Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google rend-il vraiment toutes les pages HTML indexables sans exception ?
- □ Googlebot suit-il vraiment Chrome en temps réel ?
- □ Les données structurées injectées en JavaScript sont-elles vraiment crawlées par Google ?
- □ Les redirections JavaScript sont-elles vraiment traitées comme des redirections serveur par Google ?
- □ Pourquoi le rendu Google ne sera jamais vraiment celui d'un navigateur standard ?
- □ Faut-il vraiment débloquer toutes vos ressources dans robots.txt pour éviter les problèmes d'indexation ?
- □ Google conserve-t-il vraiment les cookies entre chaque rendu de page ?
- □ Pourquoi Google ignore-t-il les bannières de consentement des cookies lors du crawl ?
- □ Faut-il abandonner le dynamic rendering basé sur le user-agent de Googlebot ?
- □ L'outil d'inspection d'URL est-il vraiment fiable pour tester le rendu par Googlebot ?
- □ Pourquoi Google rend-il toutes les pages HTML même celles qui n'ont pas besoin de JavaScript ?
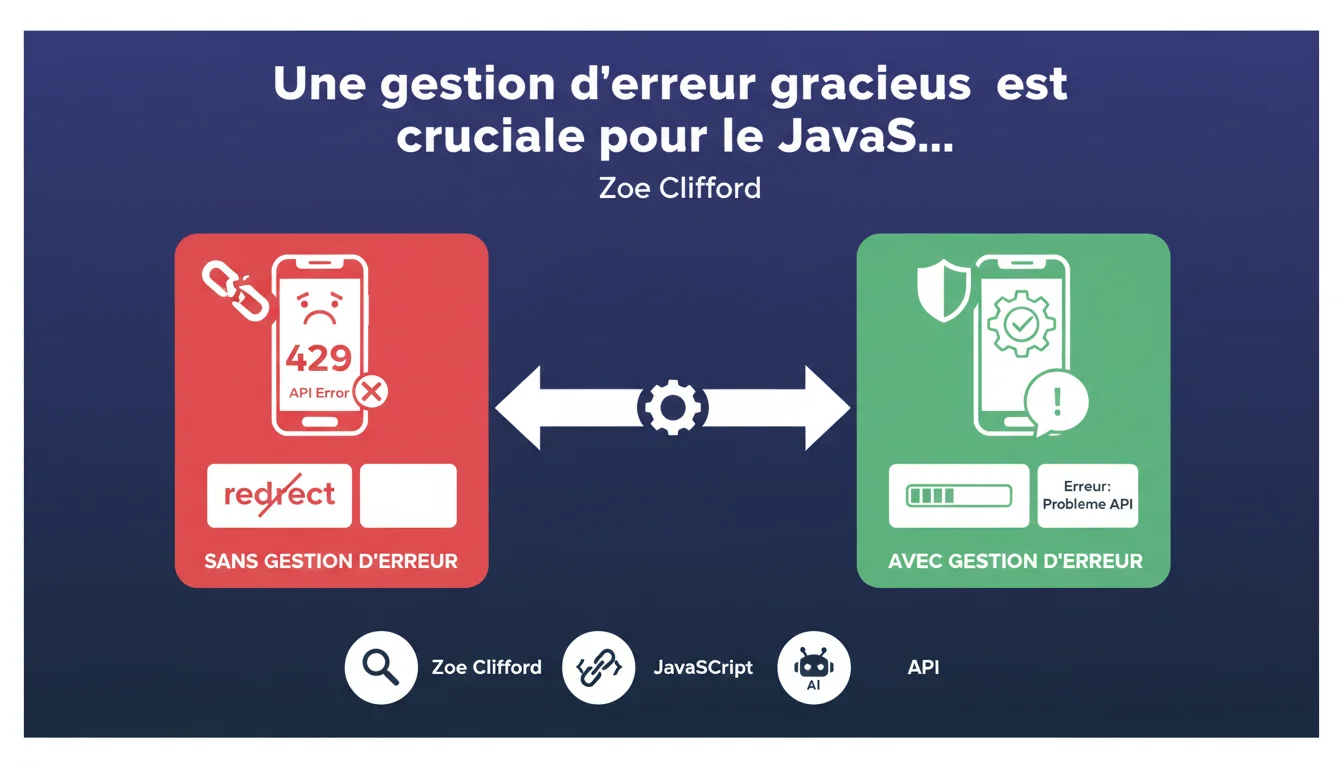
Google affirme qu'une page rencontrant une erreur JavaScript (API timeout, 429, etc.) doit continuer à fonctionner et afficher du contenu partiel, pas une page blanche ni une redirection. Si votre JavaScript plante et casse l'affichage, Googlebot verra exactement ce qu'un visiteur verrait : rien. C'est le genre de détail technique qui peut tuer l'indexation d'une section entière de votre site sans que vous le remarquiez.
Ce qu'il faut comprendre
Qu'est-ce que la "gestion d'erreur gracieuse" en pratique pour Googlebot ?
Googlebot exécute JavaScript comme un navigateur moderne. Si votre code JavaScript rencontre une erreur — timeout d'API, erreur 429 (trop de requêtes), réponse serveur malformée — et que cette erreur n'est pas interceptée, toute la page peut planter.
Le résultat ? Une page blanche, un écran figé sur un loader, ou pire, une redirection vers une page d'erreur générique. Googlebot crawle cette version cassée et n'indexe rien d'utile. Le "graceful degradation" consiste à afficher un message clair ("Impossible de charger ce module pour le moment") ou du contenu partiel, plutôt que de tout faire sauter.
