Official statement
Other statements from this video 7 ▾
- □ Les liens internes sont-ils vraiment traités comme des signaux UX par Googlebot ?
- □ Pourquoi l'élément HTML <a> avec attribut href est-il indispensable au crawl Google ?
- □ Pourquoi Google insiste-t-il pour que les liens restent de vrais liens HTML ?
- □ Le texte d'ancrage significatif est-il encore un levier SEO décisif ?
- □ Pourquoi trop de liens internes peuvent-ils nuire à votre SEO ?
- □ Comment trouver le bon équilibre dans la quantité de liens internes ?
- □ Pourquoi Google insiste-t-il encore sur l'importance des liens internes pour la navigation et la découverte de contenu ?
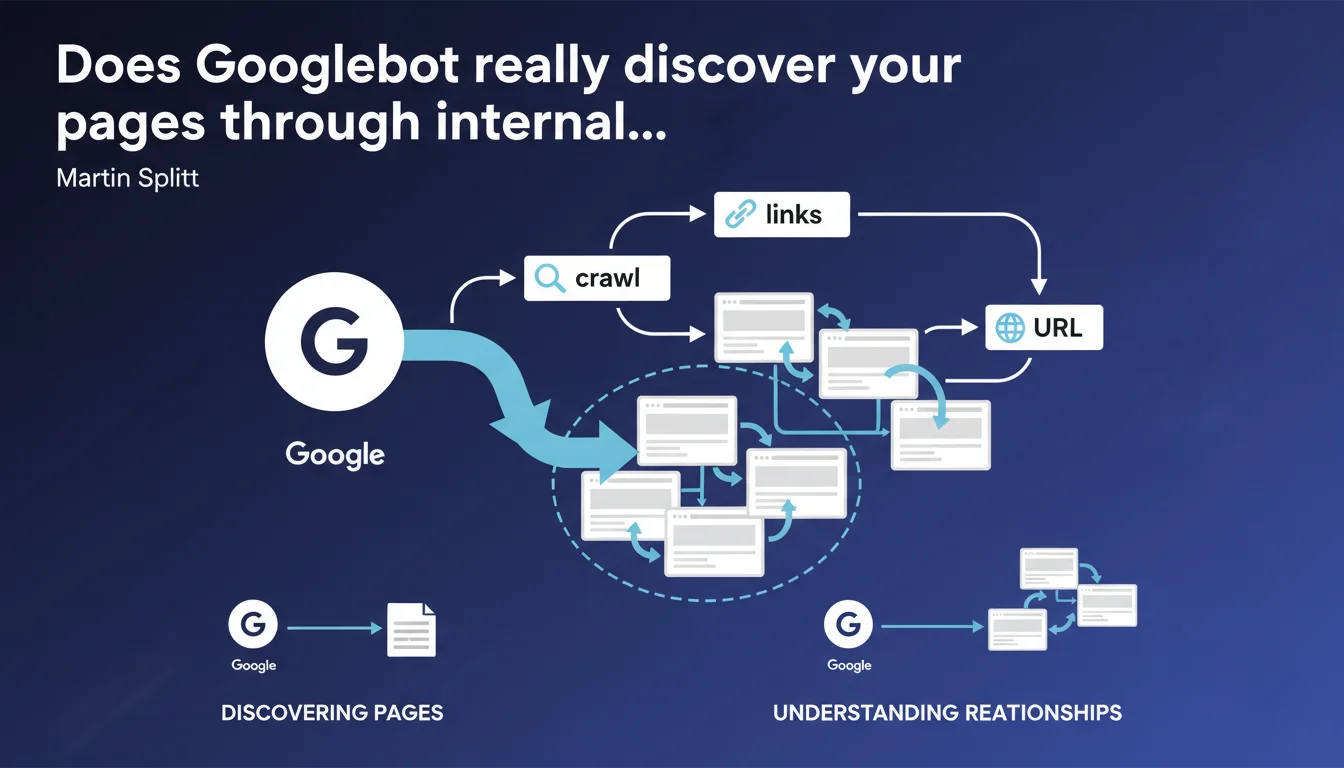
Googlebot uses internal links for two specific functions: discovering pages on your site and understanding their hierarchical relationships. Without internal links, a URL can remain invisible to Google even if it technically exists on your domain.
What you need to understand
Why are internal links critical for crawling?
