Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google rend-il vraiment toutes les pages HTML indexables sans exception ?
- □ Googlebot suit-il vraiment Chrome en temps réel ?
- □ Les données structurées injectées en JavaScript sont-elles vraiment crawlées par Google ?
- □ Les redirections JavaScript sont-elles vraiment traitées comme des redirections serveur par Google ?
- □ Faut-il vraiment débloquer toutes vos ressources dans robots.txt pour éviter les problèmes d'indexation ?
- □ Google conserve-t-il vraiment les cookies entre chaque rendu de page ?
- □ Pourquoi Google ignore-t-il les bannières de consentement des cookies lors du crawl ?
- □ Faut-il abandonner le dynamic rendering basé sur le user-agent de Googlebot ?
- □ Pourquoi la gestion d'erreurs JavaScript conditionne-t-elle désormais votre capacité à être indexé par Google ?
- □ L'outil d'inspection d'URL est-il vraiment fiable pour tester le rendu par Googlebot ?
- □ Pourquoi Google rend-il toutes les pages HTML même celles qui n'ont pas besoin de JavaScript ?
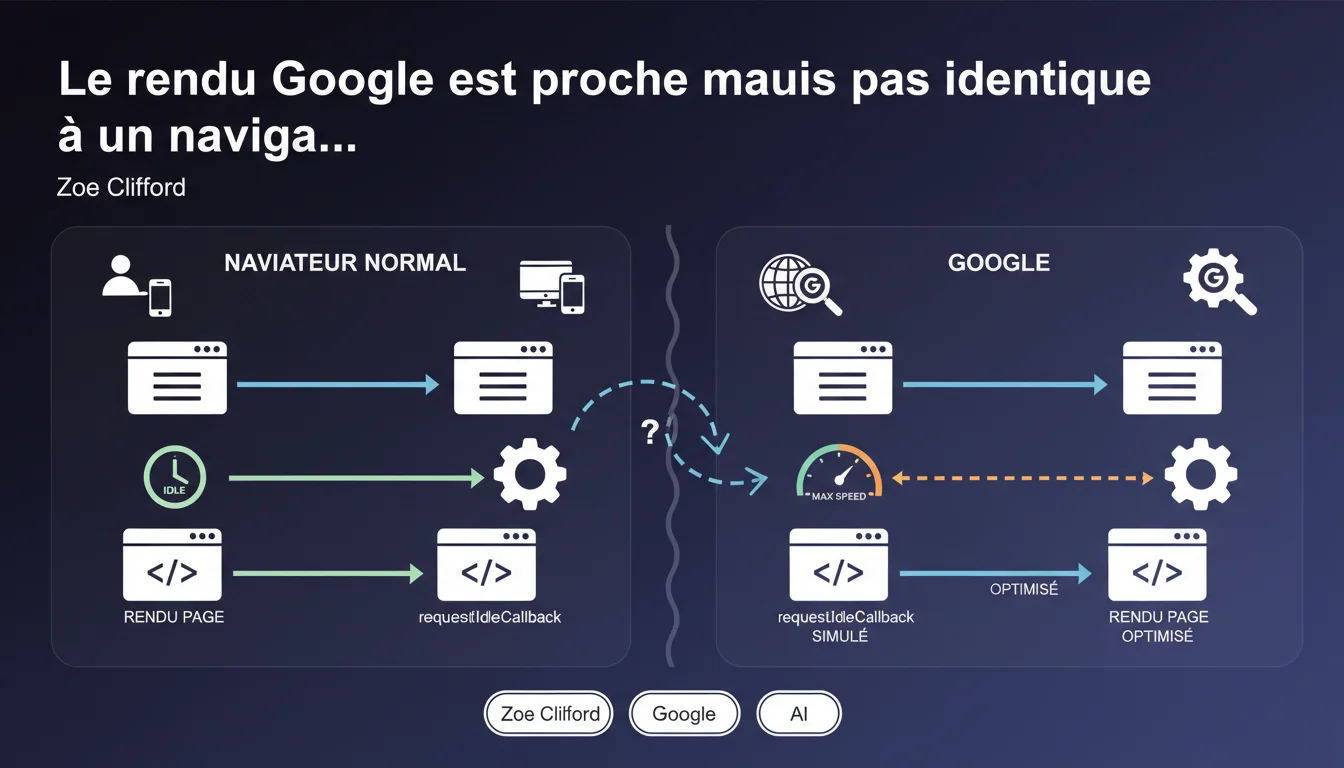
Google simule certains événements JavaScript comme requestIdleCallback parce que son moteur de rendu n'est jamais réellement inactif. Cette optimisation d'efficacité peut casser les sites qui attendent un comportement navigateur classique. Si votre JavaScript dépend de cycles d'inactivité précis, vous risquez un rendu incomplet côté Google.
Ce qu'il faut comprendre
Google affirme que son moteur de rendu se rapproche d'un navigateur moderne, mais avec des ajustements pour gagner en rapidité. Concrètement, le robot ne peut pas se permettre d'attendre indéfiniment que tous les scripts aient fini leur ballet asynchrone.
L'événement requestIdleCallback permet normalement à un développeur de déclencher du code uniquement quand le navigateur est au repos. Problème : le crawler Google n'a jamais de temps mort — il enchaîne les tâches sans pause. Résultat, cet événement est simulé, ce qui signifie que le callback peut s'exécuter dans un timing différent, voire pas du tout.
Qu'est-ce que requestIdleCallback et pourquoi est-ce important ?
Cet API W3C planifie du code non critique pendant les moments creux : analytics, lazy-loading avancé, prefetch de données. Les développeurs l'utilisent pour éviter de bloquer le thread principal et garantir des Core Web Vitals propres.
