurées en JS sont-elles indexées aussi rapidement qu'en HTML pur ?
Si mon script plante, Google indexe-t-il quand même la page ?
Dois-je abandonner le JS pour mes données structurées ?
Comment détecter si mes données structurées JS ne sont pas crawlées ?
Les frameworks JS comme React posent-ils problème pour le SEO ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 11/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.