Pourquoi Google insiste-t-il autant sur ce point maintenant ?
Parce que les sites modernes dépendent massivement d'appels API asynchrones — recommandations produits, avis clients, contenus dynamiques. Si ces appels échouent et que personne n'a prévu de fallback, la page devient vide aux yeux de Googlebot.
Google veut que les sites soient résilients. Il ne vous demande pas de garantir zéro erreur — il vous demande de gérer ces erreurs pour que l'essentiel reste accessible. Concrètement, ça veut dire : try/catch, gestion des promesses rejetées, affichage conditionnel.
Quels sont les cas typiques qui déclenchent ce problème ?
- APIs tierces instables : widgets sociaux, modules de recommandation, outils analytics qui plantent et bloquent le rendu
- Rate limiting côté serveur : erreur 429 si Googlebot crawle trop vite vos endpoints internes
- Timeouts non gérés : un appel qui met 10 secondes sans réponse et freeze l'interface
- Erreurs réseau : CDN indisponible, certificat SSL expiré sur une ressource externe
- Mauvaise gestion des états : composants React/Vue qui crashent si les données attendues sont absentes
Avis d'un expert SEO
Cette consigne reflète-t-elle vraiment le comportement observé de Googlebot ?
Oui, et c'est documenté depuis des années. Googlebot utilise une version récente de Chrome et exécute JavaScript avec un timeout de ~5 secondes par défaut. Si votre code bloque ou plante pendant ce laps de temps, il indexe ce qu'il voit : souvent, rien.
Les tests terrain confirment que les sites avec gestion d'erreur robuste ont un taux d'indexation plus stable sur les pages dynamiques. À l'inverse, une erreur JavaScript non catchée peut rendre invisible toute une catégorie de pages lors d'un pic de trafic ou d'une instabilité API.
Dans quels cas cette recommandation devient-elle complexe à appliquer ?
Sur les sites à forte dépendance SPA (Single Page Application), où tout le contenu dépend d'un appel API initial. Si cet appel échoue et qu'aucun fallback SSR (Server-Side Rendering) ou cache statique n'existe, vous n'avez rien à afficher — graceful ou pas.
Autre difficulté : les erreurs silencieuses. Certaines librairies tierces (analytics, chatbots, pixels publicitaires) plantent sans lever d'exception visible. Vous ne pouvez pas catcher ce que vous ne voyez pas. [A vérifier] : Google recommande d'utiliser des outils de monitoring comme Sentry pour identifier ces crashs invisibles, mais il ne précise pas comment Googlebot les traite concrètement.
Y a-t-il un risque de sur-optimiser cette partie ?
Oui — si vous passez trop de temps à gérer chaque edge case d'API tierce non critique. Concentrez-vous sur les appels bloquants : ceux qui affichent le contenu principal, les titres H1, les descriptions produits.
Les modules secondaires (avis clients, suggestions) peuvent échouer sans casser l'indexation, tant que le cœur de la page reste accessible. Ne perdez pas trois semaines à blinder un widget social qui n'apporte aucune valeur SEO.
Impact pratique et recommandations
Que faut-il auditer en priorité sur son site ?
Testez vos pages clés en throttling réseau (simulation 3G lente) et en bloquant certains endpoints API. Utilisez les DevTools Chrome : onglet Network, clic droit sur une requête, "Block request URL". Rechargez la page. Que voyez-vous ?
Si la page devient blanche ou affiche un loader infini, vous avez un problème. Googlebot verra exactement ça. Faites ce test sur : pages catégories, fiches produits, articles de blog, landing pages stratégiques.
Quelles sont les solutions techniques concrètes à mettre en place ?
Première ligne de défense : encapsulez tous vos appels API dans des blocs try/catch ou des gestionnaires .catch() sur les promesses. Si une erreur survient, affichez un message utilisateur clair ou un contenu par défaut.
Deuxième levier : SSR ou pré-rendering. Si possible, générez une version HTML statique de vos pages critiques au build. Même si l'hydratation JavaScript échoue ensuite, Googlebot indexe le HTML de base.
Troisième option : Progressive Enhancement. Le contenu essentiel (H1, texte principal, images) doit être présent dans le HTML initial, pas injecté uniquement par JavaScript. Les modules dynamiques s'ajoutent ensuite, mais leur échec ne casse rien.
- Auditez toutes les pages stratégiques en simulant des erreurs réseau et API
- Implémentez des blocs try/catch autour de chaque appel asynchrone critique
- Ajoutez des états de fallback : messages d'erreur clairs, contenu partiel, versions dégradées
- Utilisez un outil de monitoring JavaScript (Sentry, LogRocket) pour traquer les erreurs en production
- Testez le rendu côté Googlebot via Search Console (Inspection d'URL) après chaque déploiement
- Privilégiez SSR ou pré-rendering pour les pages à fort enjeu SEO
- Documentez les dépendances critiques : quelles APIs doivent absolument fonctionner pour que la page reste indexable ?
❓ Questions frequentes
Est-ce que Googlebot exécute vraiment JavaScript sur toutes les pages qu'il crawle ?
Une erreur 429 sur une API tierce peut-elle impacter mon indexation ?
Comment savoir si mes pages JavaScript plantent pour Googlebot ?
Faut-il abandonner les SPAs pour être bien indexé par Google ?
Les outils de monitoring JavaScript aident-ils vraiment pour le SEO ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 11/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.