Official statement
Other statements from this video 8 ▾
- □ Peut-on vraiment forcer Google à ré-indexer un site entier d'un coup ?
- □ Google réindexe-t-il automatiquement les changements majeurs sur un site ?
- □ Pourquoi une simple redirection 301 peut-elle faire toute la différence lors d'une refonte ?
- □ Faut-il vraiment utiliser un code 404 ou 410 pour les pages supprimées ?
- □ Pourquoi lier vos nouvelles pages depuis le site existant est-il crucial pour l'indexation Google ?
- □ Faut-il vraiment lier ses nouvelles pages depuis les pages importantes pour accélérer l'indexation ?
- □ Pourquoi Google recommande-t-il d'afficher les changements critiques sur les pages existantes plutôt que de créer de nouvelles pages ?
- □ Les sitemaps XML sont-ils vraiment indispensables pour l'indexation de votre site ?
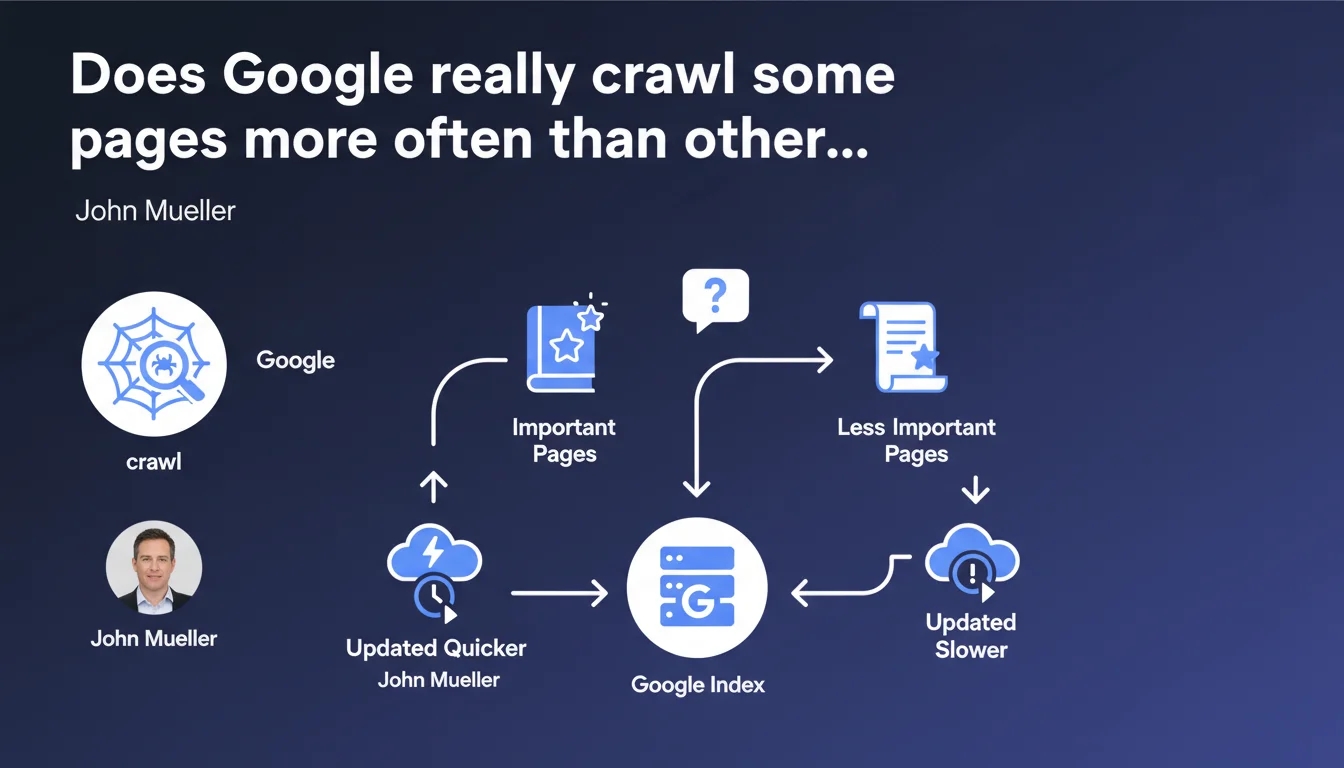
Google prioritizes crawling pages it considers important, which means they'll be indexed and updated faster. The SEO challenge: understanding how Google evaluates this 'importance' and optimizing the signals that trigger frequent crawling. The catch? Mueller deliberately stays vague about the exact criteria.
What you need to understand
How does Google determine if a page is 'important'?