Mais si Google simule l'inactivité au lieu de la mesurer réellement, un script qui attend ce signal pour afficher du contenu risque de ne jamais se déclencher. Et si ce contenu est une section de texte ou des liens structurants, c'est un trou noir pour l'indexation.
Google dit « aussi proche que possible » — ça veut dire quoi en pratique ?
La formulation reste floue. Google utilise Chromium, donc la base moteur est identique à Chrome. Mais les couches d'optimisation — timeout agressifs, désactivation de certaines API, gestion différente des ressources — créent un environnement hybride.
En clair, un site peut s'afficher parfaitement dans Chrome et rater son rendu chez Google. C'est particulièrement vrai pour les frameworks JavaScript lourds (React, Vue, Angular) qui orchestrent plusieurs cycles de rendu.
- Le rendu Google se base sur Chromium mais applique des optimisations de crawl spécifiques
- requestIdleCallback est simulé, ce qui peut décaler ou annuler certains callbacks
- Les sites dépendant de cycles d'inactivité précis risquent un rendu incomplet côté Google
- La différence entre Chrome local et Googlebot peut être invisible en dev mais critique en production
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Depuis que Google a basculé sur le rendu evergreen (Chromium régulièrement mis à jour), la majorité des sites JavaScript s'indexent correctement. Mais les cas limites — SPA complexes, hydratation différée, code qui attend des signaux précis — posent encore problème.
J'ai vu des clients perdre 15 à 20 % de leur contenu indexable parce qu'un composant React attendait un intersection observer couplé à un requestIdleCallback. Google déclenchait l'observer mais pas le callback, donc le contenu restait masqué. [A vérifier] : Google ne publie aucune métrique sur le taux de réussite de ces callbacks simulés — impossible de savoir si c'est anecdotique ou systémique.
Quelles nuances faut-il apporter à cette affirmation ?
Google parle d'optimisations d'efficacité sans détailler lesquelles. On sait qu'il applique des timeouts stricts (5 secondes pour le premier rendu, quelques secondes supplémentaires pour les événements post-load). Mais sur les API précises désactivées ou modifiées, silence radio.
Autre point : la simulation de requestIdleCallback n'est pas documentée dans les ressources officielles pour développeurs. On l'apprend via une citation de Zoe Clifford, mais aucun guide technique ne liste les comportements divergents entre Chrome et Googlebot. Ça complique le debug — tu testes en local, tout fonctionne, puis Search Console te signale du contenu manquant sans explication.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre JavaScript reste simple — rendu direct, hydratation immédiate, pas de dépendance à des API exotiques — vous ne verrez aucune différence. Les frameworks modernes en mode SSR ou SSG (Next.js, Nuxt, SvelteKit) envoient du HTML pré-rendu, donc le problème ne se pose même pas.
Mais dès que vous optimisez pour la performance utilisateur en différant certaines opérations, vous entrez dans une zone grise. Google privilégie la vitesse de crawl sur la fidélité parfaite au comportement navigateur. C'est un choix assumé, mais rarement explicite dans la doc.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter les écarts de rendu ?
D'abord, identifiez si votre code utilise requestIdleCallback. Cherchez dans votre codebase (grep sur « requestIdleCallback » ou inspectez les dépendances npm). Si c'est le cas, vérifiez que le contenu critique ne dépend pas de ce callback pour s'afficher.
Ensuite, testez le rendu avec l'outil d'inspection d'URL de Search Console. Comparez le HTML rendu par Google avec celui que vous voyez dans Chrome DevTools. Si des sections manquent, c'est un signal d'alerte — soit le timeout est trop court, soit un callback n'a pas été déclenché.
Quelles erreurs éviter lors de l'implémentation JavaScript ?
Ne cachez jamais du contenu essentiel derrière un événement asynchrone incertain. Si vous lazy-loadez du texte ou des liens, utilisez des mécanismes robustes : intersection observer seul (sans dépendance à requestIdleCallback), ou mieux, du SSR/SSG qui envoie le HTML directement.
Évitez aussi de compter sur des API non standard ou mal supportées. Google suit Chromium, mais avec un décalage. Si vous utilisez des features expérimentales (flags Chrome), il y a de fortes chances qu'elles ne soient pas activées côté Googlebot.
- Auditez votre code pour repérer les usages de requestIdleCallback
- Testez le rendu avec l'outil d'inspection d'URL de Search Console sur plusieurs pages types
- Comparez le DOM rendu par Google avec celui de Chrome en local (DOM snapshot ou HTML source)
- Privilégiez le SSR ou SSG pour le contenu critique (titres, corps de texte, liens internes)
- Si vous devez différer du contenu, utilisez des triggers fiables : intersection observer, scroll events, timers simples
- Documentez les choix d'architecture frontend et leur impact SEO dans votre équipe dev
Le rendu Google n'est pas un Chrome classique — il simule certains événements pour gagner en vitesse. Si votre JavaScript orchestre finement les cycles d'inactivité, vous risquez un rendu partiel. Testez, comparez, et privilégiez toujours le contenu servi côté serveur pour les éléments critiques.
Ces ajustements techniques demandent une compréhension fine de l'architecture JavaScript et du comportement de Googlebot. Si votre stack est complexe ou si vous constatez des écarts de rendu inexpliqués, l'accompagnement d'une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des pertes d'indexation coûteuses.
❓ Questions frequentes
Qu'est-ce que requestIdleCallback et pourquoi Google le simule ?
Mon site React/Vue risque-t-il d'être mal indexé à cause de ce comportement ?
Comment vérifier si Google voit bien tout mon contenu JavaScript ?
Google suit-il toujours la dernière version de Chrome ?
Faut-il abandonner requestIdleCallback pour le SEO ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 11/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.