Googlebot doesn't guess your site's structure. It follows hypertext links to move from one page to another, just like a user would. An orphaned page — with no internal links pointing to it — can completely escape crawling.
Martin Splitt clarifies that this logic also serves to understand the relationship between pages. The engine deduces the hierarchy, relative importance, and sometimes even the thematic context of a URL based on the links leading to it and their anchor text.
How does Googlebot decide which URLs to crawl?
When the bot finds a URL in your pages, it may try to crawl it — no guarantee. The phrasing "may try" reveals the constraints of crawl budget: Google doesn't promise to systematically visit every discovered URL.
Crawl budget depends on domain authority, content freshness, and the site's perceived quality. An internal link alone isn't enough to trigger immediate crawling if the site is deemed low priority.
What types of internal links does Google really count?
The statement remains deliberately vague on this point. We know that standard HTML links are taken into account. JavaScript links, if the JS is executed and the bot manages to render the page, can also be followed — but it's less reliable.
Links with internal nofollow are technically discovered, but their weight is debatable. Google stated that nofollow is now a "hint" rather than a strict directive, but nothing is settled.
- HTML links in the body or menus are the foundation of crawling.
- JavaScript links require client-side rendering — risk of latency or failure.
nofollowlinks can be followed, but their impact remains opaque.- XML sitemaps complement but never replace internal linking structure.
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, for the most part. Sites with a robust internal linking structure see their pages indexed faster than those relying solely on the sitemap. This is an established fact for years.
But the phrasing "may try to crawl" leaves enormous room for interpretation. In practice, we observe that Google regularly ignores discovered URLs if they appear redundant, low quality, or if crawl budget is tight. [To verify]: no official metric allows predicting whether a URL will actually be crawled.
What nuances should be noted for large sites?
On a site with 100,000 pages, internal linking can become a nightmare. Too many links dilute internal PageRank, too few create orphaned pages. Splitt's statement doesn't mention the concept of click depth — yet it's decisive.
A page accessible in 5 clicks from the homepage will have less chance of being crawled than a page 2 clicks away, even if both are technically "discoverable". And that's where it gets tricky: Google gives no numerical guidance.
In what cases doesn't this rule apply fully?
Single-page applications (SPAs) or heavy JavaScript architectures are problematic. If Googlebot must wait for complete rendering to discover internal links, crawling may fail or be partial. Let's be honest: the gap between what Google says and what it does on SPAs remains huge.
Another case: sites with authentication or dynamic content. An internal link visible only after login will never be followed by Googlebot. Obvious? Yes. Yet we still see e-commerce sites hiding their product pages behind registration walls.
Practical impact and recommendations
What should you do concretely to optimize internal linking?
First, map your internal linking structure. Use Screaming Frog, Oncrawl, or Botify to identify orphaned pages and those accessible in too many clicks. The goal: no strategic page more than 3 clicks from the homepage.
Next, work on your internal link anchor text. Google uses anchor text to understand the topic of the target page. Generic anchor text like "click here" adds nothing — prefer descriptive anchors rich in keywords.
What mistakes should you absolutely avoid?
Don't multiply links from the footer or sidebar to hundreds of pages. Google detects these patterns and devalues these links. A contextual link in the body text weighs much more than a link buried in a mega-menu.
Also avoid internal redirect loops or redirect chains. Each additional hop consumes crawl budget and dilutes link equity. And don't rely solely on XML sitemap: it's just a safety net, not your main strategy.
How do you verify your site is compliant?
Audit regularly with Google Search Console: look at pages "Discovered, currently not indexed" and "Crawled, currently not indexed". If these lists explode, it's a red flag.
Also test JavaScript rendering with the URL inspection tool in GSC. Verify that internal links appear properly in the version rendered by Google, especially if you use React, Vue, or Angular.
- Identify and fix all strategic orphaned pages
- Reduce maximum click depth to 3 from the homepage
- Prioritize contextual links in main content
- Use descriptive anchor text rich in keywords
- Verify JavaScript rendering with Google's inspection tool
- Monitor "Discovered, not indexed" statuses in Search Console
- Remove unnecessary internal redirects to save crawl budget
❓ Frequently Asked Questions
Un sitemap XML peut-il remplacer les liens internes ?
Les liens en JavaScript sont-ils pris en compte par Googlebot ?
Faut-il mettre du nofollow sur les liens internes peu importants ?
Combien de liens internes maximum par page ?
Comment savoir si mes pages orphelines sont un problème ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 23/07/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.