Mueller's statement is based on a simple observation: not all content is equal in Google's eyes. The engine allocates its crawl time according to a hierarchy it establishes itself.
In practice, several factors come into play: the volume of traffic to the page, the frequency of content updates, the quality of internal linking, and the presence of backlinks pointing to it. A page that generates regular clicks from the SERP, is linked from the homepage, or receives quality external links sends a strong signal to Google.
But be careful: Google publishes no official scoring grid. We're reduced to observing real-world correlations.
What does this mean for crawl budget?
The crawl budget is the quantity of pages Googlebot is willing to explore on your site within a given timeframe. If your crawl resources are monopolized by secondary pages — facet filters, infinite paginated archives, duplicate content — your strategic pages risk being crawled less frequently.
Mueller confirms here that Google makes a distinction. Large sites (e-commerce, media) are particularly affected: without optimized architecture, new important pages can remain invisible for days, even weeks.
What are the concrete indicators Google uses to prioritize?
Google never provides an exhaustive list — and that's where it gets tricky. We know that certain criteria matter more than others, but their exact weighting remains opaque.
- Update frequency: a regularly modified page will be checked more often
- Depth in site architecture: the more accessible a URL is in fewer clicks from the homepage, the better
- Engagement signals: pages that generate organic traffic, clicks from the SERP, time on page
- External authority: quality backlinks, mentions on authoritative sites
- Technical performance: loading speed, server stability, absence of 5xx errors
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, broadly speaking. Server logs confirm that Google crawls in a differentiated manner. On an e-commerce site with 50,000 products, bestseller product pages are visited several times daily, while items out of stock for months aren't even explored anymore.
But Mueller sidesteps the most actionable part: how to influence this prioritization? He says 'important pages are crawled more often,' without clarifying whether it's a consequence (Google detects importance) or a lever (you can force the issue). [To verify]
What nuances should be added to this claim?
First point: 'frequent updates' is not synonymous with better rankings. A page can be crawled daily and stagnate on page 3 if its content is mediocre. Frequent crawling is only a prerequisite — not a guarantee of visibility.
Second nuance: some sites have such a limited crawl budget that even their strategic pages are undercrawled. Typically, a technically flawed site (response time > 2 seconds, chain redirects, intermittent errors) can see Googlebot drastically reduce its visit frequency, regardless of the theoretical importance of the pages.
In what cases does this rule not apply?
Niche sites with few pages (< 500 URLs) are generally not affected by these prioritization issues. Google crawls the entire site regularly, except in case of major technical blocking.
Another exception: news content. Google News has specific mechanisms to detect new content in near real-time. A news article published on a media outlet can be crawled within minutes, independent of the typical 'importance hierarchy.'
Practical impact and recommendations
What should you do concretely to favor crawling of strategic pages?
First, identify which pages truly deserve frequent crawling. Your T&Cs don't need to be visited daily. Focus your efforts on traffic-generating or conversion-driving content: top product sheets, high-potential blog articles, main category pages.
Next, optimize your internal linking to push these strategic pages up the hierarchy. Link them from the homepage, main menu, or well-positioned thematic hubs. The more accessible a page is in fewer clicks, the more Google considers it important.
Finally, monitor your server logs to verify the reality of crawling. A theoretically strategic page visited only once monthly by Googlebot reveals a structural problem.
What mistakes must you absolutely avoid?
Don't waste crawl budget on useless pages. Block facet filters via robots.txt, infinite pagination, parameterized URLs with no added value — anything that dilutes Googlebot's attention on non-strategic content.
Another trap: believing an XML sitemap is sufficient. Google uses it as a hint, not a directive. If your pages listed in the sitemap are buried 8 clicks deep and have no backlinks, they won't be crawled frequently.
How can you verify that your site complies with these best practices?
- Analyze your server logs to identify frequently crawled pages versus those ignored by Googlebot
- Verify that your strategic pages are accessible in less than 3 clicks from the homepage
- Audit your internal linking: important pages should receive links from other site sections
- Control loading speed and technical stability — a slow server drastically reduces crawl budget
- Use Search Console to spot 'discovered but not crawled' URLs: this often signals a prioritization problem
- Block non-strategic areas via robots.txt or noindex (filters, internal searches, archives)
❓ Frequently Asked Questions
Est-ce que soumettre une URL via la Search Console accélère son crawl ?
Le sitemap XML influence-t-il vraiment la fréquence de crawl ?
Comment savoir si mon crawl budget est saturé ?
Les backlinks influencent-ils directement la fréquence de crawl ?
Faut-il modifier régulièrement une page pour qu'elle soit crawlée plus souvent ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 23/01/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.